MongoDB介绍
MongoDB是一个存储文档的非关系型数据库,它并不像mysql、Oracle那样存储结构化的数据,而是存储文档。这个文档可以看成是python中的字典,或者golang中的map。我们来和mysql对比一下。
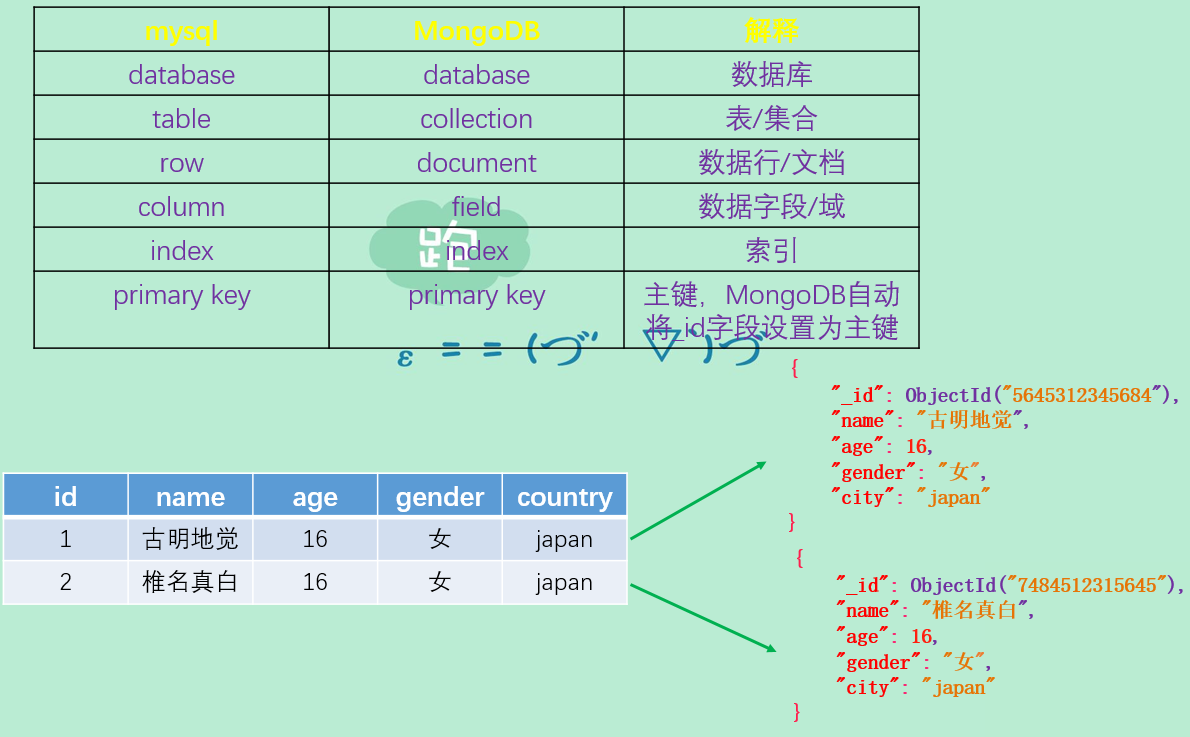
可以看到,MongoDB中的集合对应mysql中的表,表中可以有多条记录,那么一个集合里面也可以有多个文档。MongoDB的文档和mysql中的记录是对应的,这个文档格式叫做bson,它是json格式的一个扩展,我们后面会介绍。而且MongoDB还有一个最大的特点就是,同一个集合里面的文档可以有完全不同的字段,这是和关系型数据库的最大区别。同时MongoDB里面并不存在提前指定好的数据格式,如果我们需要增加一个新字段,那么只需要把包含新字段的文档写进MongoDB的集合里面就行了。
安装MongoDB
MongoDB的安装比较麻烦,但是不要怕,我们有docker,不熟悉docker的朋友可以去我之前发过的文章里面去找,尽管docker安装MongoDB很简单,但我们还是需要一些docker知识的。另外这个是在linux上运行的,Windows如何安装不讲解。
(1) 执行命令docker pull mongo:4,表示拉取MongoDB镜像,后面的:4是一个标签,表示版本是4.0的,这是比较新的版本,我们之后就学习这个最新版,其实如果不加:4,默认会拉取最新版本。
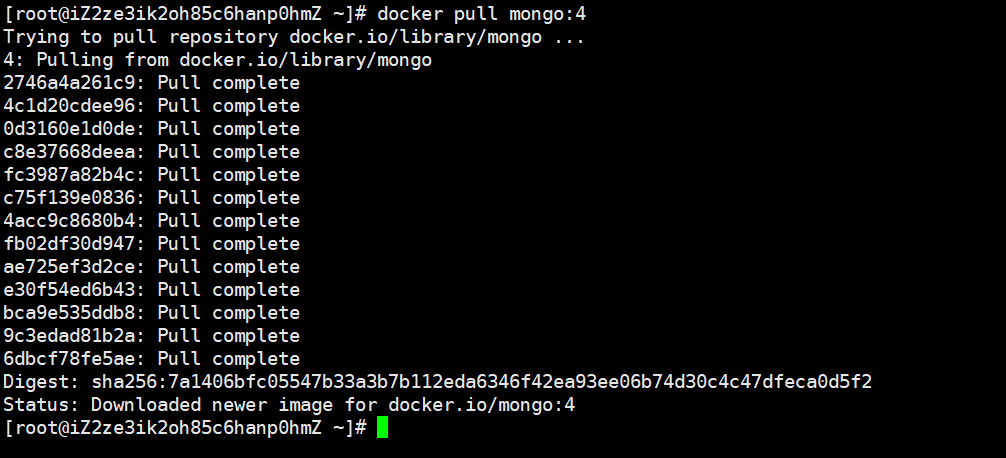
(2) 执行命令docker images,查看拉取的镜像

我们看到拉取成功,TAG表示标签,版本为4。至于上面的nginx是我之前用的,不用管它。
(3) 执行docker run --name my_mongo -v /data/mongodb_data:/data/db -d mongo:4,表示根据mongo:4镜像创建一个容器。这个命令有点长,我来解释一下,其实根据镜像创建容器,直接docker run 镜像名即可,比如我们这里docker run mongo:4即可,中间的那一大堆属于附加参数。--name my_mongo表示生成的容器名字叫做my_mongo。-v /data/mongodb_data:/data/db表示宿主机的/data/mongodb_data目录和容器的/data/db目录保持同步,/data/db是MongoDB存储数据的目录,我们让宿主机的一个目录和其保持同步,这样即使容器关闭了,我们依旧可以通过操作/data/mongodb_data来操作数据。-d表示后台运行,不然我们的xshell远程一旦关闭,服务就停了,这显然不是我们想要的结果。

此时我们/data下面是没有任何东西的,然后我们执行命令

我们看到容器已经后台启动了,并且名字就叫做my_mongo,只不过我们截图没有截全,有点长,而返回的那一大长串是容器的id,我们可以通过容器的id定位到某一个容器,有人觉得id这么长,通过id定位不是折磨人吗,所以我们才要起一个名字呀,而且id不需要全部输入,只需要输入前几位就可以了。而且我们查看/data目录,会发现mongodb_data目录已经被docker自动帮我们创建了。
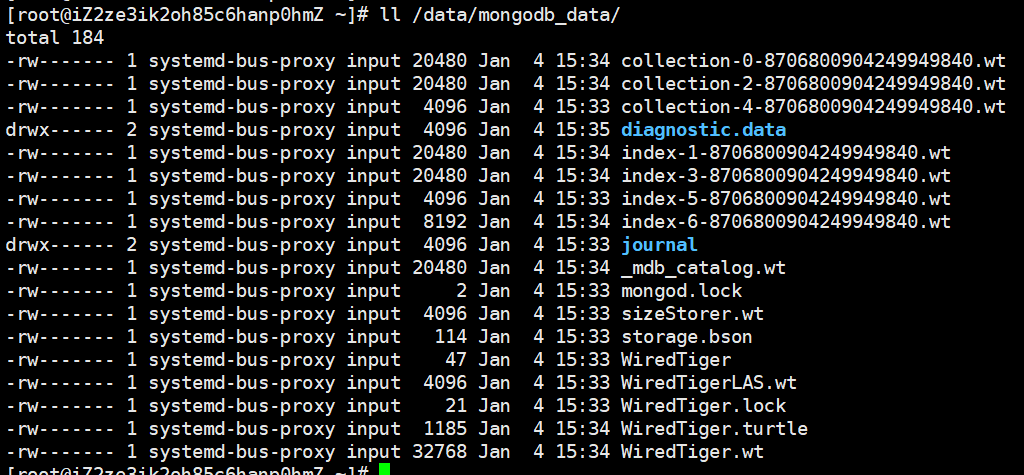
并且这个目录里面还有很多东西,这些东西哪儿来的,显然是容器的/data/db目录同步过来的,因为这两个目录是要保持一致的。如果我把宿主机的目录/data/mongodb_data里面的东西给删除了,那么显然容器里面的/data/db也空了,当然如果了解docker的话,这些都是废话。
管理MongoDB数据库
我们安装了MongoDB,那么我们肯定希望管理数据库,这个时候可以使用mongo-express,同样我们使用docker安装。docker pull mongo-express
镜像下载成功,那么我们就启动这个镜像,docker run --link my_mongo:mongo --name mongo_exp -p 8081:8081 -d mongo-express,我们看到--link my_mongo:mongo,这个选项代表我们需要使用name为my_mongo的容器,:mongo相当于起一个别名,这个选项相当于一种关联,否则mongo-exopress启动之后它管理谁啊。-p 8081:8081,第一个8081是容器暴露出来的端口,因为我们是要通过外部来访问的,需要把端口暴露出来,第二个8081是容器内部使用的端口,一个容器可以看成是一个小型的centos,那么我们在外部通过容器暴露出来的8081端口,就可以访问容器里面端口为8081的服务了,容器里面的mongo-express默认端口是8081,至于外部暴露出来的端口不是8081也无所谓,只要它指向了容器内部监听的8081,我们就能够访问到。比如-p 8088:8081也是可以的,只不过此时我们在外部就需要8088端口来访问了,但是一般两个端口是一致的。我们来执行一下命令:

