本章主要介绍一点机器学习的基础知识以及KNN算法
一.基础知识
监督式学习 supervised:提供已知输出的数据
无监督式学习 unsupervised:提供数据但不提供输出
监督式学习常用有两种算法:线性回归 regression和分类 classification
应用监督式学习基本上有如下模型
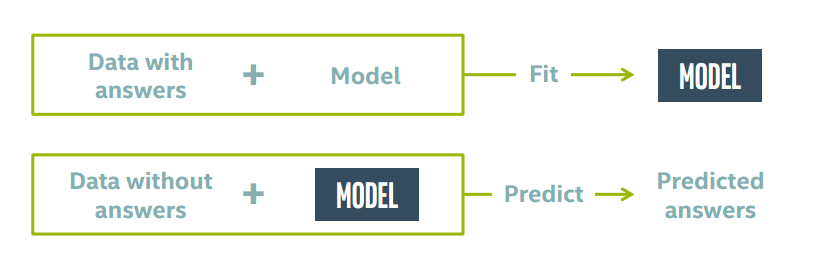
即先提供包含答案的数据训练模型,然后再用训练后的模型去预测未知答案的数据
二.术语约定
target 目标:即想要预测的数据的类型的值
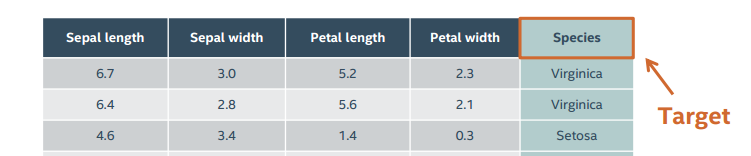
features 特征:用来预测的数据,我们在预测时要先把对象的特征抽象成数据,然后输入模型

example 样例:数据集中的一个样例,一行
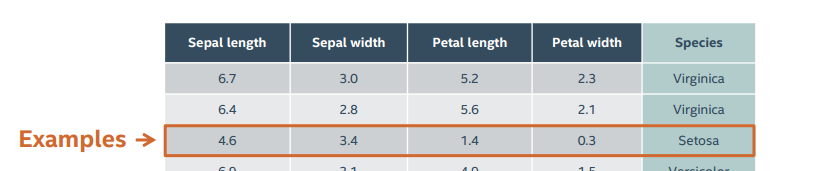
label 标签:对于一个样例的标签

