除了特殊注释外,本文的测试结果均基于 spring-data-mongodb:1.10.6.RELEASE(spring-boot-starter:1.5.6.RELEASE),MongoDB 3.0.6
我们在学习了一门编程语言时,一定要明白语句底层的意义,比如 User user= new User(); 它在堆中开辟了一个空间用于存放User(),并且在栈中新增了一个指向这个堆空间的指针user。那么,mongo shell中的 var user = db.user.find(); 到底做了什么?也是为集合user开辟了一个堆空间,然后再让user指向这个空间吗?
让我们先来做个实验
> function testTime(){ ... var date1 = new Date().getTime(); ... for(var i = 0; i < 10000; i++){ ... var user = db.user.find(); ... } ... return new Date().getTime() - date1; ... } > testTime(); 165
user表中是有100w条数据的,100万条数据的空间创建10000次,只用了165ms?
显然是不现实的,我们再看一下
> function testTime(){ var date1 = new Date().getTime(); for(var i = 0; i < 100; i++){ var user = db.user.aggregate(); } return new Date().getTime() - date1; } > testTime(); 2800
这里我们将find方法替换成了aggregate,并且将10000次循环改成了100次,然后时间却上升了到2800ms。通过第二章我们知道aggregate的底层是findOne,让我们再回头仔细看看findOne和find的代码区别
> db.user.find function ( query , fields , limit , skip, batchSize, options ){ var cursor = new DBQuery( this._mongo , this._db , this , this._fullName , this._massageObject( query ) , fields , limit , skip , batchSize , options || this.getQueryOptions() ); var connObj = this.getMongo(); var readPrefMode = connObj.getReadPrefMode(); if (readPrefMode != null) { cursor.readPref(readPrefMode, connObj.getReadPrefTagSet()); } return cursor; //find方法返回的是一个游标 } > db.user.findOne function ( query , fields, options ){ var cursor = this.find(query, fields, -1 /* limit */, 0 /* skip*/, 0 /* batchSize */, options); if ( ! cursor.hasNext() ) return null; var ret = cursor.next(); if ( cursor.hasNext() ) throw Error( "findOne has more than 1 result!" ); if ( ret.$err ) throw Error( "error " + tojson( ret ) ); return ret; //findOne返回的是具体的数据 }
find和findOne主要的差别是一个返回了游标,一个返回的实际的数据,游标就是一种类似于指针的东西,只是返回了数据库中数据的地址,没有对数据进行复制,所以极大的提升了查询速率。相应的,在spring-data-mongodb中的其实也有这么一对相对的方法

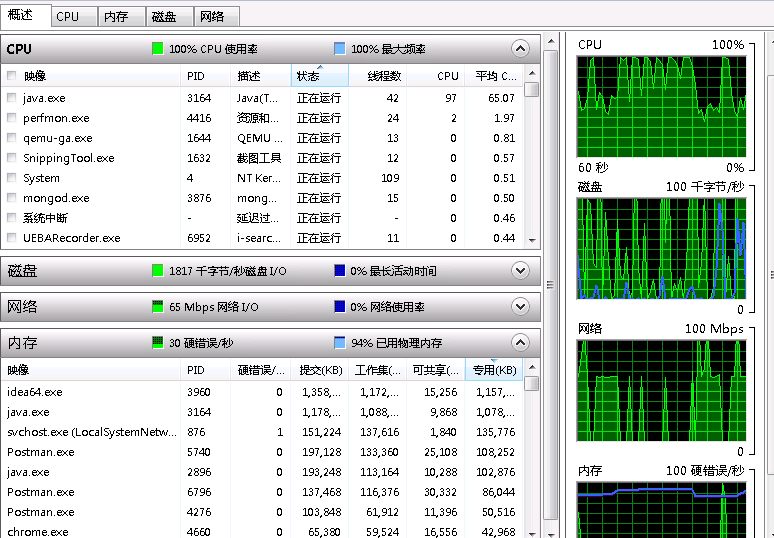
执行第一个方法时,平均90%的CPU占有率跑了70分钟,而第二个方法只用了不到一秒,说明第二个并没有直接请求全部的数据,而是返回了一个类似于指针的游标。在 spring-data-mongodb:2.1.2RELEASE中已经去除掉这个方法,那么这个方法的优缺点是啥,为什么要去掉这个方法呢?
上面的各种测试结果表明了返回游标的好处(957ms 对上 4420270ms)。当然它也存在很致命的缺点:查询过程中若文档被修改,可能因为空间位置不足,而移动到集合的末尾,这样这个位置变动的文档就可能会被读取到两次,造成数据的误差。性能的提升固然重要,但是正确性才是数据库的核心,这可能就是新版本的spring-data-mongodb去掉了该方法的原因吧。
spring-data-mongodb去掉了该方法,而在mongo shell中提供了专门的快照功能,用于避免游标可能造成的数据重复问题,使用方式:db._collection_.find().snapshot();
现在我们弄明白了游标的优点:用一个数据读一个数据,不事先取出全部数据,减少开销,优化查询,还有缺点:大数据量时容易造成数据错乱,从游标的优缺点上我们可以知道,若查询结果只有一个,或者是必须要遍历所有数据才能得出查询结果时,游标是无效的。根据这个特征,我们能得出以下三种情况不应该用游标:
(1) findOne,只取一条数据,那么也就不需要返回游标了
(2) 数据库操作命令,用户只关注的是操作成功或失败
(3) 分组函数,这些函数需要遍历完所有的数据,才能得出最后的结果
巧的是,我们最开始看的源码就是,runCommand,aggregate底层都是用的findOne,而findOne没有用游标,直接返回了最终结果。因此,我们可以解答最开始的疑问了:
runCommand命令和查询函数的层级关系是怎么样的?
查询函数中,findOne和find并不是同一流派,findOne跟runCommand的关系更亲近。mongo首先根据是否应该使用游标将 find 独立出去了,而在runCommand、findOne、aggregate中,aggregate 调用 runCommand ,runCommand调用findOne。
因此,便有了最开始的runCommand调用了findOne方法,而为了与一般的数据表findOne查询区分,mongo就提供了一个特殊表$cmd用于执行(2)、(3)情况的函数。这个$cmd表无法插入数据,无法直接查询数据,使用db.getCollectionNames();时也不会展示,只有使用相应的操作符的时候,可以进行相应的查询。
在新版本中,$cmd藏的更深了,我一直纠结的鸡生蛋蛋生鸡的情况也不见了,我上面总结的一些情况也过时了。技术就是这样,总是在不断的过时,但是思维不会过时,逻辑不会过时,各位,共勉之。
目录
一:spring-data-mongodb 使用原生aggregate语句