-
01 今日内容概要
-
02 内容回顾:爬虫
-
03 内容回顾:并发和网络
-
04 Scrapy框架:起始请求定制
-
05 Scrapy框架:深度和优先级
-
06 Scrapy框架:内置代理
-
07 Scrapy框架:自定义代理
-
08 Scrapy框架:解析器
01 今日内容概要
1.1 starts_url;
1.2 下载中间件;
- 代理
1.3 解析器
1.4 爬虫中间件
- 深度
- 优先级
02 内容回顾:爬虫
2.1 Scrapy依赖Twisted
2.2 Twisted是什么以及他和requests的区别?
2.2.1 requests是一个Python实现的可以伪造浏览器发送HTTP请求的模块;——封装SOCKET发送请求;
2.2.2 Twisted是基于事件循环的异步非阻塞循环网络框架; ——封装SOCKET发送请求,单线程完成并发请求;
- 非阻塞:不等待;
- 异步:回调;
- 事件循环:不断地去轮询去检查状态;
2.3 HTTP请求的本质;
- 请求头
- 请求体
2.4 Scrapy
- 创建project
- 创建爬虫
- 启动爬虫
- response对象-text、body、request
- xpath解析器——/ // .// //div[@x = "xx"] //div/text() //div/@href .extract() .extract_first()
2.5 pipeline持久化
- pipeline的5个方法
- 爬虫中:yield Item对象
- yield Request对象
- cookie
03 内容回顾:并发和网络
3.1 OSI七层模型,TCP/IP五层模型,
3.2 三次握手和四次挥手
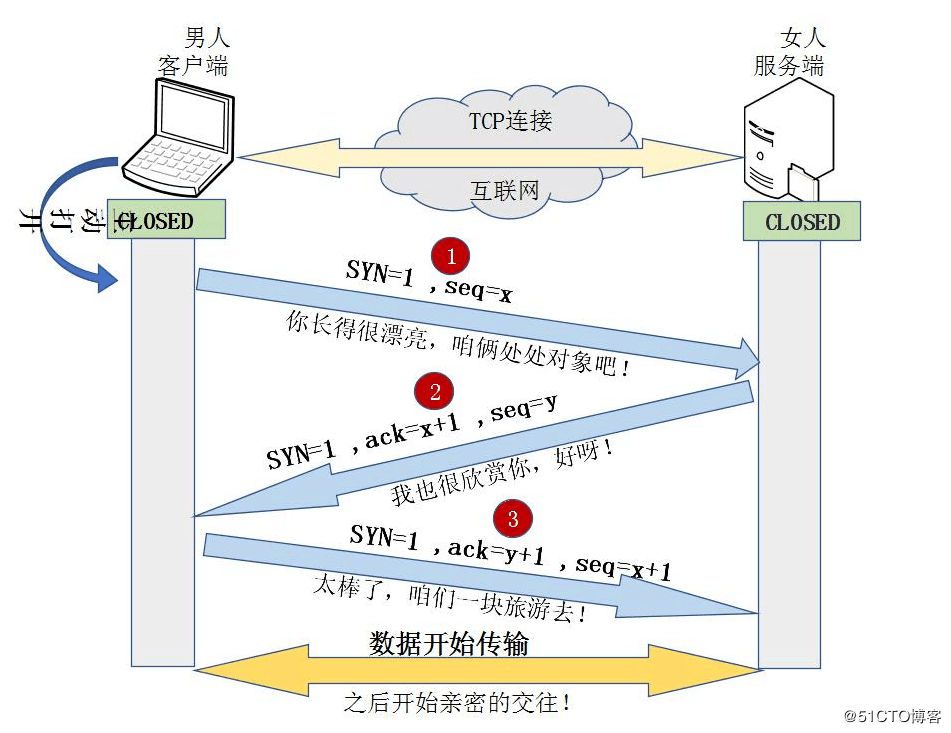
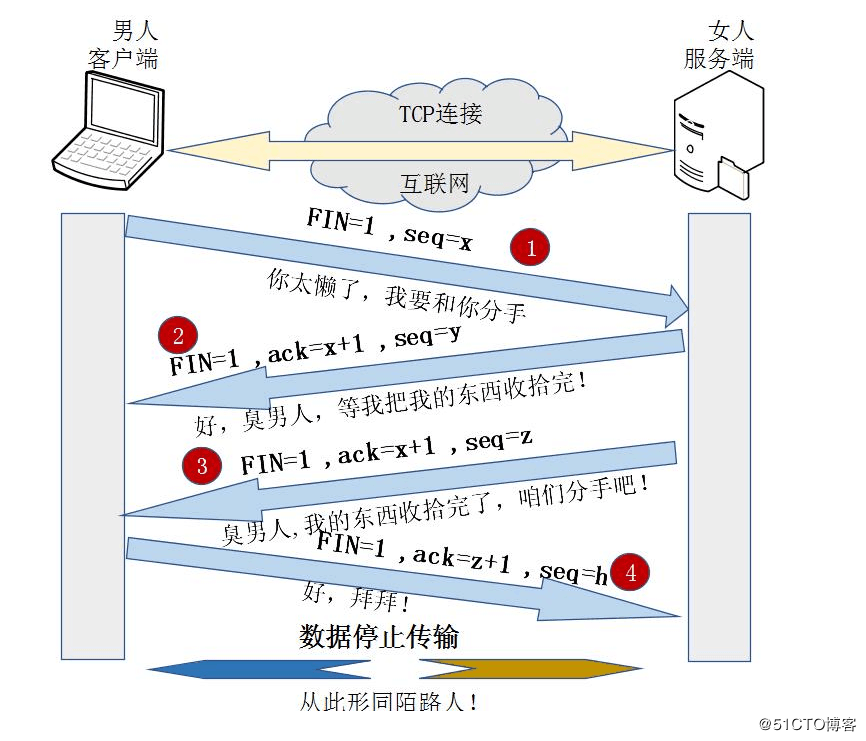
3.3 路由器和交换机的区别?