启动成功,我们来通过web界面查看一下,通过8081端口。
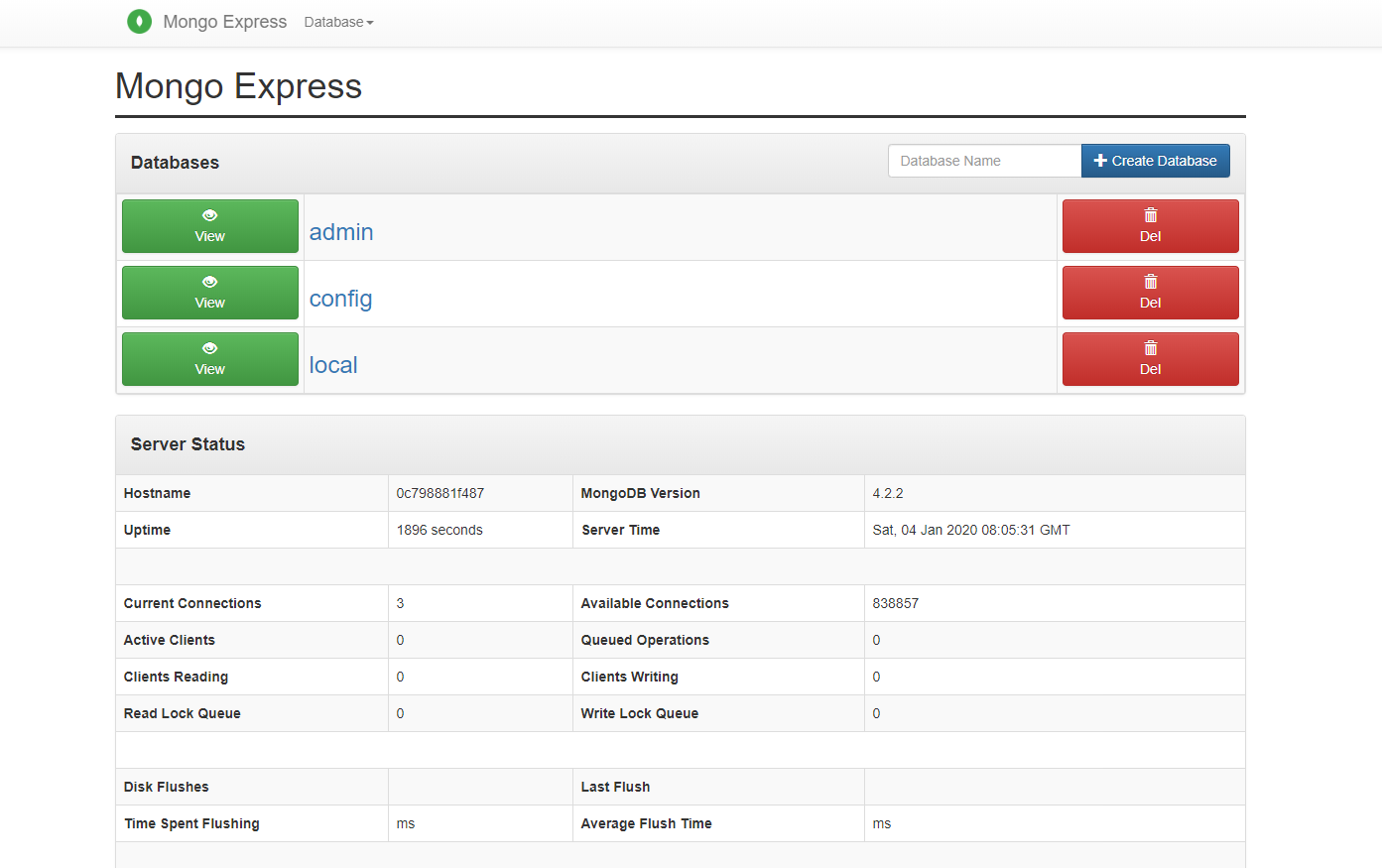
我们看到了mongo-express界面,当然前期我们并不需要操作这个,但是可以提前看一下。我们看到MongoDB默认是有admin,config,local这个三个数据库的,这三个数据库不要动,我们后面会新建数据库,然后在我们自己创建的数据库上面做操作。至于数据里面长什么样,默认有哪些collection,可以自己点击进去查看。
运行mongo shell
我们可以启动一个mongo shell,也就是交互式界面。通过docker exec -it my_mongo mongo,这里面的my_mongo就是我们之前的容器名,如果创建时不通过--name指定一个名字,那么也可以通过容器返回的id来进行启动,但是输入会不方便。
另外这个mongo shell是一个JavaScript客户端界面,就是说在mongo shell里面是可以接收js语法的。
我们看到启动成功了。
MongoDB基本操作CRUD
学习任何一个数据库都要学习C(Create)R(Read)U(Update)D(Delete),不过学习之前我们来看看一些相关概念。
文档主键_id
每个文档都有一个专属的唯一值,叫做文档主键,这个值存储在_id字段里面。这个字段是MongoDB的每一个都必备的字段,除了数组,MongoDB支持的所有数据类型都可以被当做主键。其实最方便的还是让MongoDB自动帮我们生成主键,在文档中如果不指定主键,那么MongoDB会自动帮我们生成主键,也就是对象主键(ObjectId)。这是默认的文档主键,可以快速生成的12个字节的id,而前4个字节一般是创建时间。
创建数据库
另外在MongoDB中创建一个数据库,直接使用use 数据库名即可,没有会自动创建并切换、存在则切换。
删除数据库
删除数据库则是,想删除哪个数据库就切换到哪个数据库,然后执行db.dropDatabase()即可。
创建集合
db.createCollection(name, options)
name: 要创建的集合名称,options: 可选参数, 指定有关内存大小及索引的选项
| capped | 布尔 | (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 当该值为 true 时,必须指定 size 参数。 |
| ----------- | ---- | ------------------------------------------------------------ |
| autoIndexId | 布尔 | (可选)如为 true,自动在 _id 字段创建索引。默认为 false。 |
| size | 数值 | (可选)为固定集合指定一个最大值,以千字节计(KB)。如果 capped 为 true,也需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量。 |
删除集合
切换到相应的数据库,使用db.<collection>.drop()即可,
<collection>是集合的名字
创建文档
语法:
db.<collection>.insertOne(
<document>,
{
writeConcern: <document>
}
)
<collection>是你的集合名,集合不存在会默认创建
<document>是你要写入的文档
这里面的writeConcern则定义了本次文档创建操作的安全写级别
简单来说,安全写级别用来判断一次数据库写入操作是否成功
安全写级别越高,丢失数据的风险就越低,然而写入操作的延迟也可能更高
如果不提供writeConcern,MongoDB则使用默认的安全写级别
当前不用管这个writeConcern,我们后面介绍
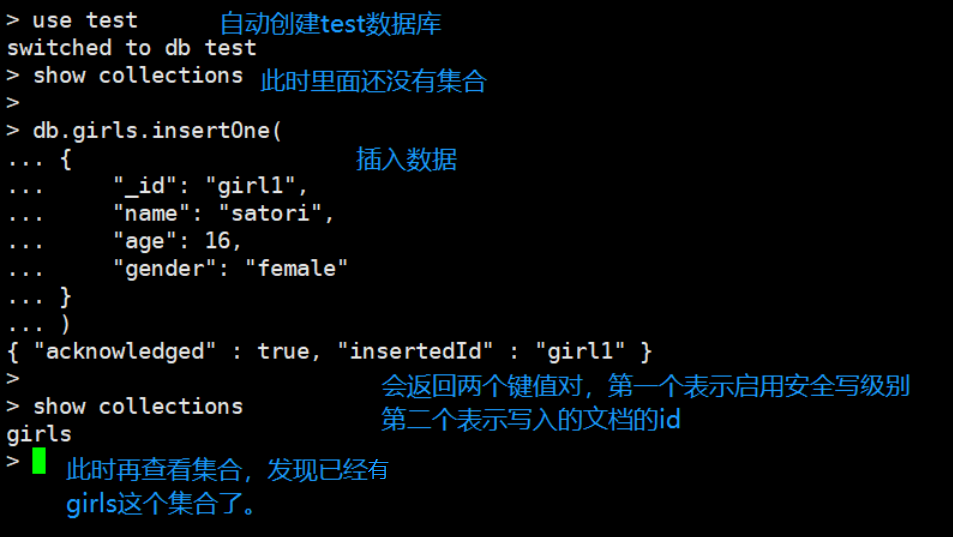
insertOne表示插入单条文档,还可以使用insertMany,插入多条文档。多个文档放在一个数组里面。
db.girls.insertMany(
[
{
"_id": "girl2", "name": "koishi",
"age": 15, "gender": "female"
},
{
"_id": "girl3", "name": "scarlet",
"age": 400, "gender": "female"
}
]
)
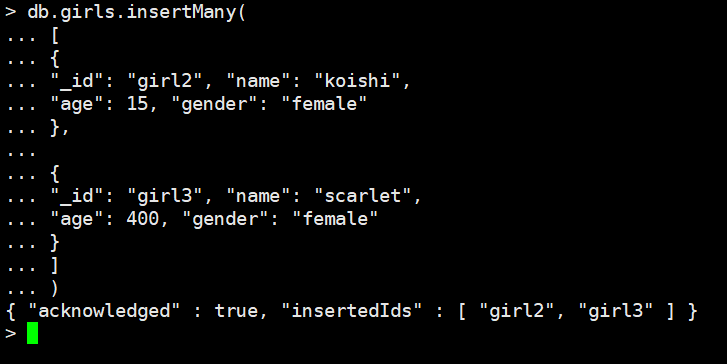
我copy的时候,格式会有点问题,但是无所谓,我们看到多条数据是可以同时插入进去的。
如果我们插入数据的时候,出现了错误怎么办?首先插入单条数据失败了,那么数据肯定不会在集合里面。但如果插入多条数据失败了呢?
db.girls.insertMany(
[
{
"_id": "girl4", "name": "tomoyo",
"age": 19, "gender": "female"
},
{
"_id": "girl4", "name": "nagisa",
"age": 21, "gender": "female"
},
{
"_id": "girl5", "name": "kurisu",
"age": 18, "gender": "female"
},
]
)
目前集合里面是有三条记录(准确来说应该叫文档,但是无所谓啦,知道我说什么就行)的,id分别为girl1,girl2,girl3
我们我们再插入三条,第一条肯定没问题,但是第二条和第一条的主键冲突了,肯定会失败,而第三条如果单独插入肯定是成功的,但是现在它在第二条后面
所以我们这里主要是想看看MongoDB的策略,如果一次插入多条,那么中间出现了失败,MongoDB会采取什么策略了。
1.遇到失败也无所谓,依旧会尝试插入所有文档,只要能成功插入,就插入进去,对应我们这里会把第一条和第三条插入进去。
2.整体是一个事务,如果当中出现错误,那么所有文档都不会插入进去,这里面三条都不会插入到集合里
3.不是事务,按照数据的顺序一个一个插入,如果遇到失败就停止,对应这里,则是只把第一条插入进去
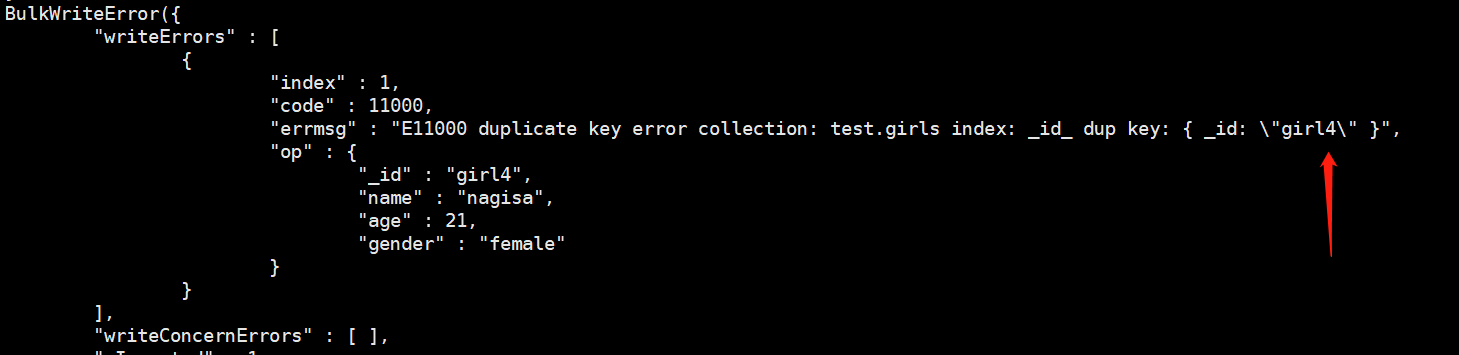
不出所料,在插入第二条的时候报错了,因为girl4这个主键已经存在了,那么其他文档呢?在这里可以使用db.girls.find()查看当前集合的所有文档