三.KNN k近邻算法
1.进行分类我们需要些什么
(1)可以被定量的特征
(2)已知的标签
(3)测量相似度的方法
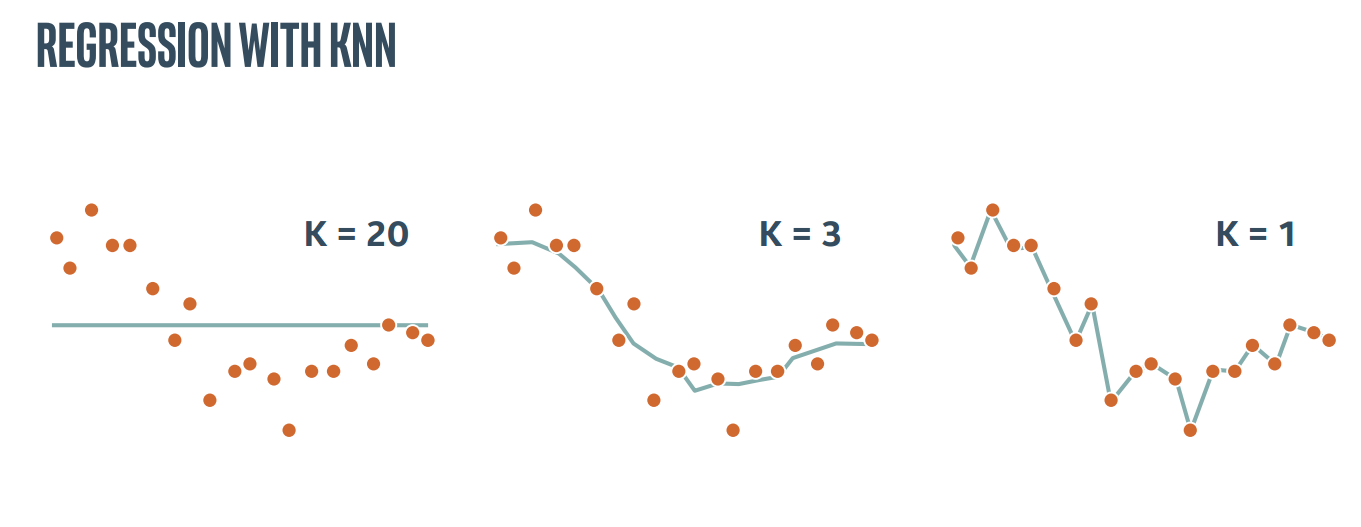
2.图解KNN
直接上PPT截图了。。这里这里主要表现K近邻中的参数K的作用
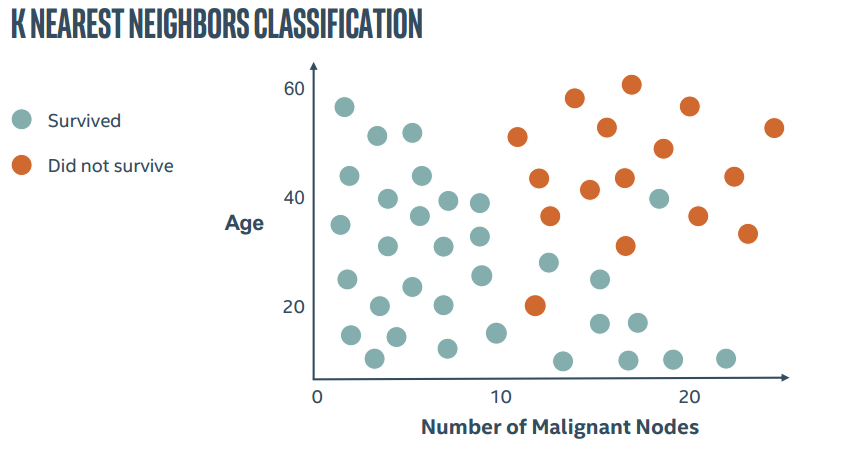
