这篇文章不打算讲解什么是线程池?线程池怎么用?直接讲解原理
1、线程池关键参数解释
JDK 线程池的实现类是 ThreadPoolExecutor,构造函数关键参数解释如下:
corePoolSize 核心线程,线程池维持的线程数量,即使没有任务执行也会维持这个数量不变,除非设置了 allowCoreThreadTimeOut 这个参数为 true
maximumPoolSize 线程池中允许创建线程的最大数量
keepAliveTime 非核心线程的空闲等待时间,超过这个时间将被销毁
unit 针对keepAliveTime 参数的时间单位
workQueue 任务队列
2、 execute和submit的区别?
1)submit有返回值
2)submit提交的线程类型,会被jdk包装成一个FutureTask
3、运行原理
3.1任务执行流程
这不是一个流程图,是为了说明线程启动到执行任务的大概流程
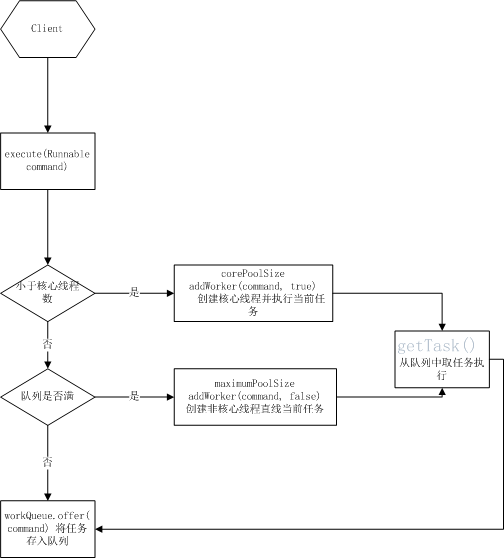
3.2 源码分析
先说下执行主流程,再细看源码。
执行流程:execute(Runnable command) >>addWorker(Runnable firstTask, boolean core)>>runWorker(Worker w)
源码分析:
1)execute(Runnable command)方法

