""" 管理员视图: 1、注册 2、登陆 3、上传视频 4、删除视频 5、发布公告 用户视图: 1、注册 2、登陆 3、会员充值 4、查看视频 5、下载免费视频 6、下载收费视频 7、查看观影记录 8、查看公告 """
优酷:https://www.processon.com/diagraming/5d5f897fe4b09965face8d6d
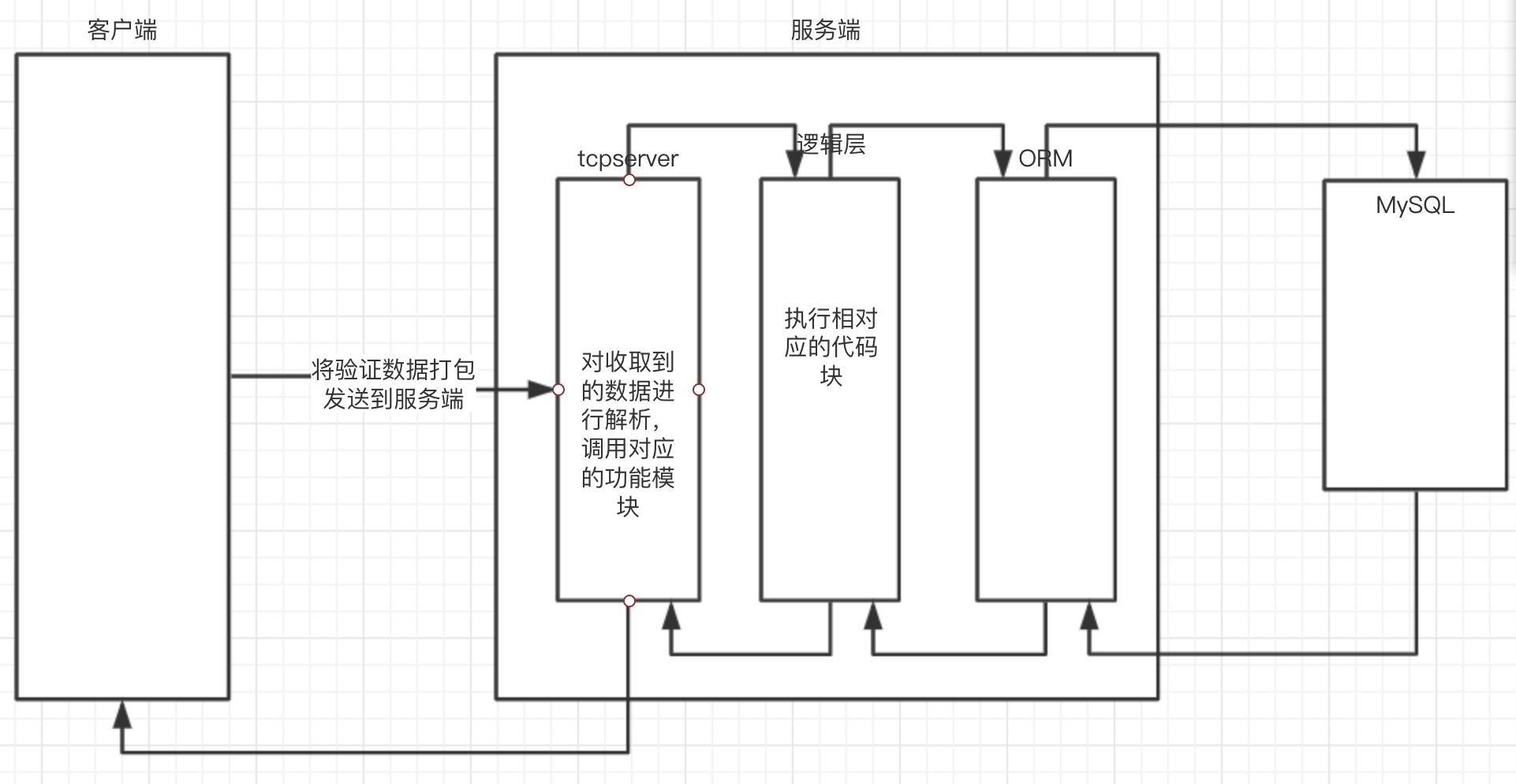
首先以注册功能为例:https://www.processon.com/diagraming/5d5f8ed2e4b09965face9c31