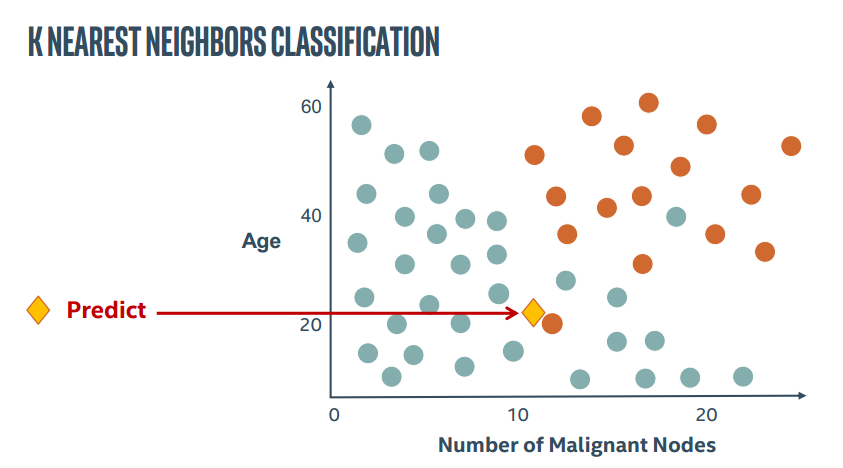
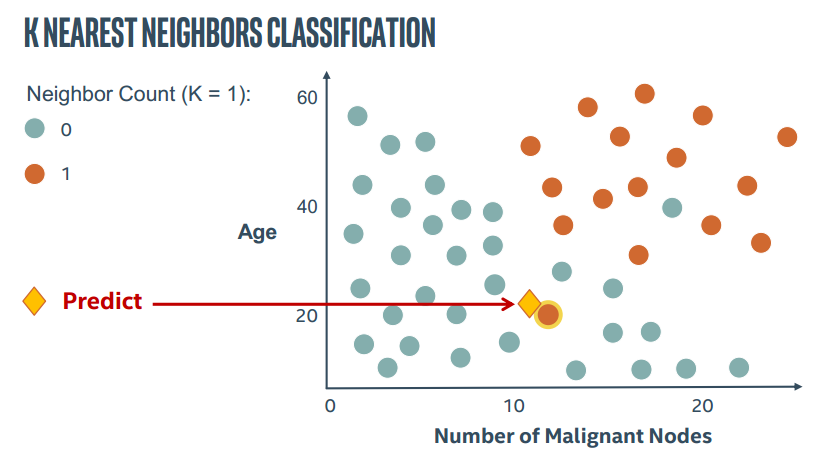
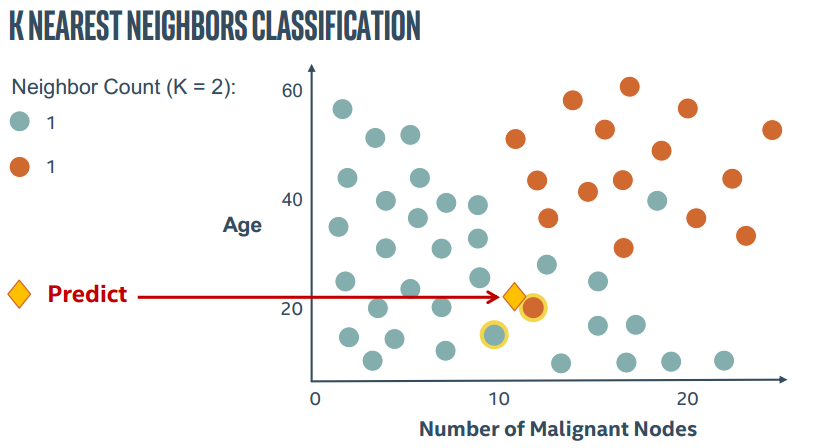
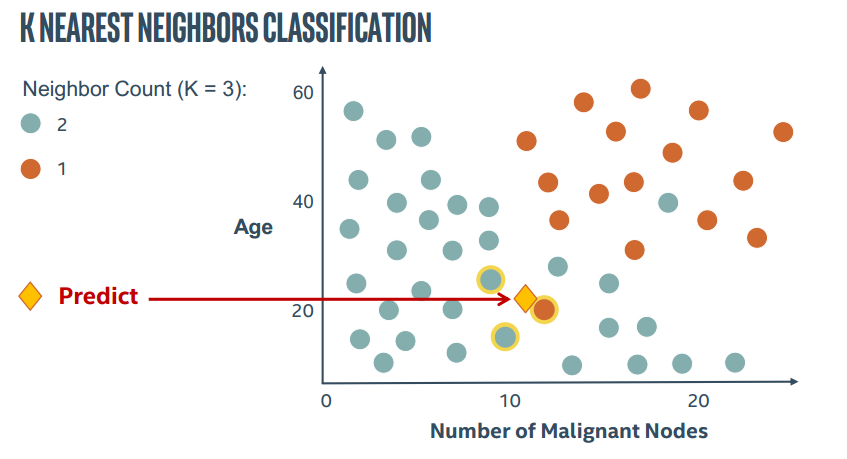