我们发现此时有4条文档,说明刚才插入的三条,只有第一条插入进去了。因此结论是第3个,按照数组里面文档的顺序依次插入文档,如果出现错误,停止插入。
更新文档
db.<collection>.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如(,)inc...)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在满足update条件的文档,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条文档,如果这个参数为true,就把按条件查出来多条文档全部更新。
- writeConcern :可选,安全写级别。
比如我们把"_id"为"girl1"的文档的name改成"mashiro"
db.girls.update({"_id": "girl1"}, {$set: {"name": "mashiro"}})
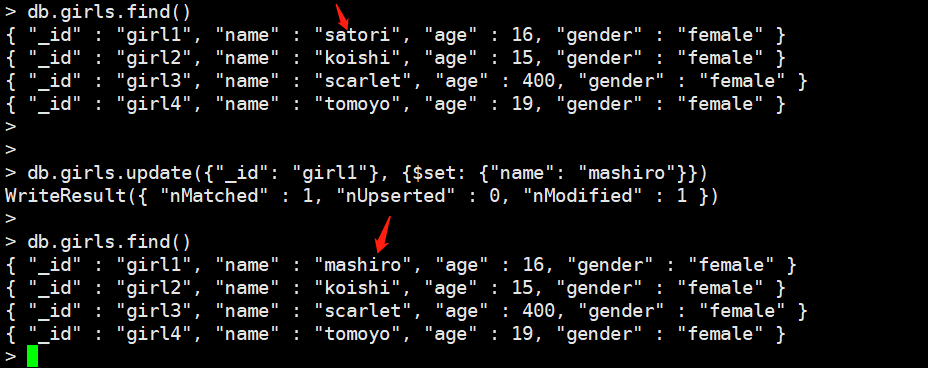
可以看到成功修改,如果有多个条件,多个修改,那么就在{}写上多个键值对即可。
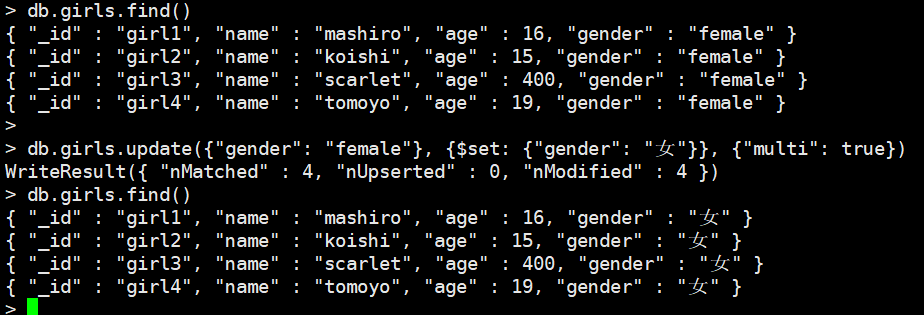
我们还可以修改多条文档
db.girls.update({"gender": "female"}, {$set: {"gender": "女"}}, {"multi": true})
不要忘记指定multi:true
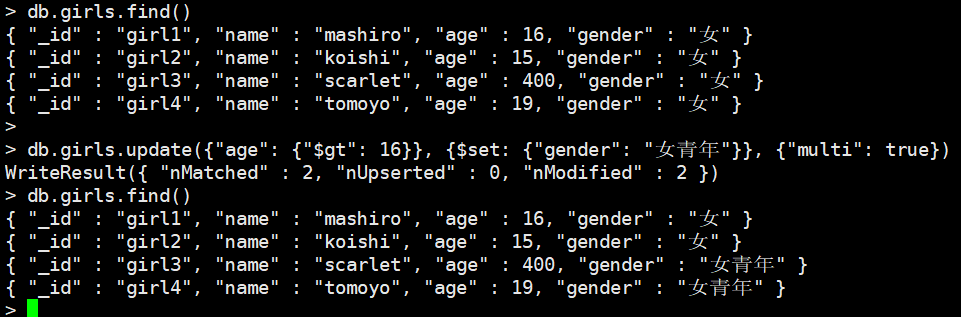
但是问题又来了,我们这里的查询条件是相当于,如果我想找大于、或者小于的怎么办?比如这里我想把age大于16的文档的gender由"女"变成"女青年"
db.girls.update({"age": {"$gt": 16}}, {$set: {"gender": "女青年"}}, {"multi": true})
我们看到如果是等于16,那么直接写16
但如果是大于16,需要再套上一层{},里面写"$gt": 16,另外别忘记multi: true
关于$gt表示MongoDB的操作符,熟悉其他语言的应该不用我说,这些操作符我们后续在查询文档的时候会一一介绍,另外"$gt"也可以写成$gt,这个引号加与不加都无所谓
除了update之外,MongoDB还提供了updateOne和updateMany两个api表示更新一条、和多条满足条件数据,这两个api的前两个参数和update是一样的,可以看做没加multi: true和加了multi: true的update。
另外MongoDB还提供了save方法,这里面传入一个文档即可,如果id存在,那么直接把整个文档替换掉。
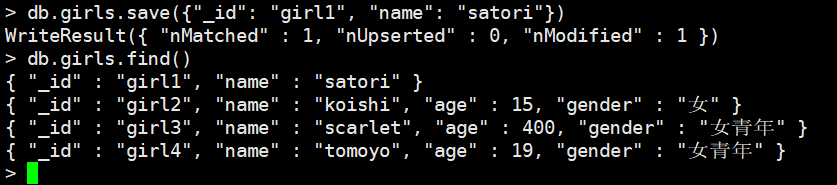
我们看到我新创建的文档,_id也叫girl1,那么直接就把原来的给换掉了,而且我们发现field不一样也无所谓。
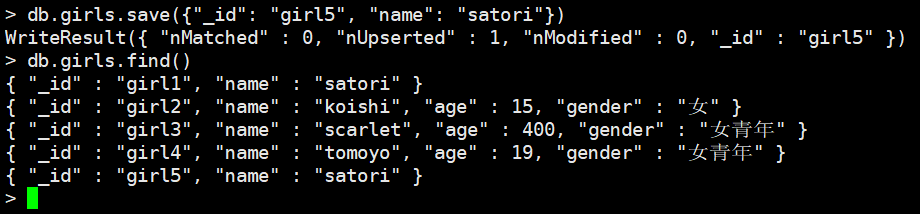
如果_id不存在,那么就创建,存在则替换。
删除文档
插入文档:insertOne、insertMany,更新文档:updateOne、updateMany,那么删除文档同样:deleteOne、deleteMany
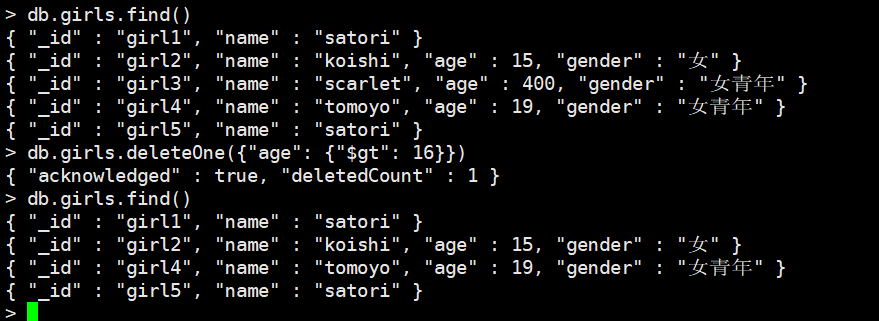
db.girls.deleteOne({"age": {"$gt": 16}})
删除第一条age大于16的数据
db.girls.deleteMany({"age": {"$gt": 10}})
删除所有age大于10的数据
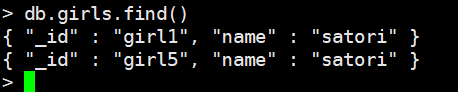
我们看到,确实大于10的全部删完了,但是对于没有age的则还保留。
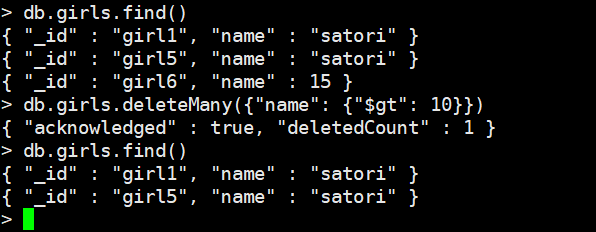
另外我们这里又插入了一条数据,name为15是一个int,可以看到,即便是同一个field,不同的文档,那么类型是可以不一样的,然后我们删除name大于10的文档。确实删掉了,但是有两个文档的name是字符串,无法比较,那么在MongoDB中,无法比较的则默认不满足条件,因此这里会保留。
查询文档
查询文档我们知道可以通过db.girls.find()来查找,这个是查找全部的文档,这里面是可以加条件的。
db.<collection>.find(query, projection)
query :可选,使用查询操作符指定查询条件
projection :可选,返回指定的field
数值比较


其余的可以自己尝试
and
如果我们指定多个条件也是可以的,比如筛选出age > 16并且gender="female"的。
db.girls.find({"age": {"$gt": 16}, "gender": "female"})
直接把两个条件写在一起即可
另外如果要查找age > 16 并且 age < 19的,不能这么写
db.girls.find({"age": {"$gt": 16}, "age": {"$lt": 19}})
应该这么写
db.girls.find({"age": {"$gt": 16, "$lt": 19}})
如果按照第一种写法的话,那么只以第二个"age": {"$lt": 19}为条件,很好理解
{"age": {"$gt": 16}, "age": {"$lt": 19}}想象成一个python中的字典,key不能重复,所以第二个就把第一个元素给覆盖了。

第一个筛选的结果就是age < 19的,第二才是age > 16 and age < 19
or
如果是or的话,那么我们就需要手动指定了,比如我们筛选age < 17 or age > 19的
db.girls.find(
{
"$or": [
{"age": {"$gt": 19}},
{"age": {"$lt": 17}}
]
}
)
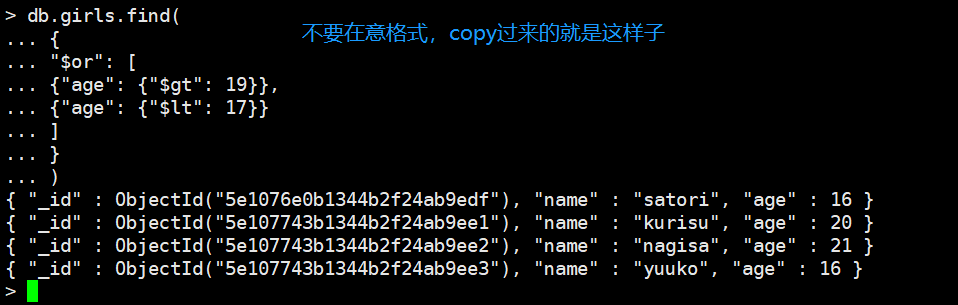
可以和and进行组合,比如我们要筛选(age < 17 or age > 19) and gender="女青年"的,这里我已经把数据给改了,增加了一个gender字段
db.girls.find(
{
"$or": [
{"age": {"$gt": 19}},
{"age": {"$lt": 17}}
],
"gender": "女青年"
}
)

