介绍
struct模块包括一些函数,这些函数可以完成字节串与原生Python数据类型(如数字和字符串)之间的转换
函数与Struct类
struct提供了一组处理结构值的模块级函数,另外还有一个Struct类,这与处理正则表达式的compile类似。
类比正则:re.match(pattern, text) 使用这种模块级别的函数时,会先将pattern进行编译转换,这个转换是耗费资源的。因此可以先对pattern进行一个编译,comp = re.compile(pattern),comp.match(text).这样的话就只需要转换一次,struct也是类似的情况,所以创建一个Struct实例并在这个实例上调用方法时(不使用模块级函数)只完成一次转换,这会更高效
打包与解包
import struct
'''
Struct支持使用格式指示符将数据打包(packing)为字符串,另外支持从字符串解包(unpacking)数据。
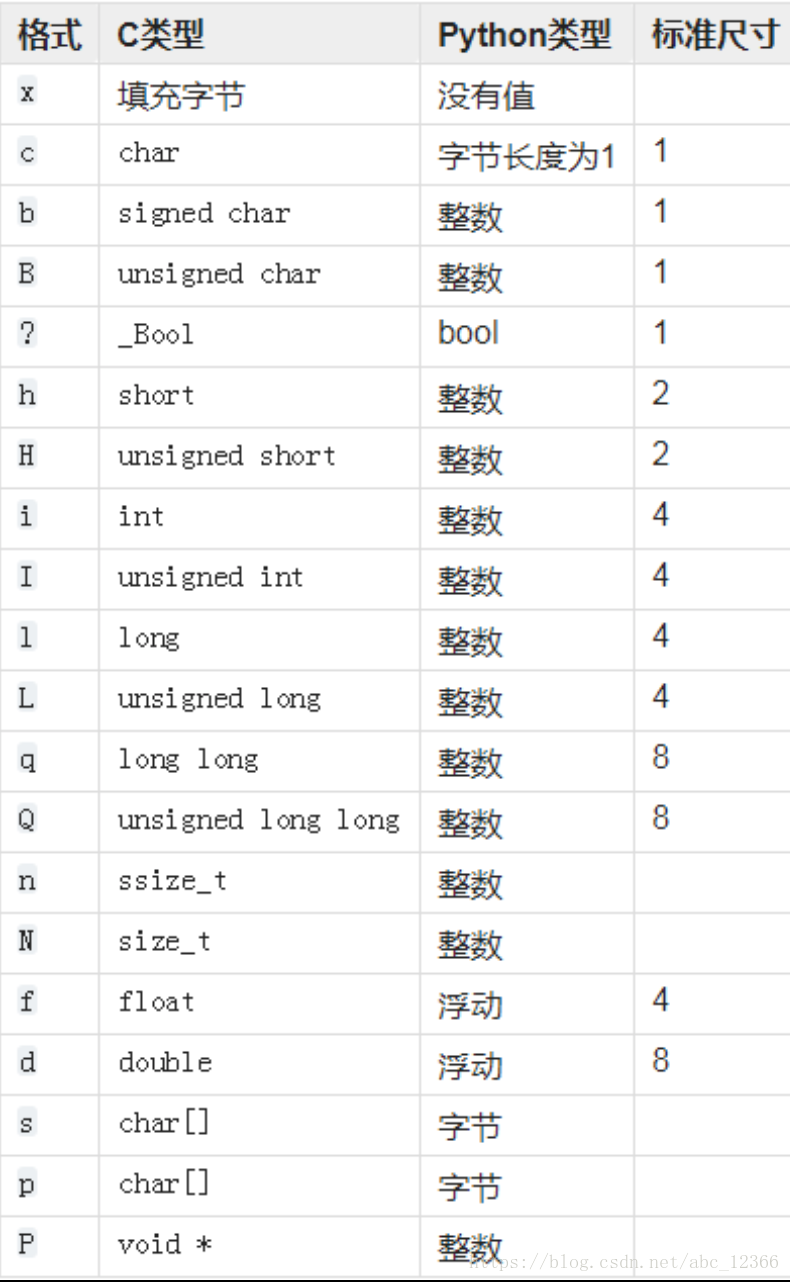
格式指示符由表示数据类型的字符和可选的数量及字节序(endianness)指示符构成。
要全面了解目前可支持的数据结构,可以参考标准库文档
'''
import binascii
# values包含一个整型或长整型,一个两字节字符串,以及一个浮点数。
values = (1, "ab".encode("utf-8"), 2.7)
# 格式指示符中包含的空格用来分割类型指示符,并且在编译格式时会被忽略
# 使用Struct定义格式,I:整型,2s:两个字节的字符,f:浮点数,之间使用空格分隔
# 表示打包的数据有三个,分别是整型,两个字节的字符,以及一个浮点
s = struct.Struct("I 2s f")
# 使用s.pack函数进行打包,将values打开传进去
packed_data = s.pack(*values) # 等价于struct.pack("I 2s f", *values)
# s:Struct对象
print(s) # <Struct object at 0x0000000002924458>
# 原始数据values
print("原始数据:", values) # 原始数据: (1, b'ab', 2.7)
# 打印一下我们的格式,也就是我们传进去的格式
print("格式化字符:", s.format) # 格式化字符: I 2s f
# 查看所用的字节
print("使用:", s.size, "bytes") # 使用: 12 bytes
# 查看打包之后的结果
print("打包后的结果:", packed_data) # 打包后的结果: b'x01x00x00x00abx00x00xcdxcc,@'
print("将打包的结果进行转换:", binascii.hexlify(packed_data)) # 将打包的结果进行转换: b'0100000061620000cdcc2c40'