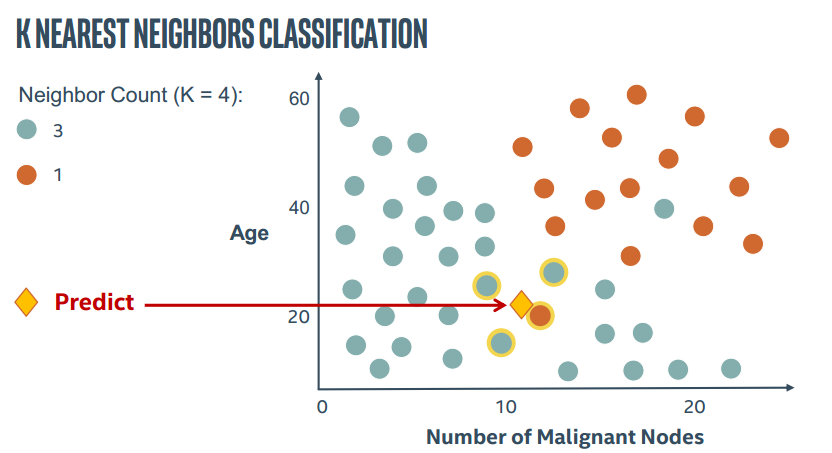
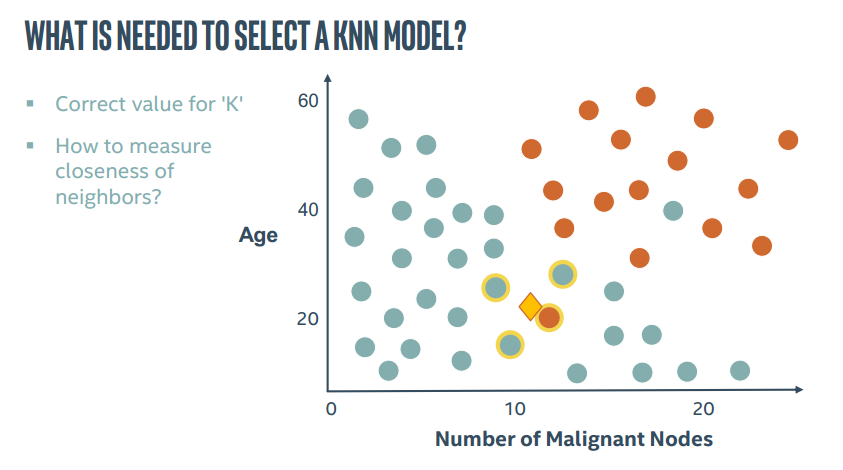
所以KNN算法中最重要的就是两个问题,如何确定K以及如何计算距离
关于K下次课再讨论
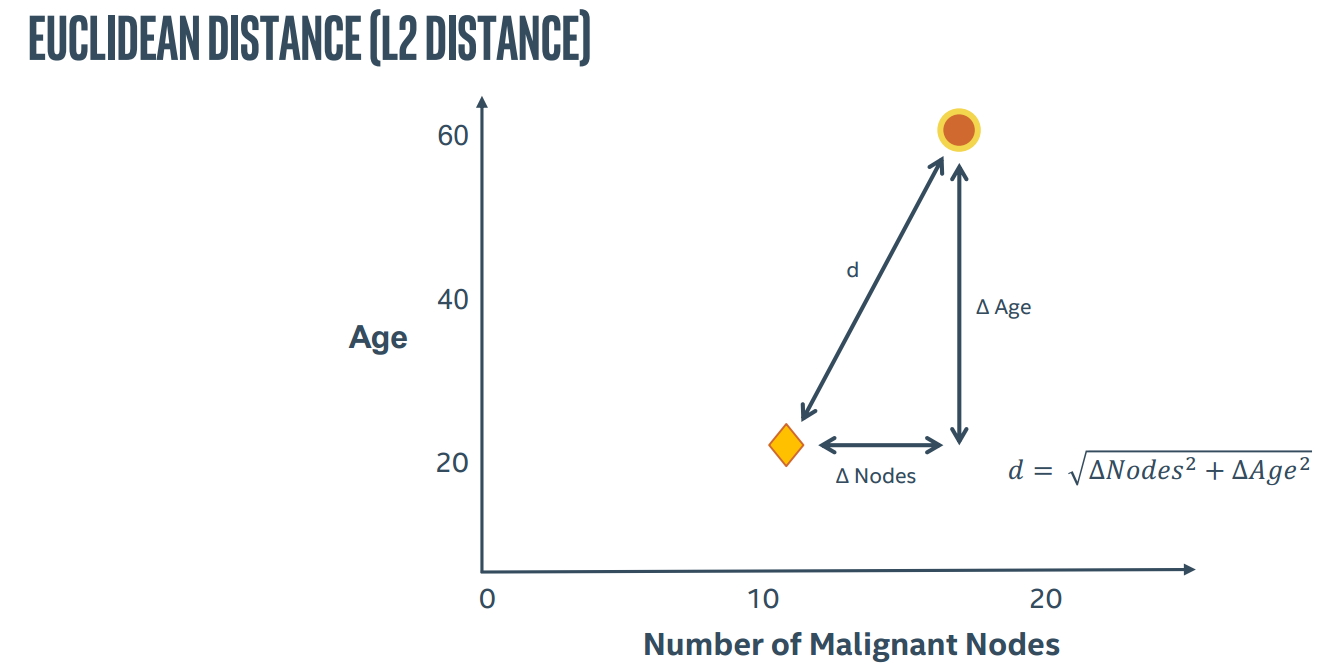
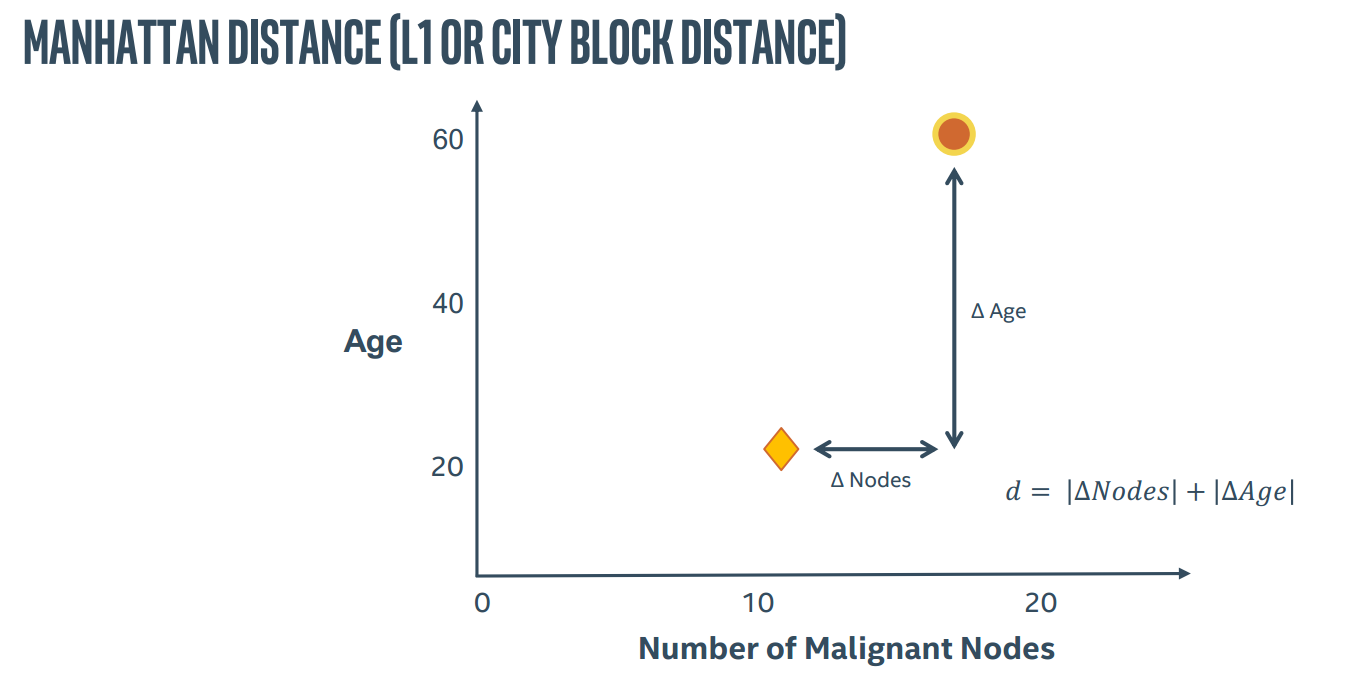