如果我们要筛选(age > 16 and age < 21) or gender="女青年"的
db.girls.find(
{
$or: [
{"age": {"$gt": 16, "$lt": 21}},
{"gender": "女青年"}
]
}
)
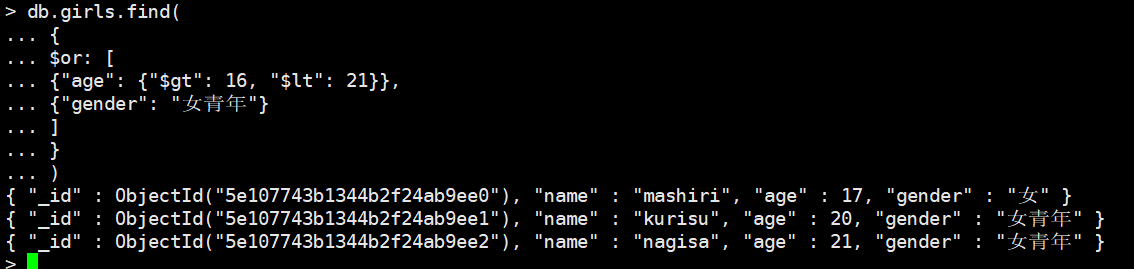
个人觉得MongoDB设计的查询方式好费劲啊
projection
db.<collection>.find(query, projection)
query :可选,使用查询操作符指定查询条件
projection :可选,返回指定的field
还记得这个projection吗?我们来演示一下
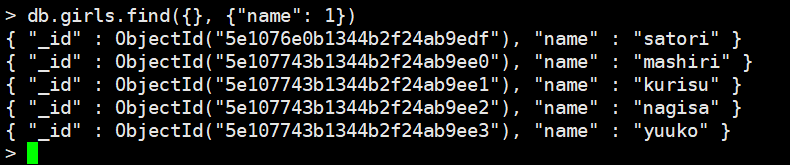
里面没有关键字参数,那么想输入projection,并且又没有查询条件的话,那么查询条件直接指定一个{}即可。我们看到指定了name:1,那么只返回_id和name,里面填指定的field,为1表示返回,为0表示不返回。注意:只能填1或者0,并且如果填入1则都要填1,填入0则都要填0。比如:
如果只返回name,那么就{"name": 1}即可,这就代表只返回name,当然还有id
不能出现{"name": 1, "age": 0}这种情况,这种情况程序员的理解是返回name不返回age,但是MongoDB认为这是不合法的语法
如果是只返回name不返回age,直接{"name": 1}即可
如果不返回age,那么就是{"age": 0},0表示不返回,那么会age给扔掉,返回其它的。总之不能既出现1又出现0,当然有一种特例,那就是id
除了id之外,projection指定的所有字段要么都是1,要么都是0。一旦指定了,只返回指定为1的,或者不返回指定为0的。
但是id是个特例,因为它是自动返回的,我们指定"name": 1,应该只返回name的,但是id、不对应该是_id,也返回了。这个时候我们可以写{"_id": 0, "name": 1},这时候就把_id也扔掉了
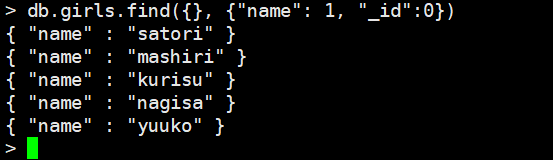
模糊查询
db.girls.find({"name": /ri/}) 查找name包含字符串ri的文档
db.girls.find({"name": /^ri/}) 查找name以字符串ri开始的文档
db.girls.find({"name": /ri$/}) 查找name以字符串ri结尾的文档
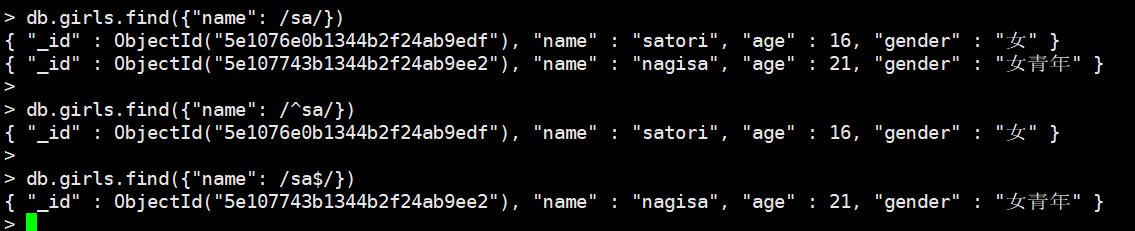
查询指定类型
我们知道MongoDB里面,不同文档的field可以有不同的类型。

如果我想筛选出,指定类型的文档怎么办呢?比如我这里要筛选出name为字符串的
db.girls.find({"name": {$type: "string"}})

limit与skip
limit就是关系型数据库的limit,skip当成是offset即可。
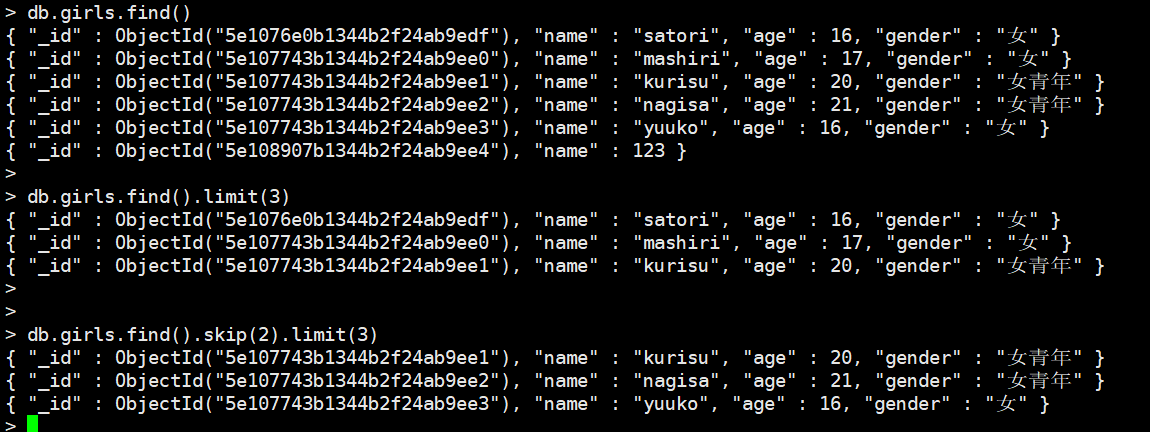
如果只有skip没有limit

sort排序
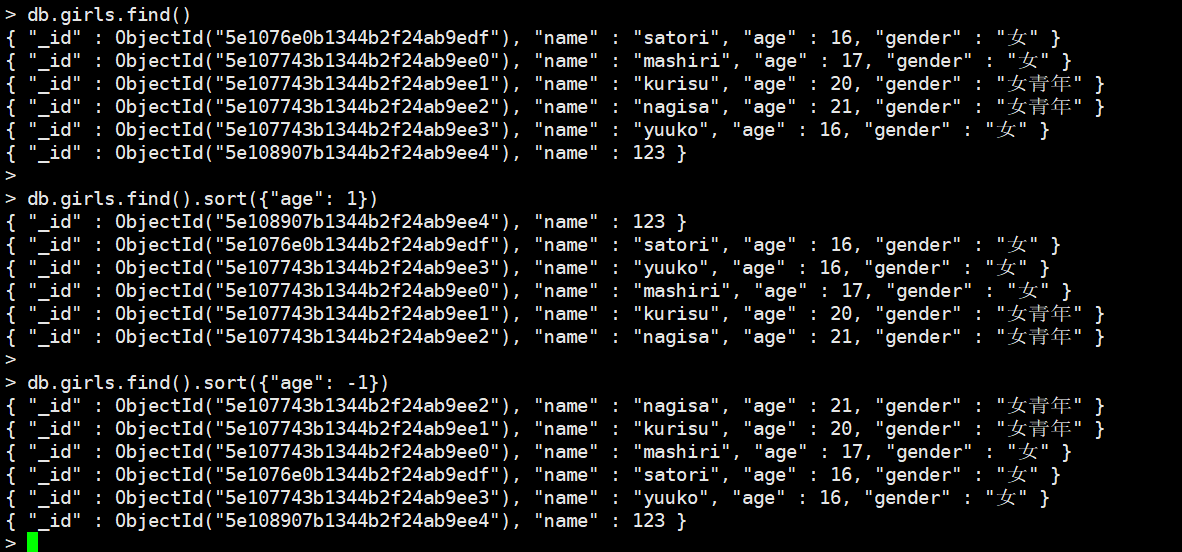
按照谁排序,就指定谁,1是正序,-1为倒序。我们注意到:如果没有相应字段、或者该字段不是整型,那么升序排,默认排最上面,倒序排默认排最下面。
有时候我们会先使用sort排序,然后再使用limit选取。这个和关系型数据库一样,先执行sort(order by),再执行skip(offset),然后执行limit(limit)。
数组操作符
我们的field除了对应字符串、整型之外,还可以是数组。
我们插入几条数据,新建一个集合。name是姓名,info是一个数组,分别是电话、薪水、国籍、爱好(也是数组)
db.boys.insertMany(
[
{"name": "boy1", info: [18538126548, 8000, "china",["篮球", "舞蹈", "音乐"]]},
{"name": "boy2", info: [12853146598, 10000, "japan",["滑冰", "舞蹈", "唱歌"]]},
{"name": "boy3", info: [11545815888, 9000, "america",["台球", "漫画"]]},
{"name": "boy4", info: [13654158865, 13000, "china",["rap", "篮球", "音乐"]]},
{"name": "boy5", info: [12541442654, 9500, "japan",["蹦极", "吸烟", "烫头"]]}
]
)
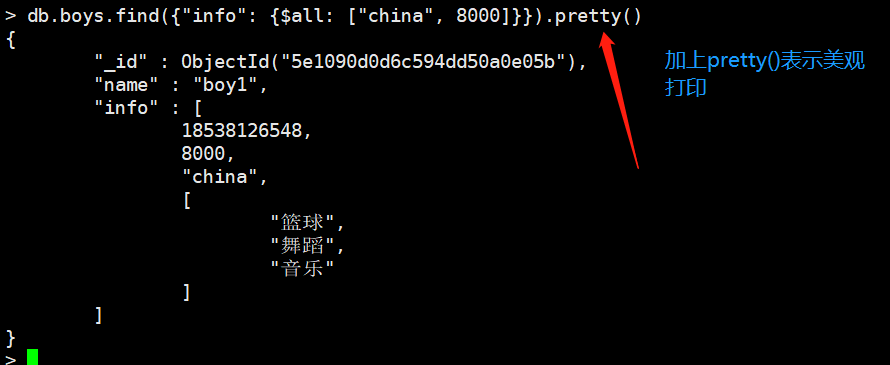
我们来查找,info中出现china和8000的。
$all操作符表示info里面必须出现"china"和8000
db.boys.find({
"info": {$all: ["china", 8000]}
})
还有$elemMatch,表示或者,
db.boys.find({
"info": {$elemMatch: {$gte: 10000, $lte: 13000}}
})
查询薪水大于等于10000并且小于13000的,不过可能有人好奇,你怎么知道这个查的是薪水,数组还有其它元素呢?
所以这是elemMatch,只要有一个元素能够满足在10000到13000之间就行,不然它怎么能表示或者呢。
所以我们发现这里面的条件明明是and,但我们却说这是"或者"。因为对于数组来说,and和or不是针对于条件来的,而是针对于数组里面的元素。
如果是all,则要求都满足。elemMatch只要数组里面有一个元素满足即可。

