Elasticsearch之文档操作
这是es系列的第五篇文章了,阅读前四篇有助于小伙伴们理解本篇文章。
回顾
前面的四篇文章我们讨论了什么是es,是用来干什么的,如何进行安装,怎么样建立索引库,如何给索引库添加mapping映射。本篇我们开始讨论如何添加文档,如何修改文档已经如何删除文档。
文档
什么是es文档,其实mapping就是es的数据字段约束,我们定义好一个索引,并且定义了一个mapping映射,就相当于我们在关系型数据库中定义好了这个表的表结构。也就是我们这个索引会用那些列。es中的一个文档,其实就是在mapping约束下的一行数据记录。索引可以认为是文档的优化集合,每个文档都是字段的集合,这些字段是包含数据的键值对。默认情况下,Elasticsearch对每个字段中的所有数据建立索引,并且每个索引字段都具有专用的优化数据结构。希望这样说小伙伴们可以理解。
maping映射结构
上篇文章中我们创建了一个叫做movie的索引,并且创建了该索引的mapping,复习一下查询索引的命令
curl -X GET "localhost:9200/movie/_mapping?pretty"
可以看到,返回一个json串,可以清晰的看到我们定义的mapping,这里就不贴出来,不知道的小伙伴可以到上一篇文章中查看。
添加
下面,我们根据定义的映射,来添加我们的文档,特别说明:我们后续针对es的操作,都会用一个工具postman俩操作,目前还不会的小伙伴们可以自行学习一下。
我们都知道,添加文档用PUT命令,所以需要执行如下命令进行文档的添加,具体请看下图,postman的操作