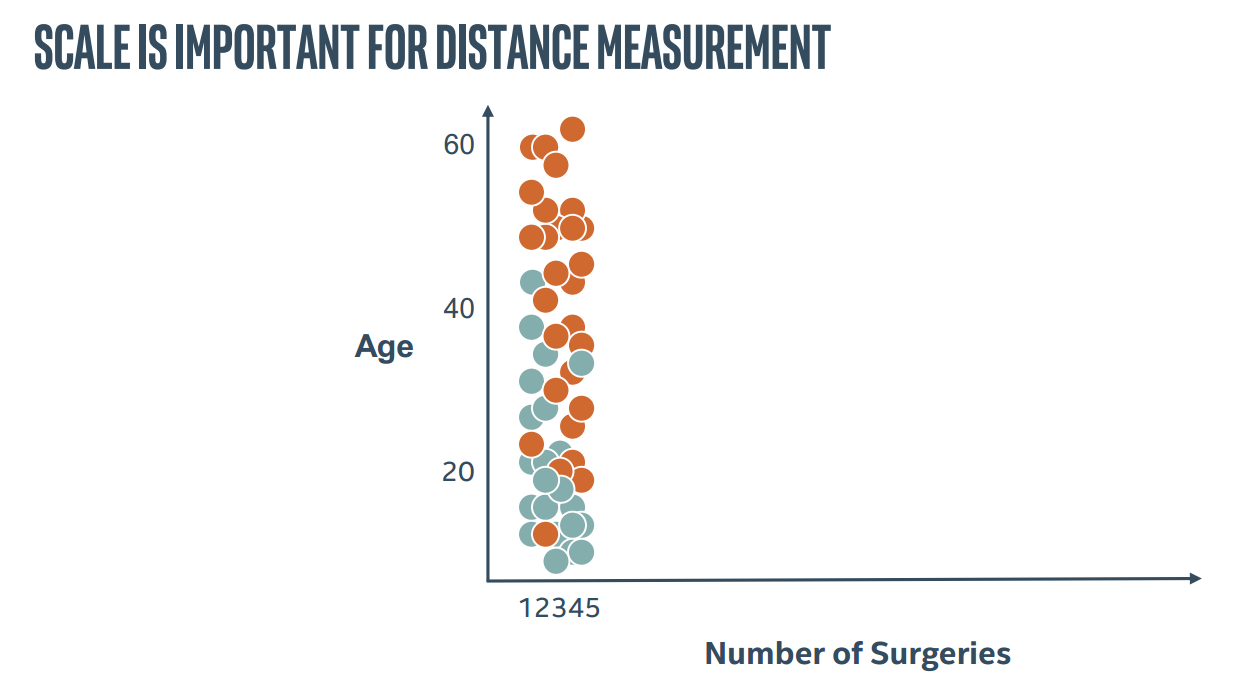
同时,比例尺对于计算距离也有很大影响
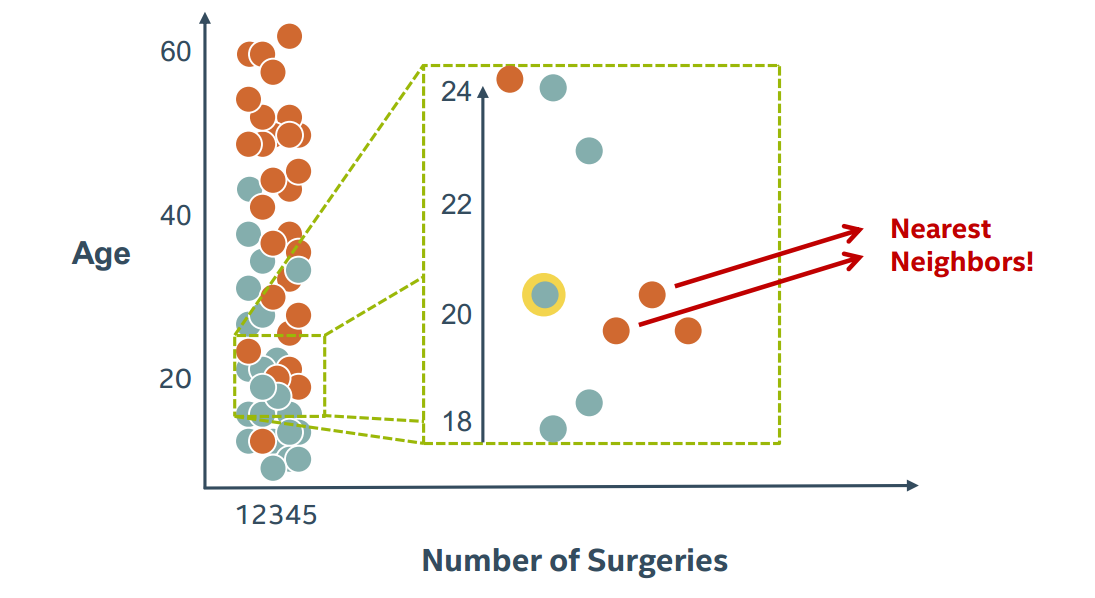
将中间一块区域放大,看上去可能是这样的
但是变换一下就成为这样了
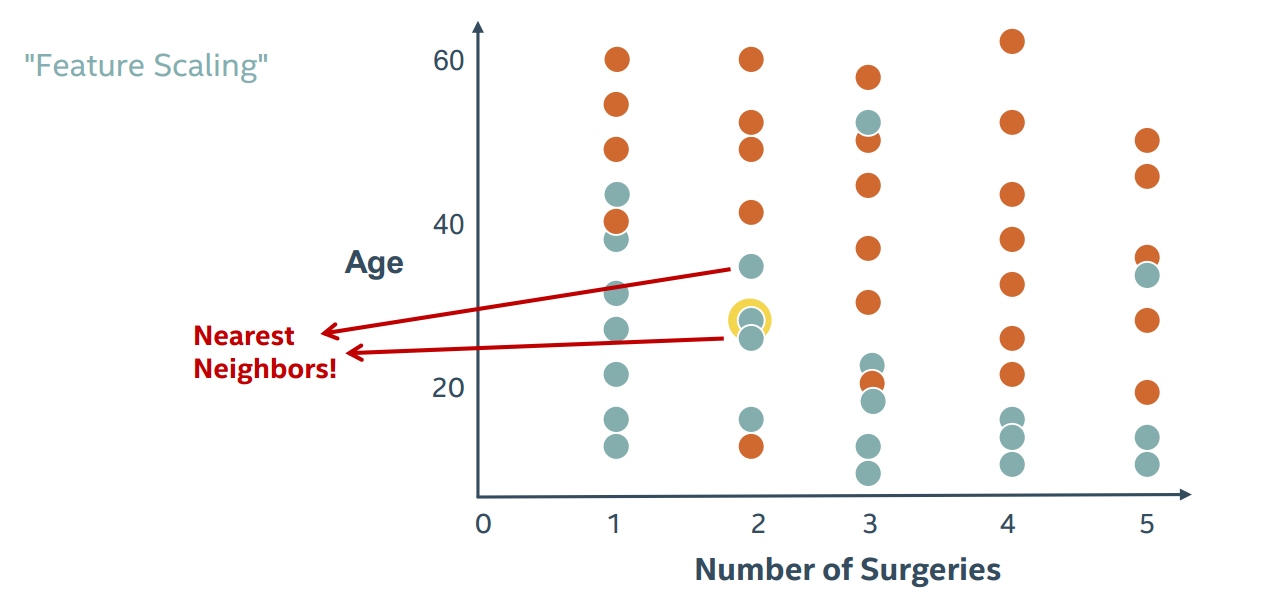
有三种不同的缩放器:
标准缩放器Standard Scaler:平均中心数据和单位方差的比例
最小 - 最大缩放器 Minimum-Maximum Scaler:将数据缩放到固定范围(通常为0-1)
最大绝对值定标器 Maximum Absolute Value Scaler:缩放最大绝对值
emm因为没有给测试数据,这里就直接拷贝代码了