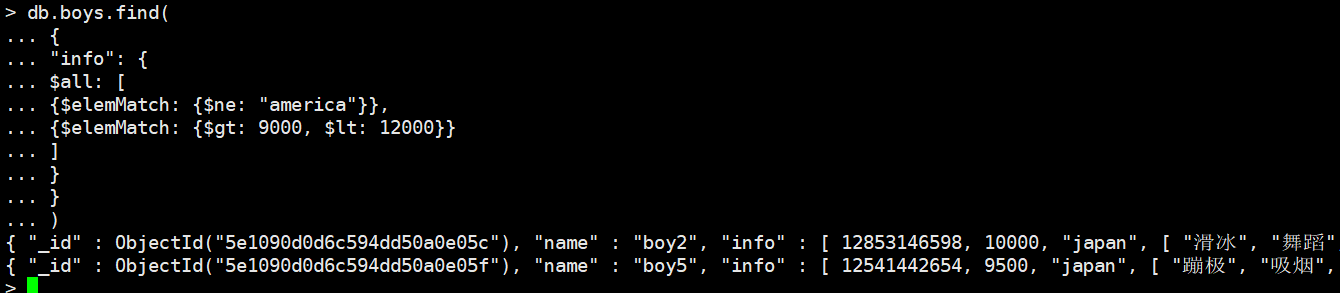
筛选出国籍不为america同时薪水大于9000小于12000的,
db.boys.find(
{
"info": {
$all: [
{$elemMatch: {$ne: "america"}},
{$elemMatch: {$gt: 9000, $lt: 12000}}
]
}
}
)
只要info里面不出现america,并且出现9000~12000的元素,那么就匹配了
in操作符
筛选出name为boy1 boy3 boy5的
db.boys.find(
{"name": {$in: ["boy1", "boy3", "boy5"]}}
)

这个in里面还可以使用正则,我们再插入几条数据。
选择name以b开头的和r开头的
db.boys.find(
{
"name": {$in: [/^b/, /^r/]}
}
)

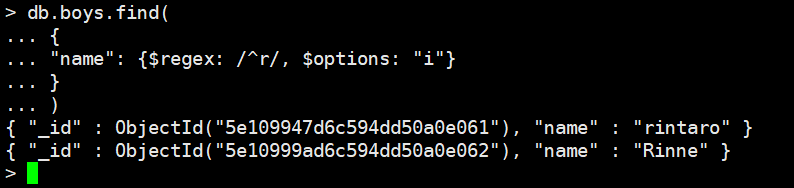
忽略大小写,/^r/ --> {$regex: /^r/, $options: "i"} i表示ignore,忽略大小写
db.boys.find(
{
"name": {$regex: /^r/, $options: "i"}
}
)
文档游标
我们之前说,db.<collection>.find()是返回所有数据,其实它返回的是一个文档迭代游标,在不遍历游标的前提下,只会列出20个文档。由于我们目前的文档数小于20个,所以就全部展示了。
既然返回了一个游标,我们可以使用一个变量将其保存起来,之前说了mongo shell是支持js语法的,按照js语法来就行。
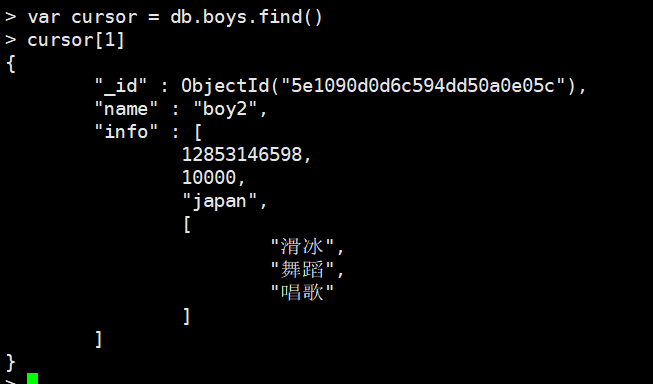
var cursor = db.boys.find()
可以使用游标的下表来获取指定文档,比如获取第二个文档
cursour[1]
当我们遍历完所有的数据,游标就会关闭,或者10分钟之后,游标会自动关闭。你可以使用var = cursor = db.boys.find().noCursorTimeout()来保证游标一致有效,不过之后当你不需要使用游标了,你需要调用cursor.close()手动关闭游标。
游标支持以下函数:
1. coursor.hasNext():当前游标的后一个位置是否还有文档,有为true,没有为false
2. cursor.next():得到下一个文档
var cursor = db.boys.find();
while (cursor.hasNext()){
print(cursor.next());
}
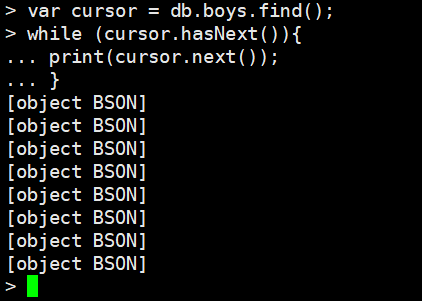
这里没有显示具体数据,而是一个bson对象,我们可以使用printjson打印,但是会比较长,我不好截图,于是就直接print了。总之知道这两个函数的作用即可。
3. cursor.forEach(<function>):对每一个文档都执行<function>函数
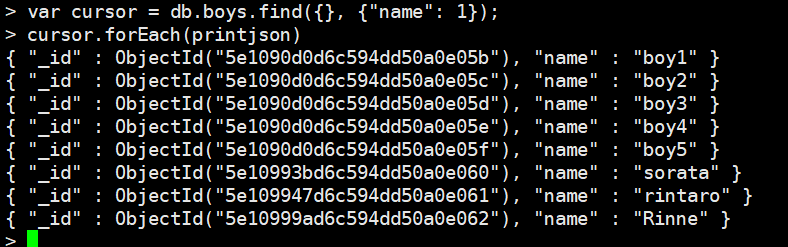
4. limit、sort、skip:之前介绍过了,另外limit(0)表示相当于没有limit,也就是全部返回
5. curosr.count():计算数量
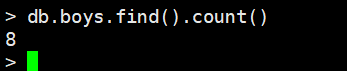
但是需要注意的是,这个count是不会考虑limit和skip的,如果指定了limit,db.boys.find().limit(3).count()这里返回的依旧是8,因为它不会考虑count,如果考虑的话,只需要在count函数里面加上参数true即可。
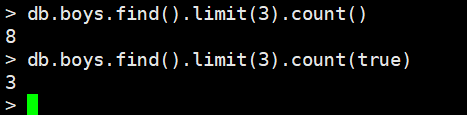
还有一点需要注意:我们这里的find没有指定筛选条件,那么count是从集合的元数据metadata中取得结果,只有当指定了筛选条件的时候,才会真正计算。所以当数据库分布式结构比较复杂的时候,元数据中文档数量可能不准确,这时候应该避免使用没有筛选条件的count,而是使用聚合管道来计算文档数量,这个聚合管道后面会介绍。
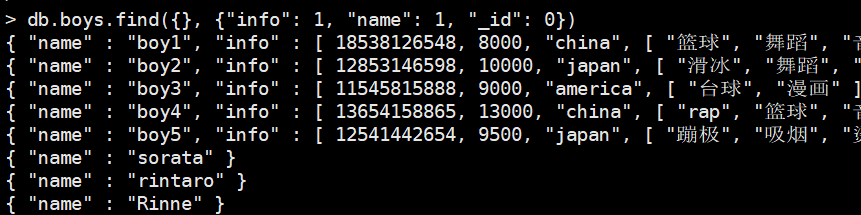
还记得我们之前说的projection吗?指定返回的字段,我们当时遗漏了一点,那就是数组。
$slide: 1表示返回数组的前1个元素
$slide: 1表示返回数组的后1个元素
$slide: [1, 3]表示跳过1个元素,返回接下来的三个元素
db.boys.find(
{},
{"name": 1, "info": {$slide: 2}, "_id": 0}
)
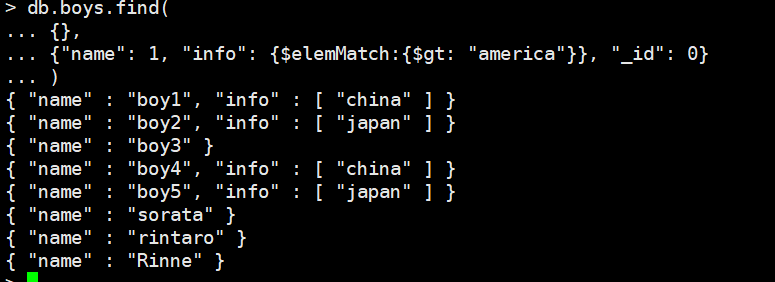
结合elemMatch,注意这里并不是"返回大于america的记录",而是全部返回,因为find第一个参数是{}
这里elemMatch指的是,数组中,大于"america"的元素返回。这里比较会按照字符的ascii码一个一个比较
db.boys.find(
{},
{"name": 1, "info": {$elemMatch:{$gt: "america"}}, "_id": 0}
)
更新文档(up)
我们之前介绍了更新文档,为什么还要介绍呢?因为文档的更新内容比较多,上面是先介绍了一部分。
如果我想更新一个数组里面的元素怎么办呢?
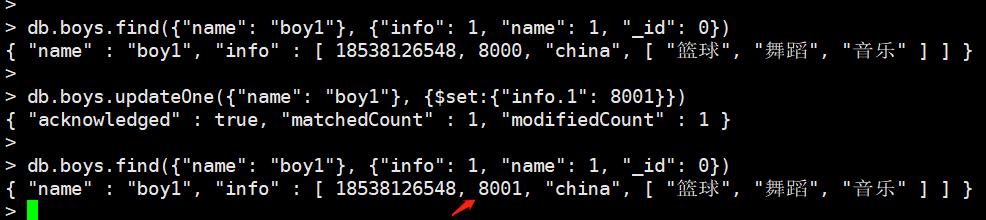
比如我们把boy1的工资由8000改成8001
db.boys.updateOne({"name": "boy1"}, {$set:{"info.1": 8001}})
我们要更新的是info里面的第二个元素,所以直接info.1即可
现在info数组里面有四个元素,因此最大索引是3,这里我们指定了4,会有什么后果
db.boys.updateOne({"name": "boy2"}, {$set:{"info.4": "yoyoyo"}})

我们看到自动追加了,那如果这里指定的不是info.4,而是info.5呢?那么索引为5的地方依旧是yoyoyo字符串,索引为4的地方则是null。因此向数组字段范围外的位置添加新值,那么数组字段的长度会扩大,未被赋值的成员将被设置为null。
unset
set表示设置值,还有一个unset表示删除值。
我们把name="boy2"的info中索引为4的"yoyoyo"给删掉
db.boys.updateOne({"name": "boy2"}, {$unset: {"info.4": ""}})