http://ip:9200/movie/_doc/1
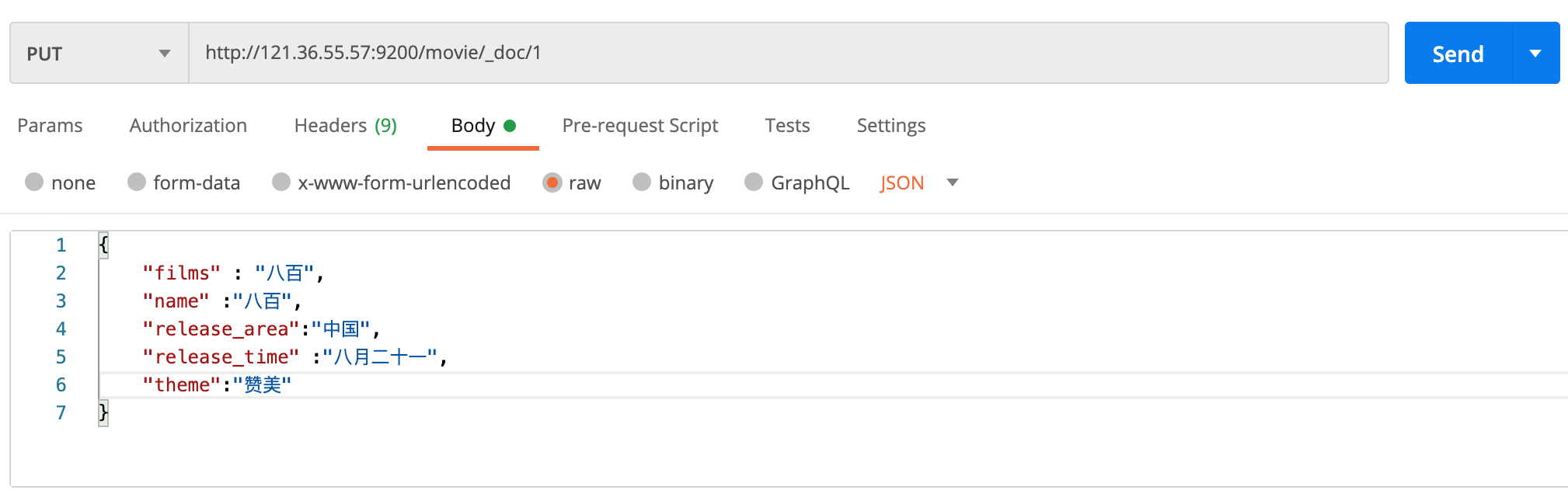
❝我们将要添加的数据,以
json键值对的方式书写完成,放在body输入框中,点击raw,选择JSON的格式❞
_doc作者目前用的es版本为7.8的版本,es7.0以前是支持多类型的,但是7.0以后,就将多类型移除掉了,默认支持_docl类型。
请求成功成功后会返回如下内容:
{
"_index": "movie",
"_type": "_doc",
"_id": "1",
"_version": 3,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 2
}
❝根据上面的内容,我们可以看到的信息有,这个文档是是创建的
❞"result": "created",属于movie索引的_doc类型以及他的版本号。
id自动分配
上面的例子,我们添加文档的时候,是指定了一个文档的id为1,那么我们如果不指定id呢?这个时候es会为我们自动生成一个id,请看下面的操作。
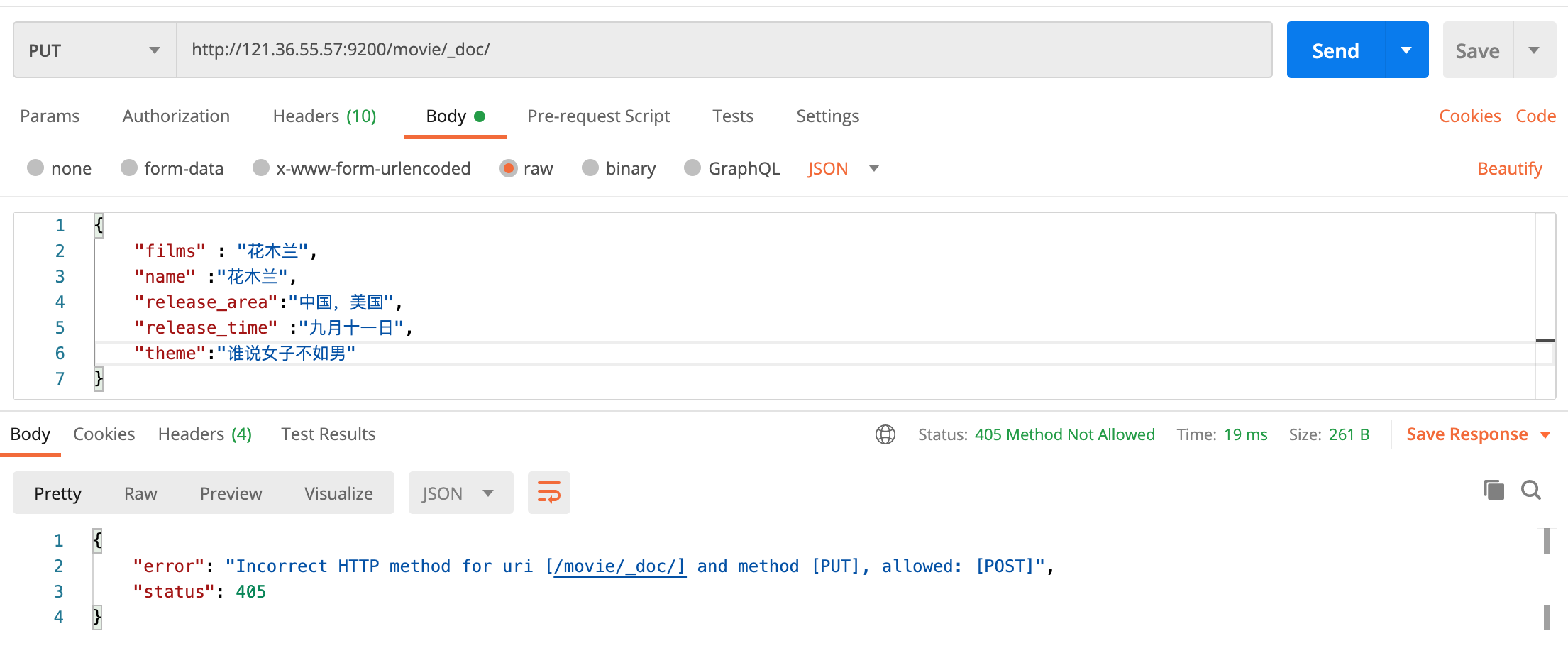
❝可以看到让系统自动分配
❞id,用PUT增加文档的时候回报错,可以看到,提示用post并非PUT。然后我们换成post进行请求,返回结果如下,可以看到系统为我们分配的id是一个字符串。
{
"_index": "movie",
"_type": "_doc",
"_id": "9XmceHQByHcRbTF_z1TT",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 3