3.4 ARP协议
3.5 DNS解析
3.6 HTTP和HTTPS
3.7 进程、线程和协程的区别
3.8 GIL锁
3.9 进程如何实现进程共享?
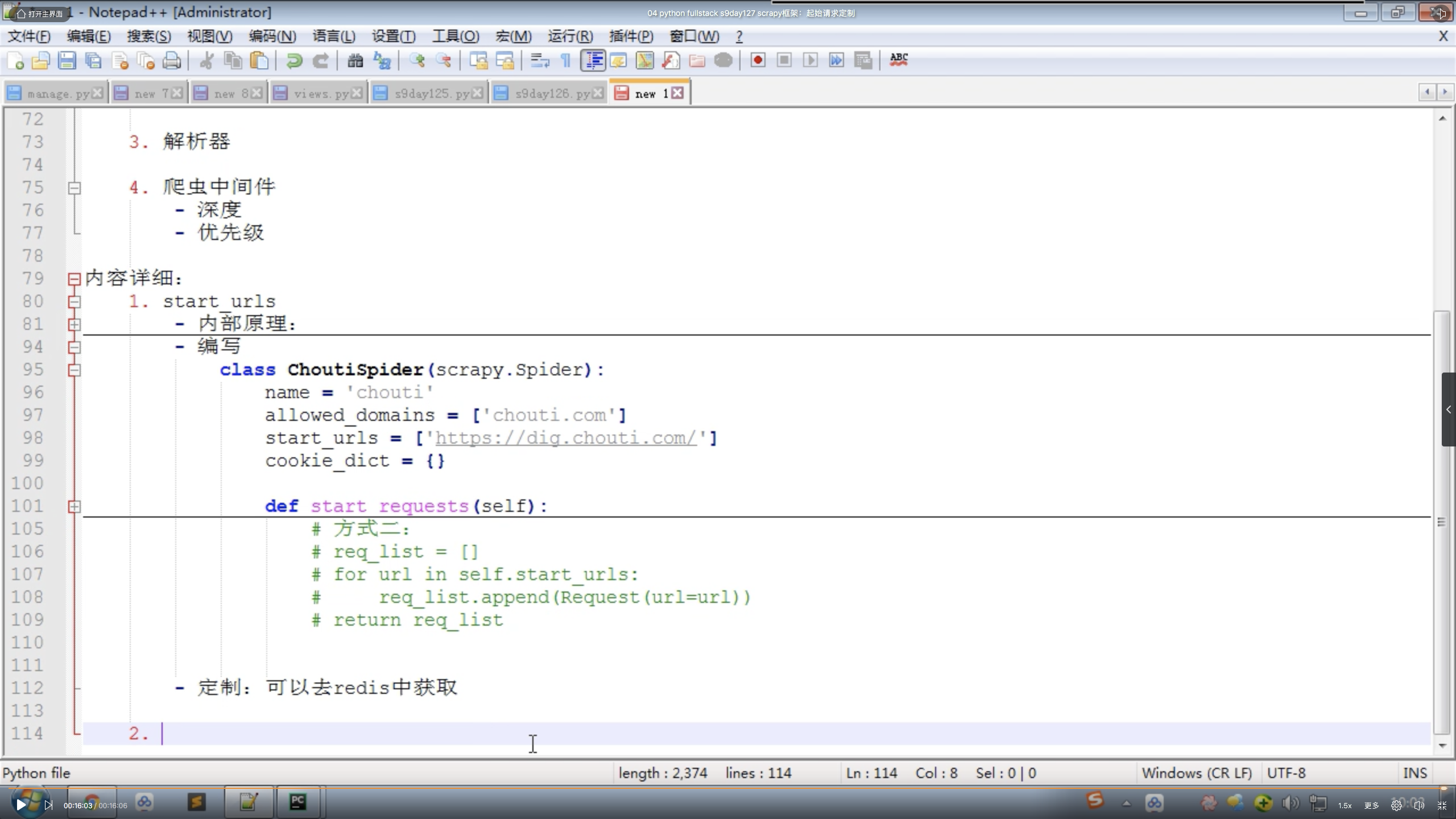
04 Scrapy框架:起始请求定制
4.1 start_urls;
4.2 什么是可迭代对象?
05 Scrapy框架:深度和优先级
5.1 深度
- 最开始是0
- 每次yield时候,会根据原来的请求中的depth + 1
- 通过配置DEPTH_LIMIT 深度控制
5.2 优先级
- 请求被下载的优先级——深度*配置 DEPTH_PRIORITY
- 配置DEPTH_PROORITY