我们发现unset对于数组来说,并不是真正的删除,而是把它变为null

但是对于整个field来说,则是真的全部都删除了,并且我们似乎还给info指定了一个字符串,这个不影响,不管你指定什么都会删除,所以我们一般都写""
另外,如果使用unset的时候,指定的字段不存在,那么不会有任何影响。
rename
rename是字段重命名,如果字段存在,那么重命名,字段不存在,则不会有任何动作。

rename的原理就是unset旧字段,然后set新字段,所以我们发现它跑到后面去了。
另外如果是嵌套字段怎么办呢?
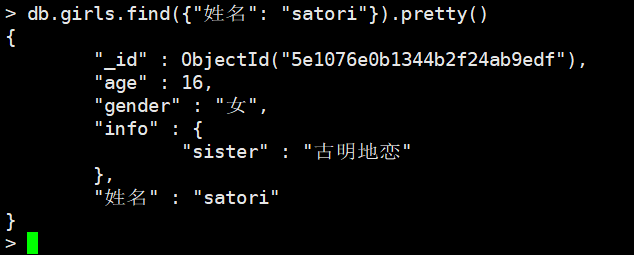
我们来做如下动作
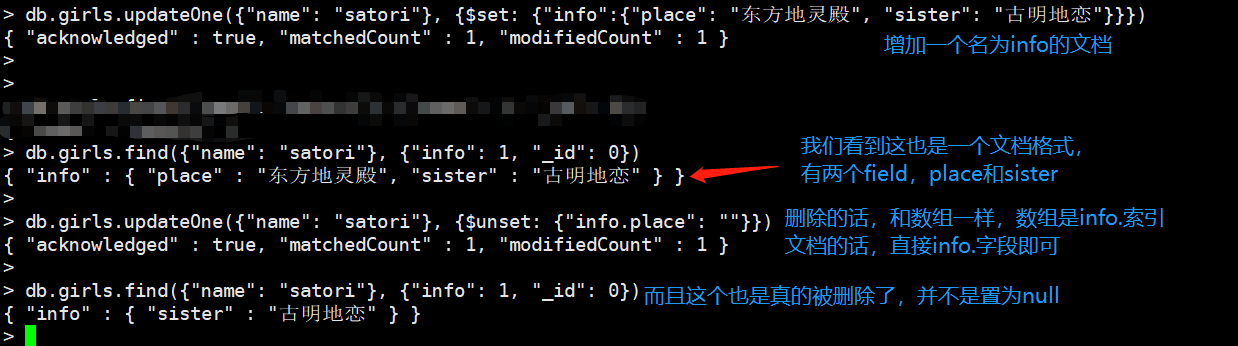
db.girls.updateOne(
{"姓名": "satori"},
{$rename: {"info.sister": "sister", "姓名": "info.姓名"}}
)
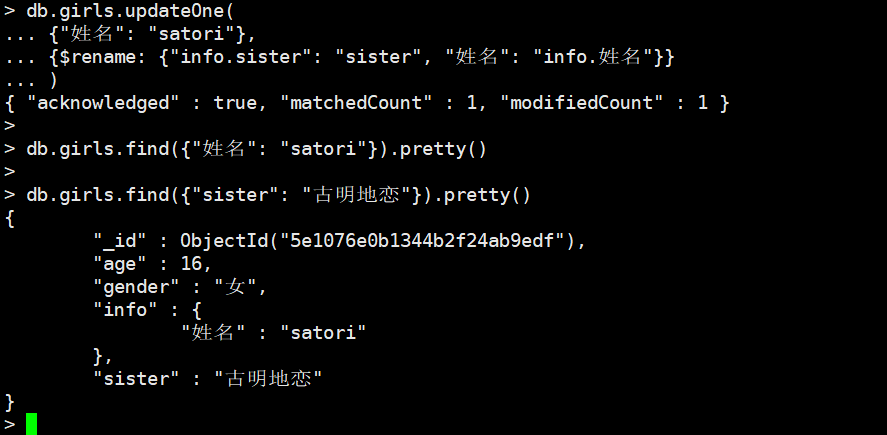
我们发现即便是嵌套字段,依旧是老规矩,info.字段的方式,我们把"info.sister"这个字段捞出来,变成了sister,把姓名这个字段捞出来变成了"info.姓名",两个字段就进行对调了。如果是数组里面的文档,是不行的,假设这里有一个名为array的数组,数组的第一个元素是个文档,文档有一个"hobby"字段,那么rename就是array.0.hobby,但是很遗憾这样不行,因为MongoDB不允许对数组里面的文档的元素进行rename,不能把外部的字段rename到数组里面的文档的某个元素,也不能把数组里面的文档的元素rename到外面。
inc
对字段增加指定的数值,可以为正、可以为负。
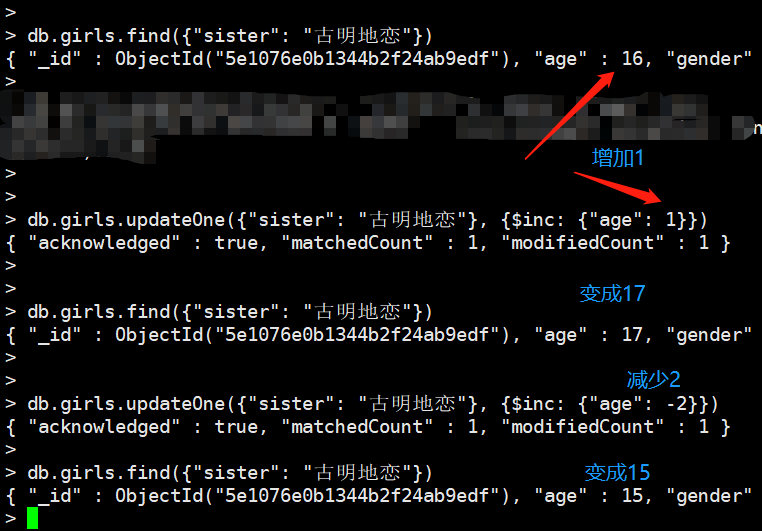
指定字段不存在,那么会创建一个新字段,而值就是0 + 指定的值,也就是原来指定要增加的值
mul
和inc类似,只不过inc是相加,mul是相乘。不再演示,但注意的是inc和mul只能应用于数据类型为整型的字段
指定字段不存在,那么会创建一个新字段,而值就是0 * 指定的值,也就是0
min、max
如果原来的age小于18,那么还是原来的值,大于18,那么改成18
db.boys.updateOne(
{"sister": "古明地觉"},
{$min: {"age": 18}}
)
如果原来的age大于18,那么还是原来的值,小于18,那么改成18
db.boys.updateOne(
{"sister": "古明地觉"},
{$max: {"age": 18}}
)
如果指定字段不存在,那么会创建新字段,字段的值就是min或者max指定的值。但是我们提供的更新值不是整型、或者说和原来的数据类型不一致,会怎么办呢?这时候MongoDB会采用类型比较,在MongoDB中类型也是有排序的
null < numbers(ints,longs,doubles,decimals) < Symbol,String < Object < Array < Bindata < ObjectId < Boolean < Date < TimeStamp < Regular Expression
更新数组
先插入一条记录
db.girls.insertOne(
{"name": "hanser", "info":["sing", ["old_driver", "baby", "little_angle"], "cast"]}
)
addToSet: 添加元素进入数组
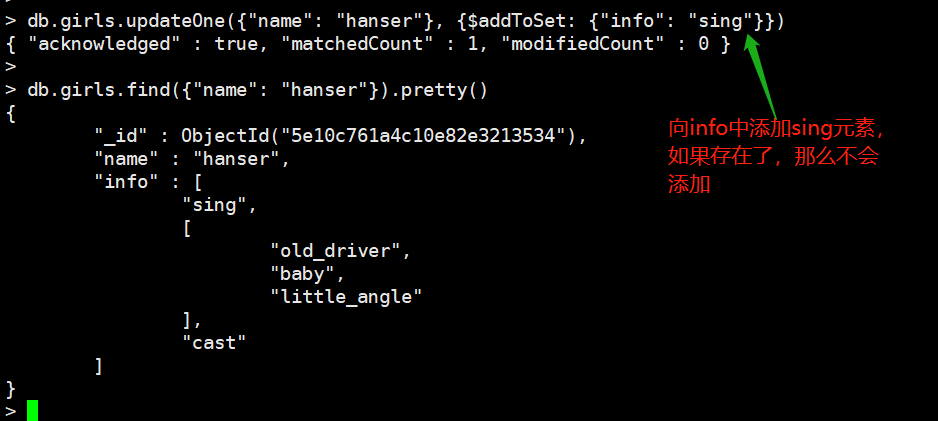
如果想插入多个元素呢?
db.girls.updateOne(
{"name": "hanser"},
{$addToSet: {"info": ["up主", "卖奶粉"]}}
)
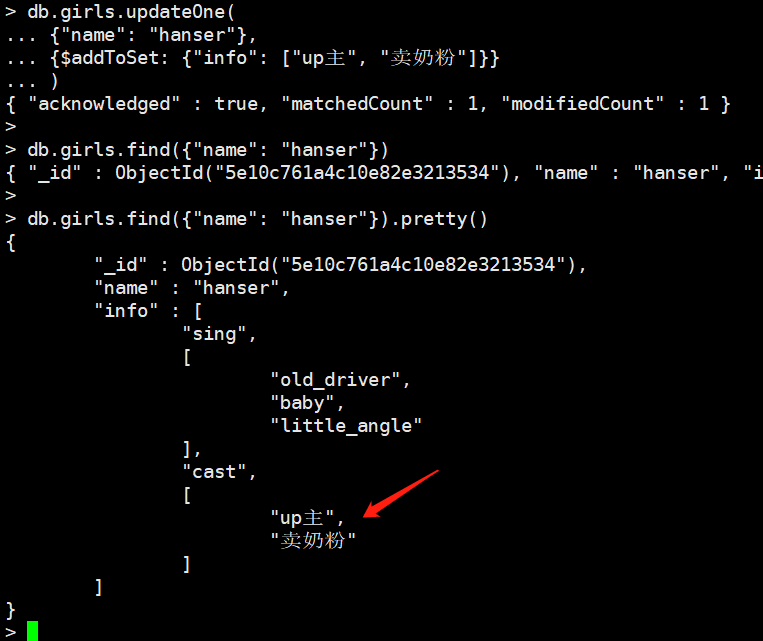
我们发现一个比较申请的地方是,它把这个列表作为一个整体插入进去了,这是MongoDB的策略,但是我们就像当成两个元素插入呢?可以使用each
db.girls.updateOne(
{"name": "hanser"},
{
$addToSet: {"info": {$each: ["up主", "卖奶粉"]}}
}
)
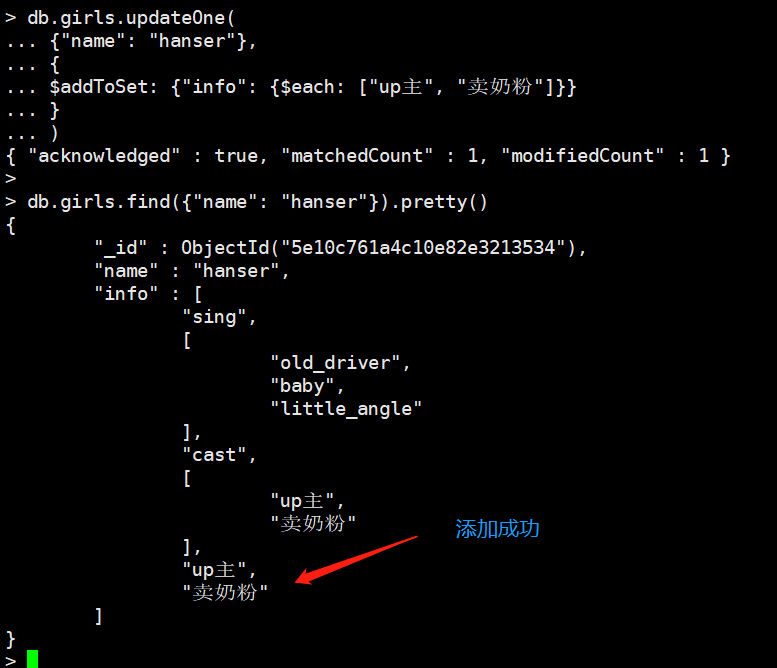
pop:删除数组的第一个或者最后一个元素
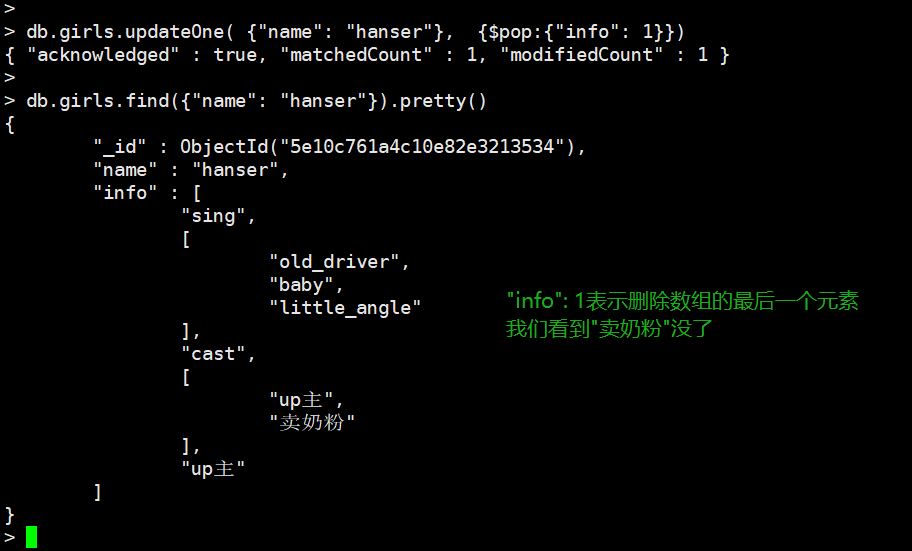
删除最后一个元素,就是-1。如果是删除数组里面的数组的某个元素,那么调用info.索引的方式
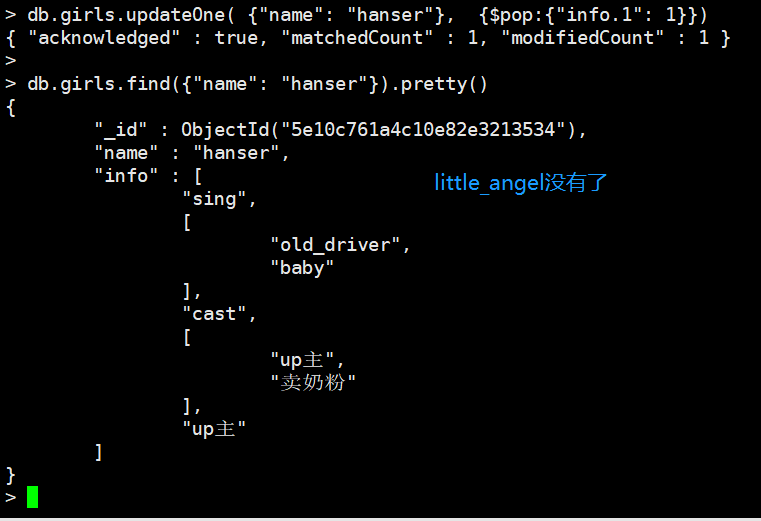
当pop掉最后一个元素时,留下空数组,并且pop只能用于数组上。
pull:删除数组的指定元素
删除以s开头的元素
db.girls.updateOne(
{"name": "hanser"},
{
$pull: {"info": /^s/}
}
)
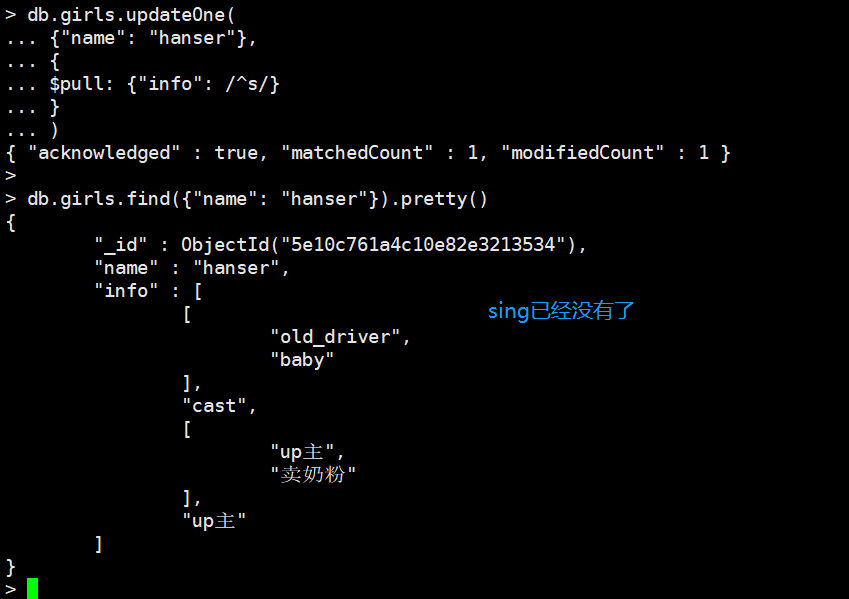
我们注意到数组里面还有两个数组,我们下面删除里面出现包含up两个字的元素的数组
我们使用了elemMatch,这个只会对里面的数组进行操作
db.girls.updateOne(
{"name": "hanser"},
{
$pull: {
"info": {$elemMatch: {$regex: /^up/}}
}
}
)
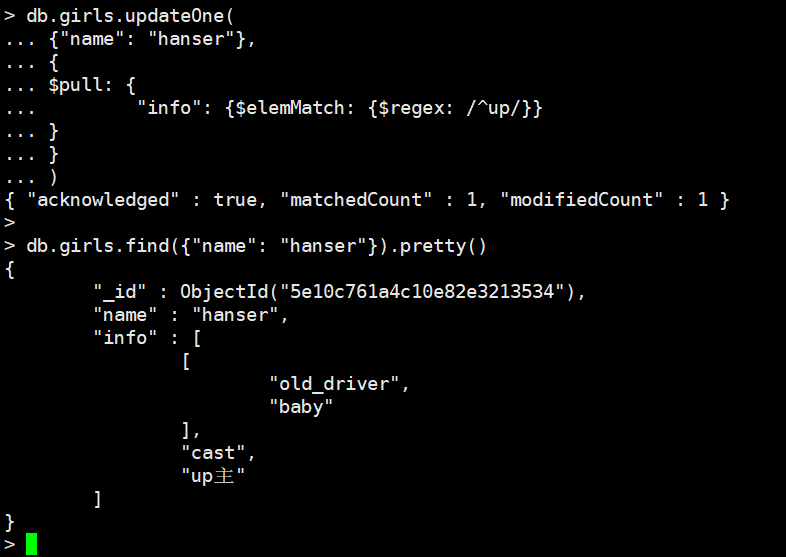
此时元素含有up的数组就被我们删掉了。