}
修改
es的修改,不是真正的修改,它的机制是将,原有的文档删除掉,然后新建一个,并且版本号加1.那么我们将修改的内容如下:
{
"films" : "八百",
"name" :"八百",
"release_area":"中国",
"release_time" :"八月二十一",
"theme":"赞美小人物"
}
再次使用PUT命令进行请求,返回结果如下:
{
"_index": "movie",
"_type": "_doc",
"_id": "1",
"_version": 4,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 2
}
❝可以看到,这个时候
❞"result": "updated",是updated``而不是created的操作,并且版本号进行了累加。
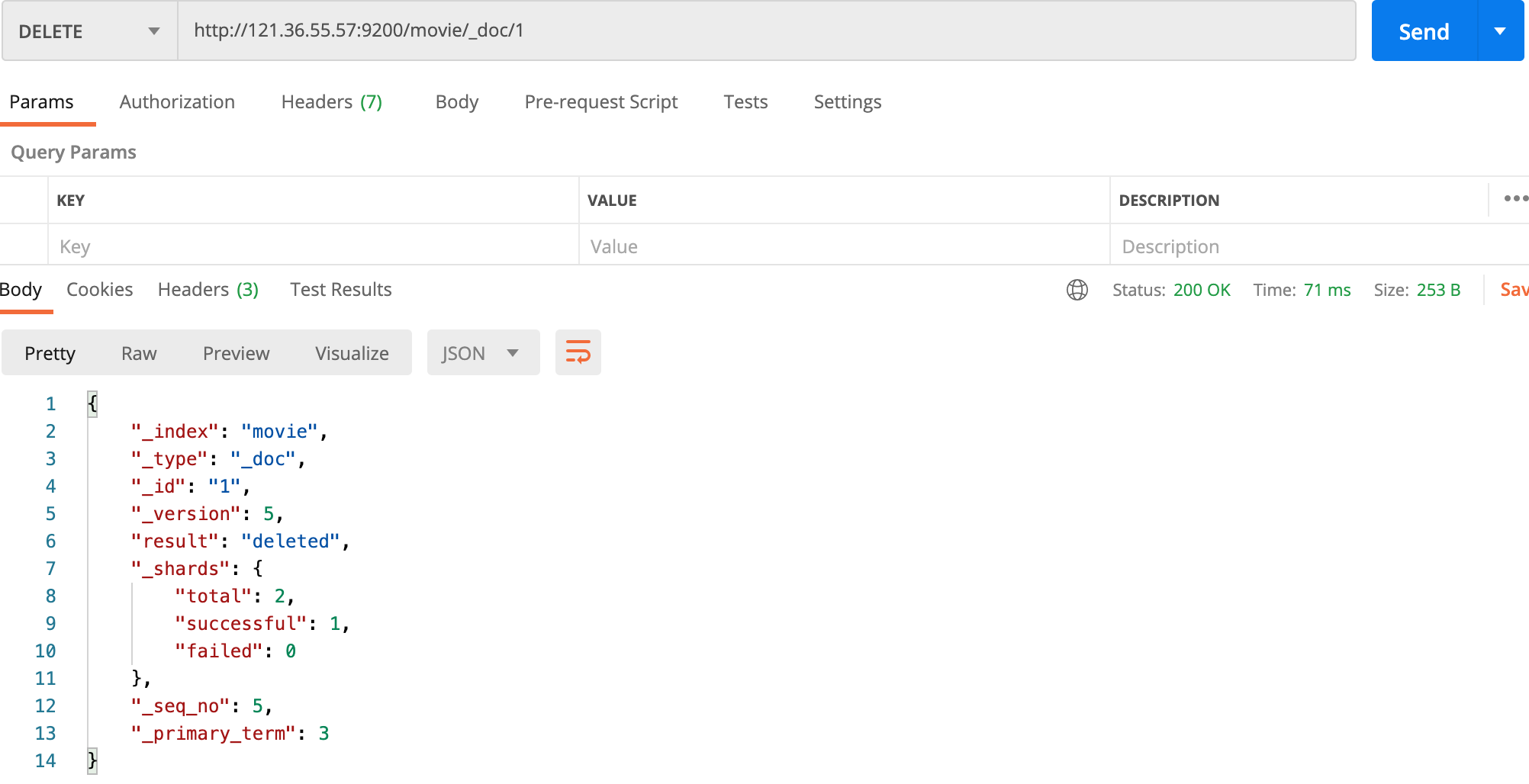
删除
删除一个文档就很简单了,直接指定你要删除的文档id就可以了,如下:
查询
我们将刚刚删除的那个文档在添加进去,下面我们看一下如何查询文档。
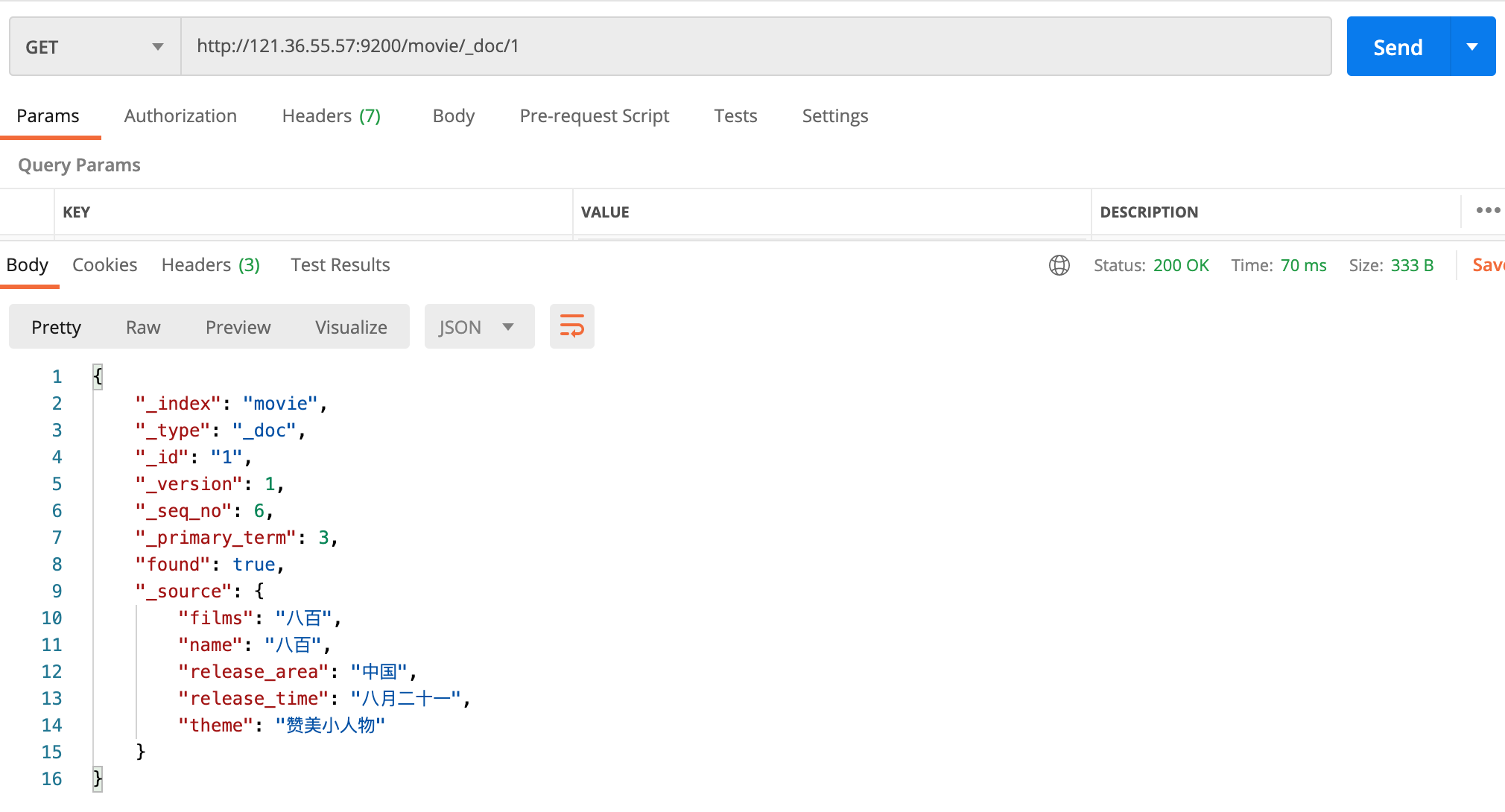
查询单个文档
我们查询id为1的文档,如下:
批量查询
批量查询,我们会用到一个_mget的指令,如下:
http://121.36.55.57:9200/_mget
请求体为
{
"docs":[
{
"_index":"movie",
"_type":"_doc",
"_id":"1"
},
{
"_index":"movie",
"_type":"_doc",
"_id":"2"
}
]
}
查询结果
{
"docs": [
{
"_index": "movie",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 6,
"_primary_term": 3,
"found": true,
"_source": {
"films": "八百",
"name": "八百",
"release_area": "中国",
"release_time": "八月二十一",
"theme": "赞美小人物"
}
},
{
"_index": "movie",
"_type": "_doc",
"_id": "2",
"_version": 1,
"_seq_no": 7,
"_primary_term": 3,
"found": true,
"_source": {
"films": "信条",
"name": "信条",
"release_area": "美国,英国",
"release_time": "九月四日",
"theme": "时空逆袭"
}
}
]
}
还可以这些查询,指定索引,指定类型,直接提供id就可以查询
http://121.36.55.57:9200/movie/_doc/_mget
请求体如下:也是可以查到的。
{
"ids":["1","2"]
}
小结
好啦,小伙伴们,今天的东西不难,很简单,只是简单的向大家介绍了,es针对文档的CRUD操作。其实es的重点是查询,下篇文章中我们会导入大批量的数据,然后各式各样的查询方法和小伙伴们玩转es.