该方法会调用addWorker(Runnable firstTask, boolean core)方法执行任务
2)addWorker(Runnable firstTask, boolean core) 方法
该方法代码比较长,我们看下关键的代码部分
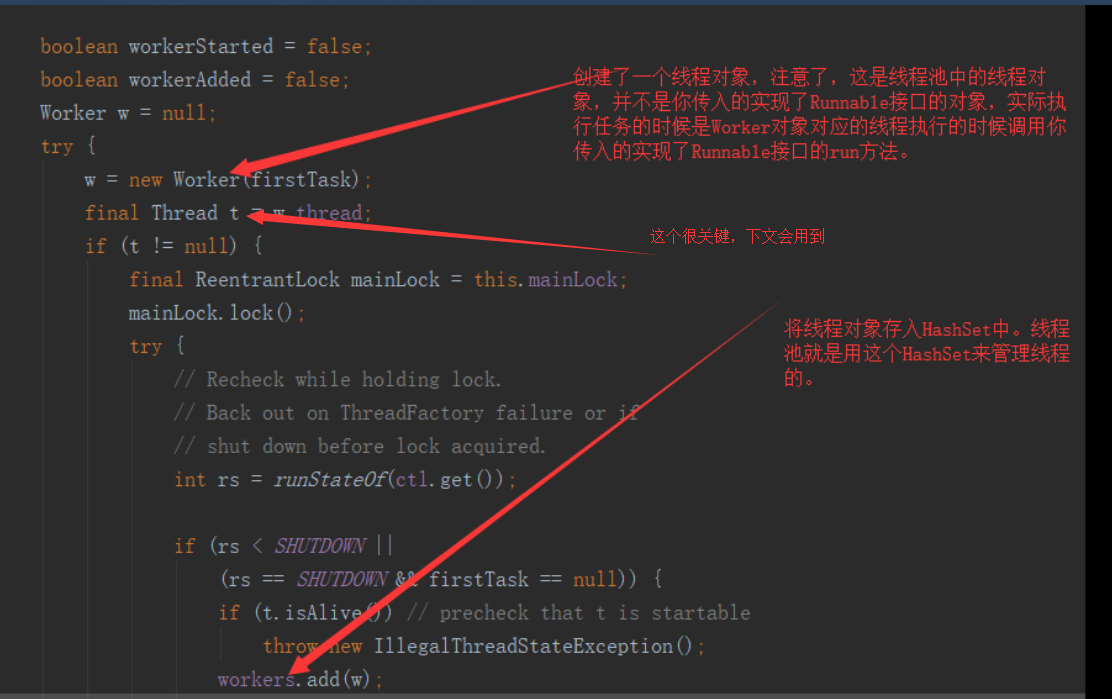
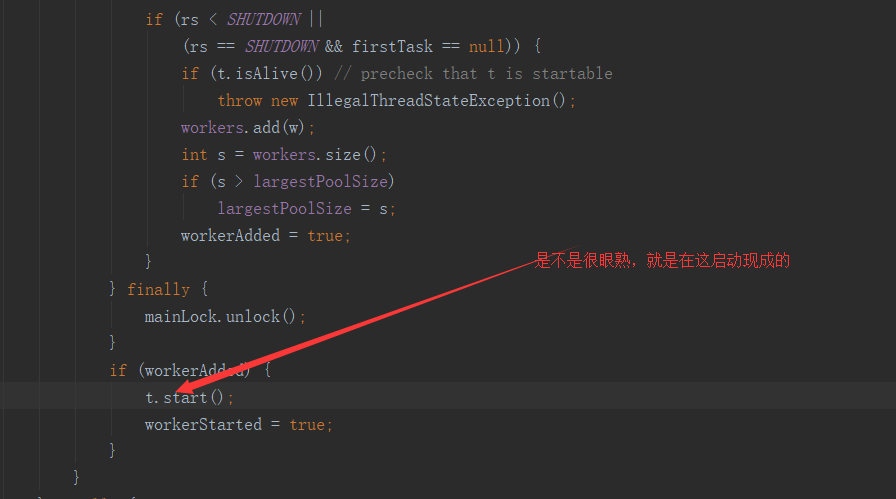
既然启动线程了,那我们就去Worker里看看
3) Worker 内部类

既然2)中调用了start()方法,那么必然会调用Worker的 run()方法
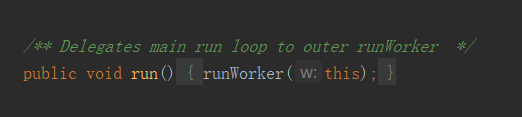
接下来看 runWorker(this)方法,最最关键的部分就在这里,老办法,我们也还是看最关键的代码片段

4)看下这个方法 processWorkerExit(Worker w, boolean completedAbruptly)

总结一下,线程池就是维护一个线程集合,用这些线程来反复的执行任务,这些线程分为核心线程和非核心线程,核心线程一般不会被销毁,就算是没有任务也会空闲等待(除了设置 allowCoreThreadTimeOut参数),非核心线程,当空闲等待时间到达设置的参数范围,就会被销毁回收。比较难理解的是JDK是如何维护线程集合并执行任务?这里在说一下,线程池初始化,当第一个任务来的时候,线程池会创建一个线程并将该线程存入一个线程集合,刚才的任务作为该线程的第一个任务执行,执行完该任务,此时线程不会立即结束,会通过getTask()方法,以阻塞等待方式从任务队列里面获取任务执行,因此如果阻塞队列有任务,就取出任务执行,如果队列没有任务,就阻塞等待任务,所以正常情况下,该线程会一直存活。当第二个任务来了以后,会执行和第一个任务同样的动作,以此类推,直到核心线程数量达到corePoolSize设置的参数数量,这样就形成了线程集合,也就是线程池。当任务很多的时候,核心线程不能及时全部处理完毕,此时线程池就会将任务存入任务队列,如果队列满了,并且 maximumPoolSize 大于 corePoolSize,就会创建非核心线程执行任务。