push:向数组添加元素
不管元素是否在array里面,直接添加
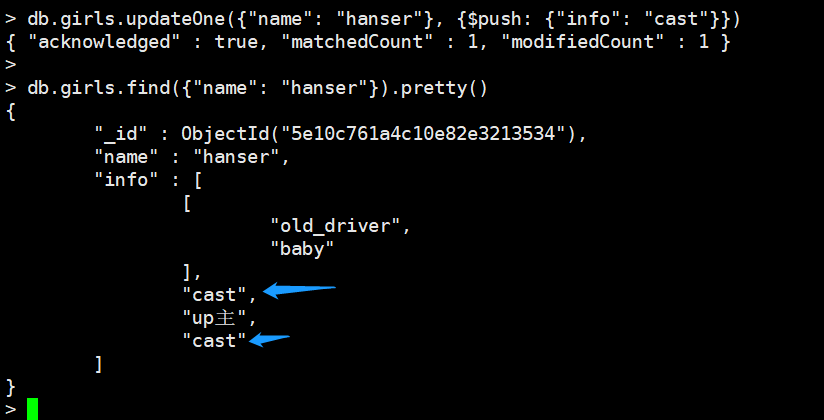
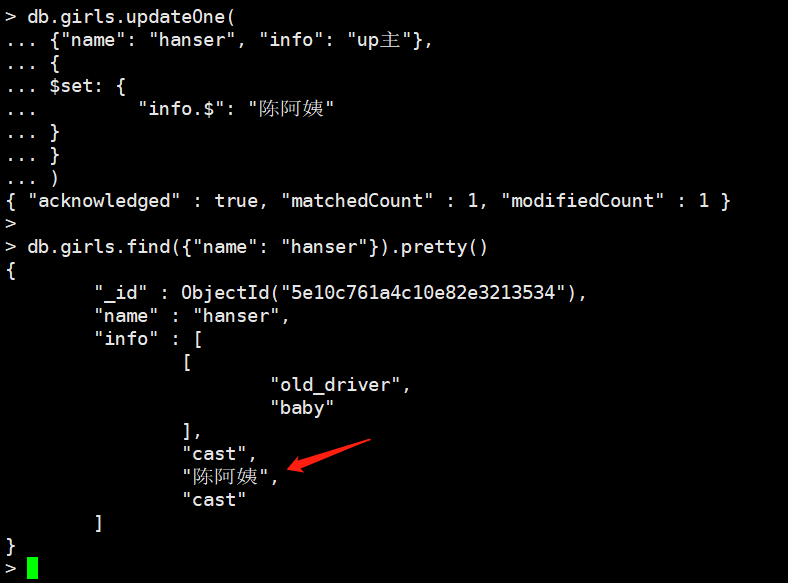
$:比较抽象,举例说明
我们看到info是一个数组,让一个数组等于一个字符串,要是通过find肯定是查找不到的
这里是为了更新做准备的。
db.girls.updateOne(
{"name": "hanser", "info": "up主"},
{
$set: {
"info.$": "陈阿姨"
}
}
)
上面的操作就会将info里面值为"up主"的元素改成"陈阿姨"
同理,如果改数组里面的数组的值呢?
这个一般是改所有值,$[]更新所有的元素
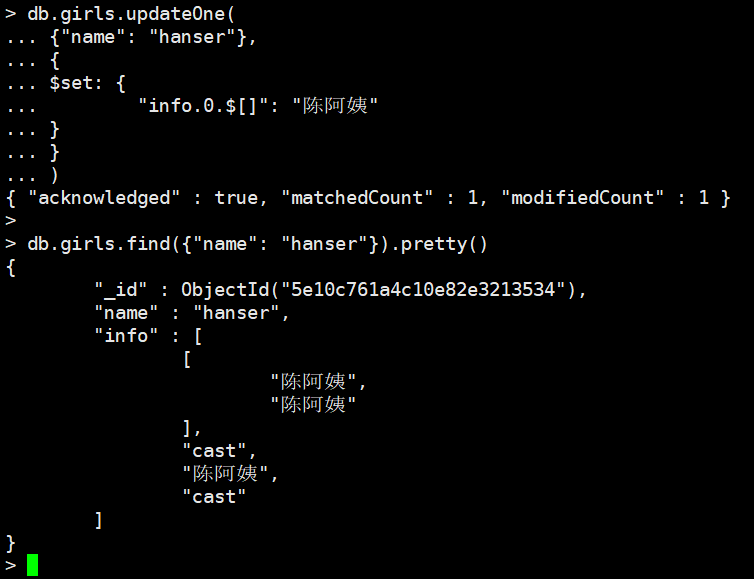
db.girls.updateOne(
{"name": "hanser"},
{
$set: {
"info.0.$[]": "陈阿姨"
}
}
)
python连接MongoDB
python连接MongoDB,使用一个模块叫做pymongo,直接pip install pymongo即可
import pymongo
client = pymongo.MongoClient(host="localhost",port=27017)
# 指定数据库
db = client["test"]
# 指定集合
collection = db["girls"]
# 插入数据,可以是一条、或者多条
# 可以用insert_one和insert_many替代
collection.insert({"name": "hanser"})
collection.insert([{"name": "hanser"}, {"name": "yousa"}])
# 查询
collection.find_one() # 返回单个
collection.find() # 返回多个
# 更新
collection.update_one()
collection.update_many()
# 删除
collection.delete_one()
collection.delete_many()
api和Mongo shell基本一致,这里不再演示
MongoDB之索引
当数据量越来越大的时候,我们一般会建立索引。比如一个集合里面有100万条文档,我现在要找到所有name="satori"的文档,如果没有索引的话,那么只能全集合扫描,如果name="satori",那么就取出来,显然这个时间复杂度就高了。
但如果我们给name字段加上了索引,那么MongoDB就会将name这个字段单独取出来进行排序(使用的数据结构为B-tree),排完序之后分别指向对应的文档,这样我在查找的时候是不是就快很多了呢?所以这是牺牲了点空间来换取时间的策略。
我们这里只是根据name来进行筛选,那么如果有多个字段呢?假设还有country、address等多个字段,那么会将字段组合起来建立联合索引,进行排序。
但是mongodb的联合索引有一个特点,假设我们后面可能会使用A、B、C这个三个字段进行查找,那么我们可以根据A、B、C这三个字段建立联合索引。虽然我们建了三个字段为联合索引,但如果只根据两个字段进行筛选呢?根据A,AB,ABC筛选,索引都能发挥作用,但是根据B,C,BC筛选不行,也就是必须以A开始,也就是联合索引的第一个字段开始,这是MongoDB对索引采取的特点。因此建立索引一定要根据集合里面数据或者文档的结构,否则的话,建立的就不是一个好索引。
关于所以的更多特点我们下面介绍
索引相关操作
创建索引
db.<collection>.createIndex({"name": 1})
此时我们就创建了一个索引,里面1表示正向排序,-1表示逆向排序
另外如果创建的索引只根据一个字段,那么这个索引称之为单建索引
根据多个字段创建的索引叫做复合键索引
还有多键索引,这个是针对数组的,会把数组中每一个元素,都会在多建索引中创建一个键
另外集合中有一个默认的索引,是针对与_id的,这个是MongoDB自动创建的
查看索引
db.<collection>.getIndexes()
测试索引效果
db.<collection>.explain().find({...: ...})
我们可以调用find函数,当然还可以调用其他的方法,比如sort等等
只是说我们在前面加上了一个explain(),这样的话MongoDB就会打印出执行时候的具体细节
删除索引
在MongoDB中没有所谓的更新索引,如果要更新某些字段上已经创建的索引
那么必须先删除原索引,然后重新创建索引。
否则新索引不会包含原有文档
db.<collection>.dropIndex(index_name)
删除索引有两种方式,一种是传入索引名,这个通过getIndexes()返回的name字段可以查看
还有一种方式是通过索引的定义删除
db.<collection>.createIndex({"name": 1, "age": -1})我们定义了这个索引假设叫name_1_age_1
那么删除索引的时候除了可以把这个索引名称传进去,还可以传入索引的定义
db.<collection>.dropIndex({"name": 1, "age": -1})
创建索引的第二个参数
db.<collection>.createIndex({"name": 1}, {})
这里面还有第二个参数,叫做options,来描述索引的特性的
db.<collection>.createIndex({"name": 1}, {"unique": true})
这就表示把name作为索引,但是还要求写入集合的所有文档的name都是不同的。