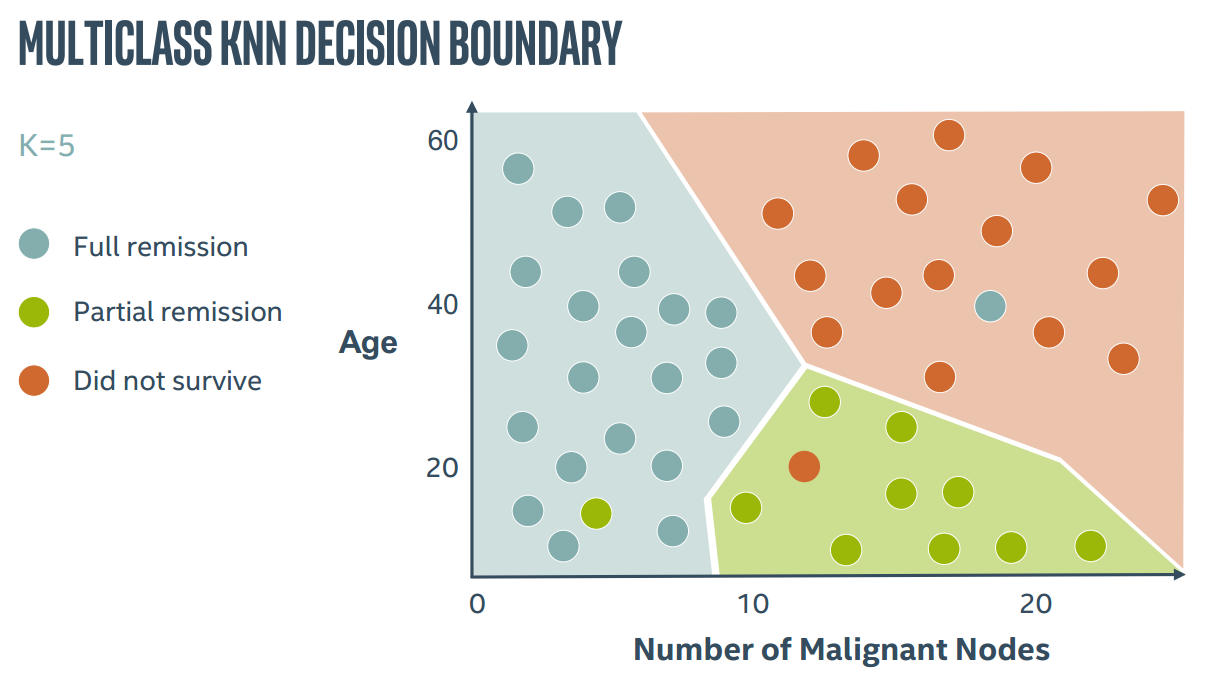
KNN还可以进行多类决策
KNN进行回归分析
KNN具有以下三种特点
1.创建模型非常快,因为只储存数据
2.预测非常慢,因为要计算大量的距离
3.如果数据集非常大可能需要大量的内存