# 我们传入values,通过s.pack()得到packed_data,那么我们传入packed_data,可不可以调用一个函数反过来得到values呢?
# 答案是可以的,可以使用s.unpack()
# 值得一提的是,这个binascii.hexlify,还有一个相反的函数叫做binascii.unhexlify
print(packed_data) # b'x01x00x00x00abx00x00xcdxcc,@'
print(binascii.hexlify(packed_data)) # b'0100000061620000cdcc2c40'
print(binascii.unhexlify(binascii.hexlify(packed_data))) # b'x01x00x00x00abx00x00xcdxcc,@'
# 使用s.unpack()
print(s.unpack(packed_data)) # (1, b'ab', 2.700000047683716)
'''
可以看到还是可以转回来的,注意这个浮点数啊,这是计算机的存储误差,任何语言都是有这个问题的。
'''
字节序
import struct
'''
默认地,值会使用原生C库的字节序(endianness)来编码。
只需在格式中提供一个显示的字节序指令,就可以很容易地覆盖这个默认选择
'''
import binascii
values = (1, "ab".encode("utf-8"), 2.7)
print("original values:", values)
endianness = [
("@", "native, native"),
("=", "native, standard"),
("<", "little-endian"),
(">", "big-endian"),
("!", "network")
]
for code, name in endianness:
s = struct.Struct(code + " I 2s f")
packed_data = s.pack(*values)
print("*"*20)
print("Format string: ", s.format, "for", name)
print("uses: ", s.size, "bytes")
print("hex packed data:", binascii.hexlify(packed_data))
print("unpacked data", s.unpack(packed_data))
# @:原生顺序
# =:原生标准
# <:小端
# >:大端
# !:网络顺序
'''
original values: (1, b'ab', 2.7)
********************
Format string: @ I 2s f for native, native
uses: 12 bytes
hex packed data: b'0100000061620000cdcc2c40'
unpacked data (1, b'ab', 2.700000047683716)
********************
Format string: = I 2s f for native, standard
uses: 10 bytes
hex packed data: b'010000006162cdcc2c40'
unpacked data (1, b'ab', 2.700000047683716)
********************
Format string: < I 2s f for little-endian
uses: 10 bytes
hex packed data: b'010000006162cdcc2c40'
unpacked data (1, b'ab', 2.700000047683716)
********************
Format string: > I 2s f for big-endian
uses: 10 bytes
hex packed data: b'000000016162402ccccd'
unpacked data (1, b'ab', 2.700000047683716)
********************
Format string: ! I 2s f for network
uses: 10 bytes
hex packed data: b'000000016162402ccccd'
unpacked data (1, b'ab', 2.700000047683716)
'''
缓冲区
import struct
'''
通常在强调性能的情况下,或者向扩展模块传入、传出数据时,才会处理二进制打包数据。
通过避免为每个打包结构分配一个新缓冲区所带来的开销,这些情况可以得到优化。
pack_into和unpack_from方法支持直接写入预分配的缓冲区
'''
import binascii
import ctypes
import array
s = struct.Struct("I 2s f")
values = (1, "ab".encode("utf-8"), 2.7)
print("original:", values)
print("---------------")
print("ctypes string buffer")
# 创建一个string缓存,大小为s.size
b = ctypes.create_string_buffer(s.size)
print("before:", b.raw, binascii.hexlify(b.raw))
# s.pack表示打包,s.pack_into表示打包到什么地方,至于第二个参数0表示偏移量,表示从头开始
s.pack_into(b, 0, *values)
print("after:", b.raw, binascii.hexlify(b.raw))
# s.unpack表示解包,s.unpack_from表示从什么地方解包,参数0表示偏移量,表示从头开始
print("unpacked:", s.unpack_from(b, 0))
print("---------------")
print("array")
a = array.array("b", b"�"*s.size)
print("before:", a, binascii.hexlify(a))
s.pack_into(a, 0, *values)
print("after:", binascii.hexlify(a))
print("unpacked:", s.unpack_from(a, 0))
'''
original: (1, b'ab', 2.7)
---------------
ctypes string buffer
before: b'x00x00x00x00x00x00x00x00x00x00x00x00' b'000000000000000000000000'
after: b'x01x00x00x00abx00x00xcdxcc,@' b'0100000061620000cdcc2c40'
unpacked: (1, b'ab', 2.700000047683716)
---------------
array
before: array('b', [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]) b'000000000000000000000000'
after: b'0100000061620000cdcc2c40'
unpacked: (1, b'ab', 2.700000047683716)
'''