如果已经存在了相同的name呢?那么MongoDB就不会允许在name创建唯一性索引,会失败
如果我们新增的文档,里面没有name,那么MongoDB会默认添加一个name,并且值为null,但只能写入一次
如果再来一篇没有name的文档,那么MongoDB依旧会默认添加一个name,并且值为null,那么此时就重复了
此外还可以设置索引的过期时间
db.<collection>.createIndex({"name": 1}, {"expireAfterSeconds": 20})
那么20s之后,这个索引就过期了
MongoDB之聚合
先来看看MongoDB支持哪些聚合函数。
$sum:计算总和$avg:计算平均值$min:获取所有文档对应值的最小值$max:获取所有文档对应值的最大值$push:在结果文档中插入值到数组中$addToSet:在结果文档中插入值到数组中,存在则不添加$first:根据排序,获取文档的第一个数据$last:根据排序,获取文档的最后一个数据
下面我们演示一下sum
创建数据集
db.students.insertMany(
[
{"name": "satori", "age": 16, "score": 90},
{"name": "mashiro", "age": 16, "score": 86},
{"name": "kurisu", "age": 20, "score": 90},
{"name": "koishi", "age": 16, "score": 86},
{"name": "tomoyo", "age": 18, "score": 90},
{"name": "nagisa", "age": 20, "score": 90}
]
)
sum
select age, count(score) as count_score from t group by age
==>
db.students.aggregate(
[
{$group: {"_id": "$age", "count_score": {$sum: "$score"}}}
]
)
字段要加上$,聚合的字段必须起名为_id,
"count_score": {$sum: "$score"},count_score相当于起了一个别名
我们貌似没有看到count啊,sum可以实现count的效果
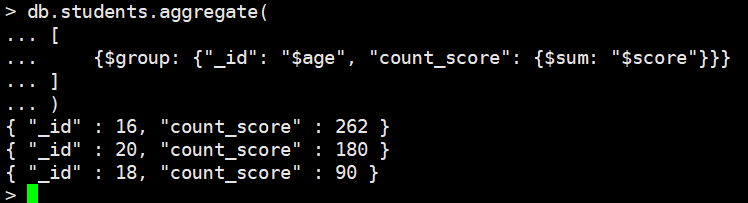
db.students.aggregate(
[
{$group: {"_id": "$age", "count_score": {$sum: 1}}}
]
)
$sum不指定字段,指定1即可,会计算每个相同的age出现的次数
db.students.aggregate(
[
{$group: {"_id": null, "count_score": {$sum: 1}}}
]
)
_id指定为null,表示不根据某个字段聚合,那么求出的就是整个集合的文档数量
如果根据两个字段聚合怎么办?难道都叫"_id"?
db.students.aggregate(
[
{$group: {"_id": {"age": "$age", "score": "$score"}, "count_name": {$sum: 1}}}
]
)
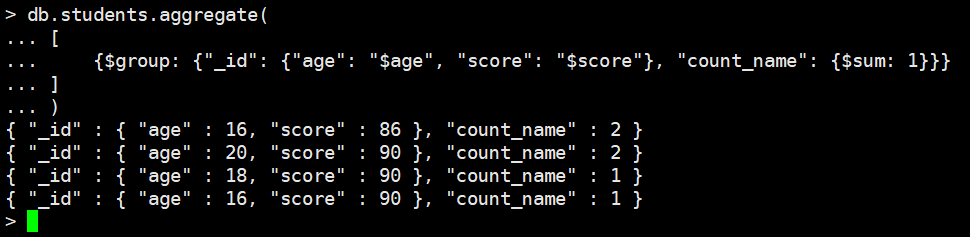
这就是MongoDB,个人觉得设计的真是奇葩。
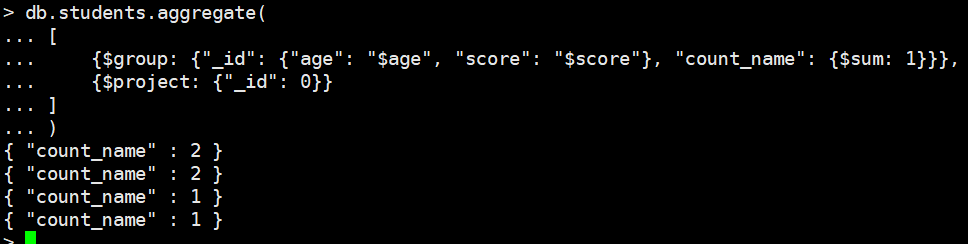
project
返回的时候不想返回_id
db.students.aggregate(
[
{$group: {"_id": {"age": "$age", "score": "$score"}, "count_name": {$sum: 1}}},
{$project: {"_id": 0}}
]
)
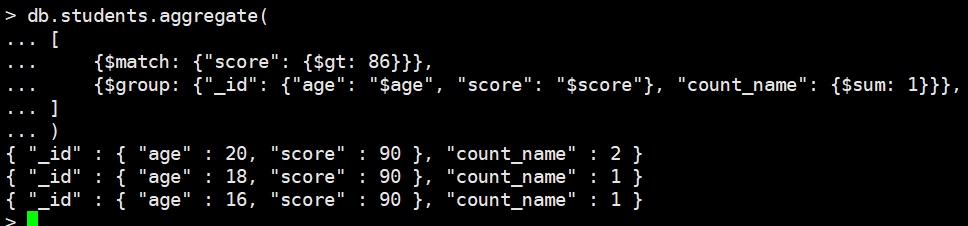
match
选出score > 86的,然后进行聚合
这个相当于mysql中的where是在where条件之后再进行聚合
db.students.aggregate(
[
{$match: {"score": {$gt: 86}}},
{$group: {"_id": {"age": "$age", "score": "$score"}, "count_name": {$sum: 1}}},
]
)
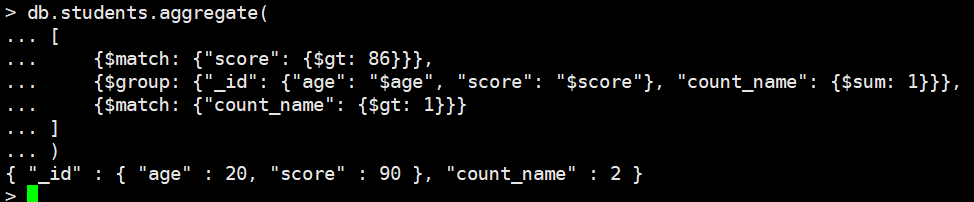
如果想返回count_name大于1的,怎么办呢?
db.students.aggregate(
[
{$match: {"score": {$gt: 86}}},
{$group: {"_id": {"age": "$age", "score": "$score"}, "count_name": {$sum: 1}}},
{$match: {"count_name": {$gt: 1}}}
]
)
在group底下再加上一个match即可,这个相当于mysql的having
这个aggregate函数类似于一个管道的,接收一个数组,依次执行数组里面的每一个操作
sort、skip、limit
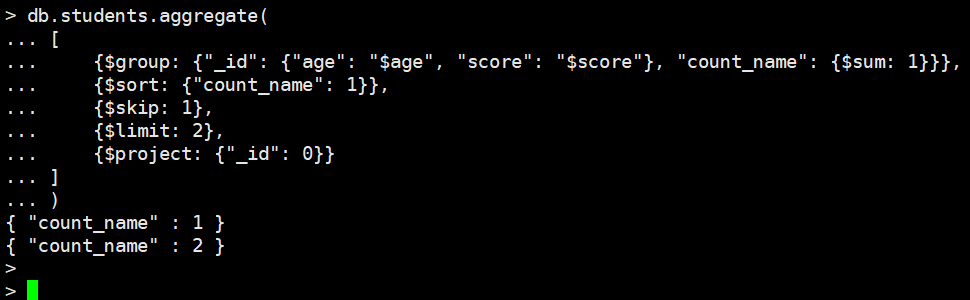
db.students.aggregate(
[
{$group: {"_id": {"age": "$age", "score": "$score"}, "count_name": {$sum: 1}}},
{$sort: {"count_name": 1}},
{$skip: 1},
{$limit: 2},
{$project: {"_id": 0}}
]
)
其余的可以自己尝试