Regression can be done with KNeighborsRegressor.
习题
Q1

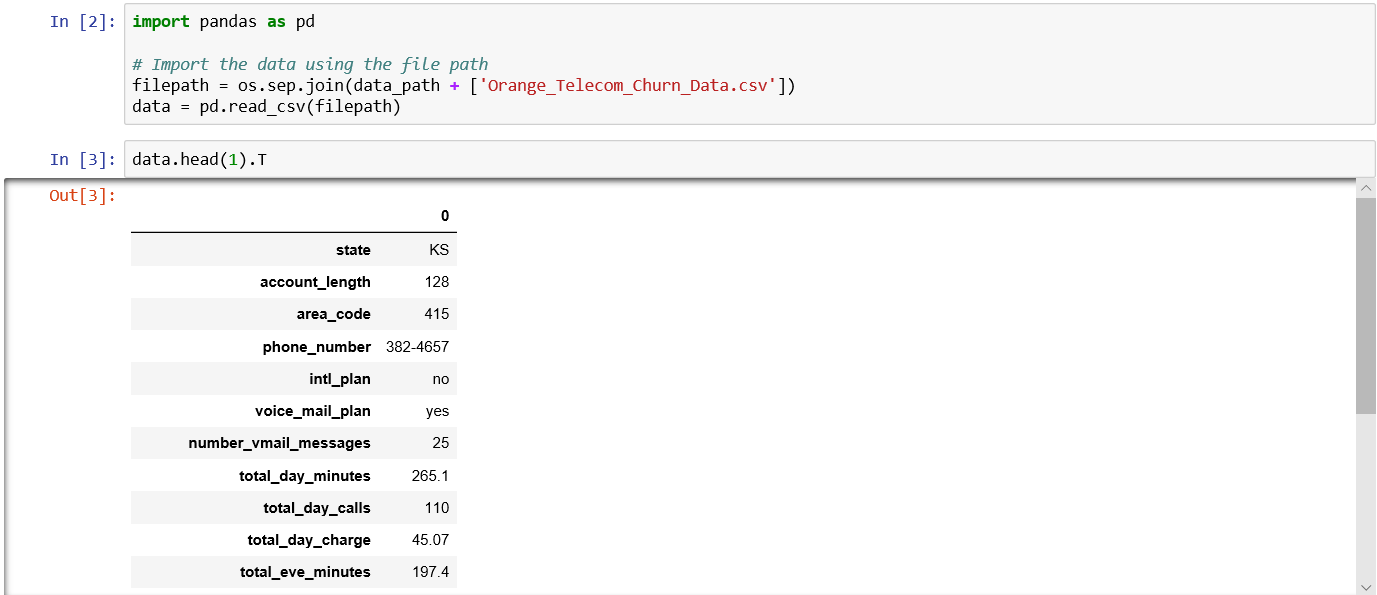
问题1:检视数据,发现有一些无用数据,将它们剔除
这里加入.T可输出转置
Q2

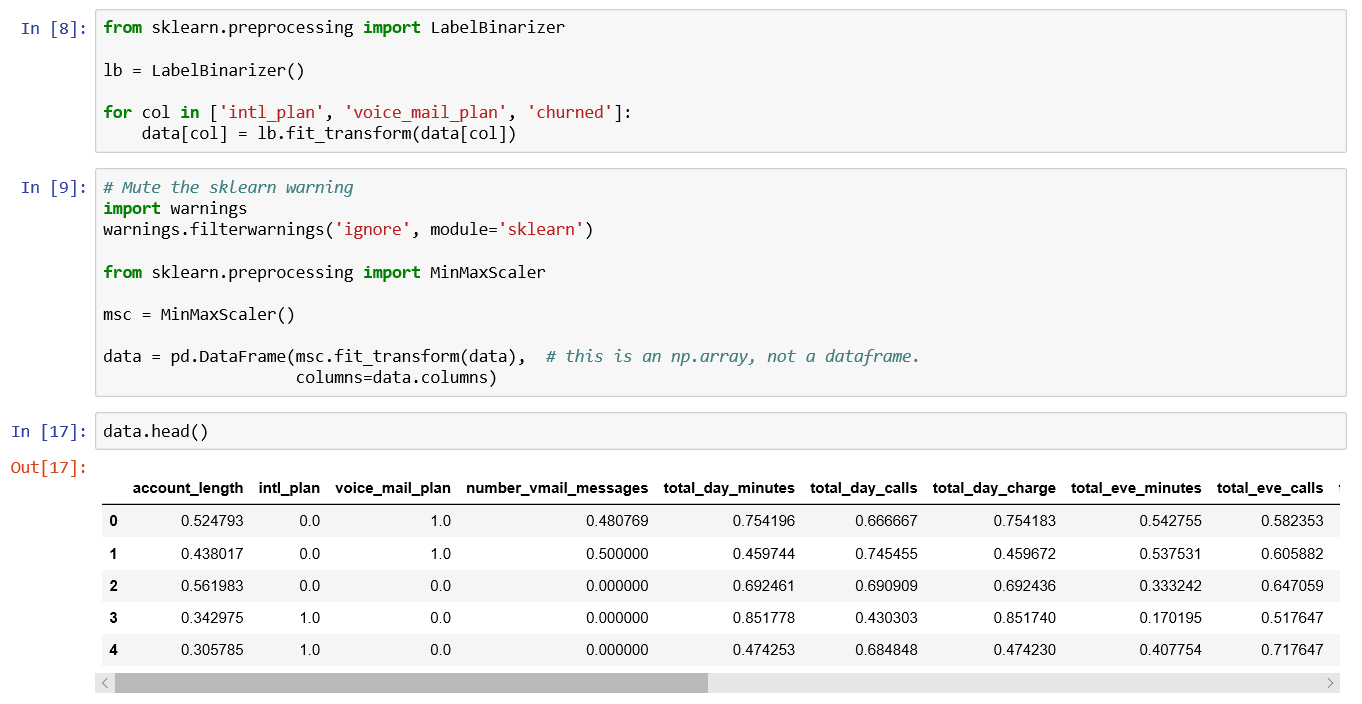
问题2:注意到部分数据是分类数据(categorical data),部分是浮点数据(float data)。我们需要进行转换
Q3

问题3:将churned作为target,其余列作为输出,以K=3建立模型并训练。最后使用训练数据进行预测

Q4

问题4:通过一个简单的计算准确率来检测模型效果

Q5

问题5:(1)使用距离权重重新建立模型并训练(2)使用均匀权重但设置p=1来计算曼哈顿距离来建立并训练模型
通过help查看帮助


然后对应修改参数即可

Q6

问题6:将K取指从1-20,p设置为1或2(但请保持一致),使用均匀距离,分别训练模型并计算准确度,最后绘图观察。

以列表形式循环训练并存储,然后绘图
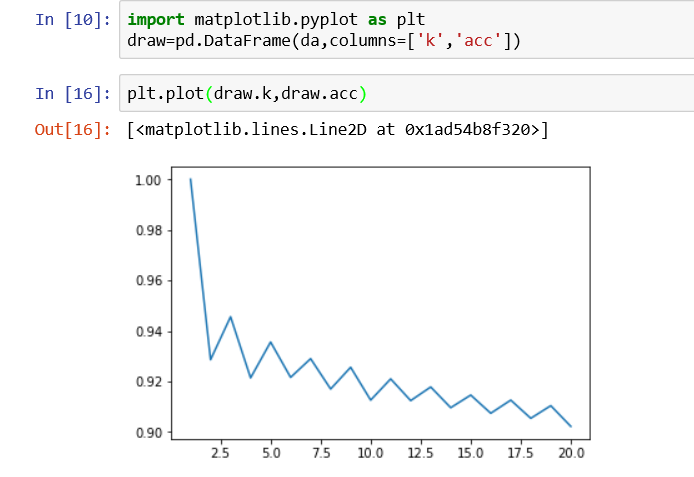
观察发现当K为1的时候准确率为1,K越大,震荡性的降低准确率。K为1的时候属于过拟合,对训练数据自然100%拟合。