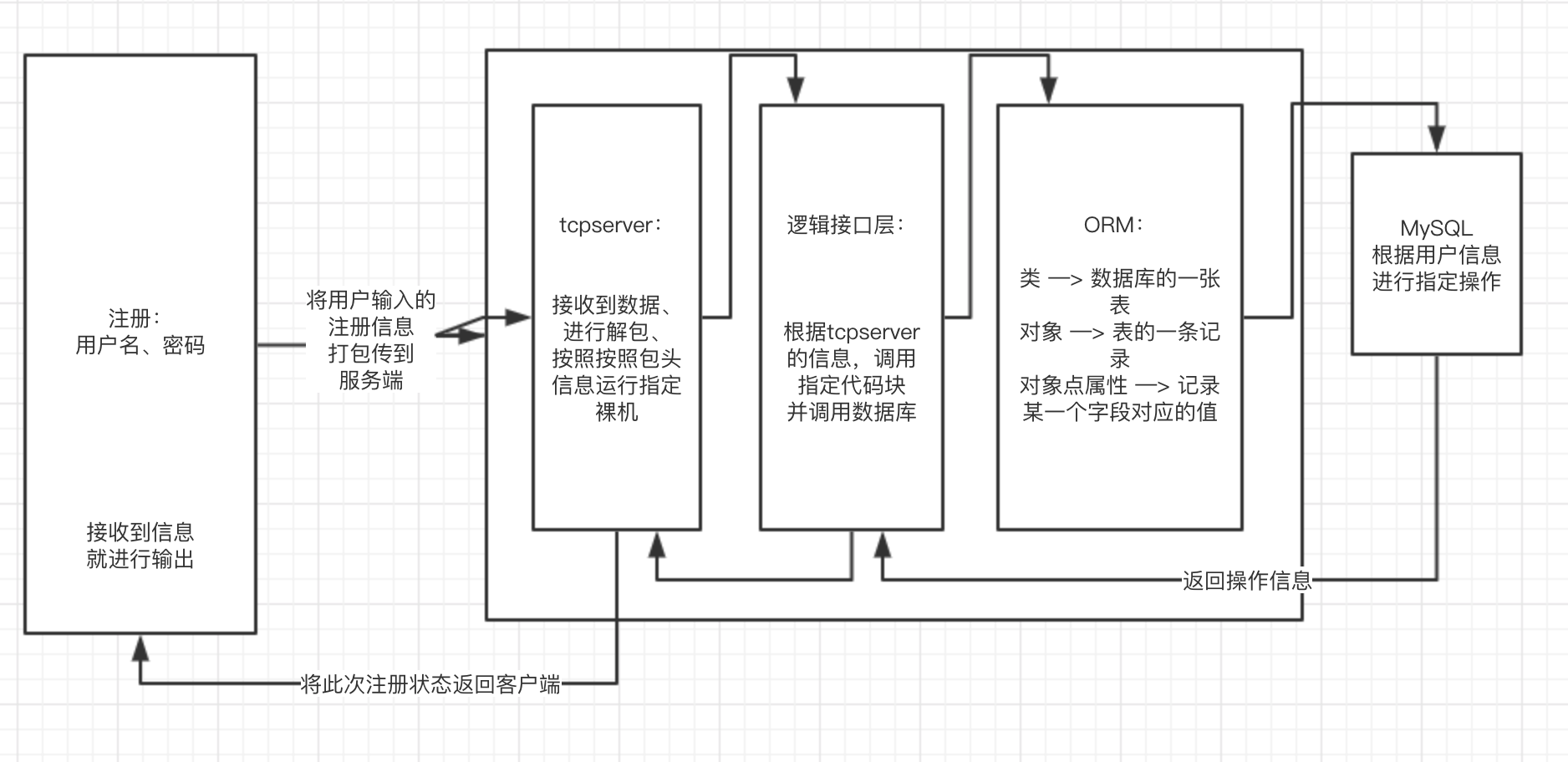
1、首先将用户数的数据进行打包发送到服务端中
2、服务端根据接受的数据首先进行解包,按照包内的信息进行指定操作
3、调用逻辑层中的指定接口来进行操作,当遇到数据相关的操作,调用ORM
4、当调用ORM的时候,直接进行点操作,来进行对数据库中某一块进行操作
5、有来就有回,这时候将写入的状态进行逐层返回,知道返回到客户端中的用户界面。
ORM:https://github.com/1213William/ORM_demo
ORM(对象映射大致关系):
类 --> 数据库中的一张表
对象 --> 表中的某一条数据
对象点属性 --> 操作某条数据中的某一个字段
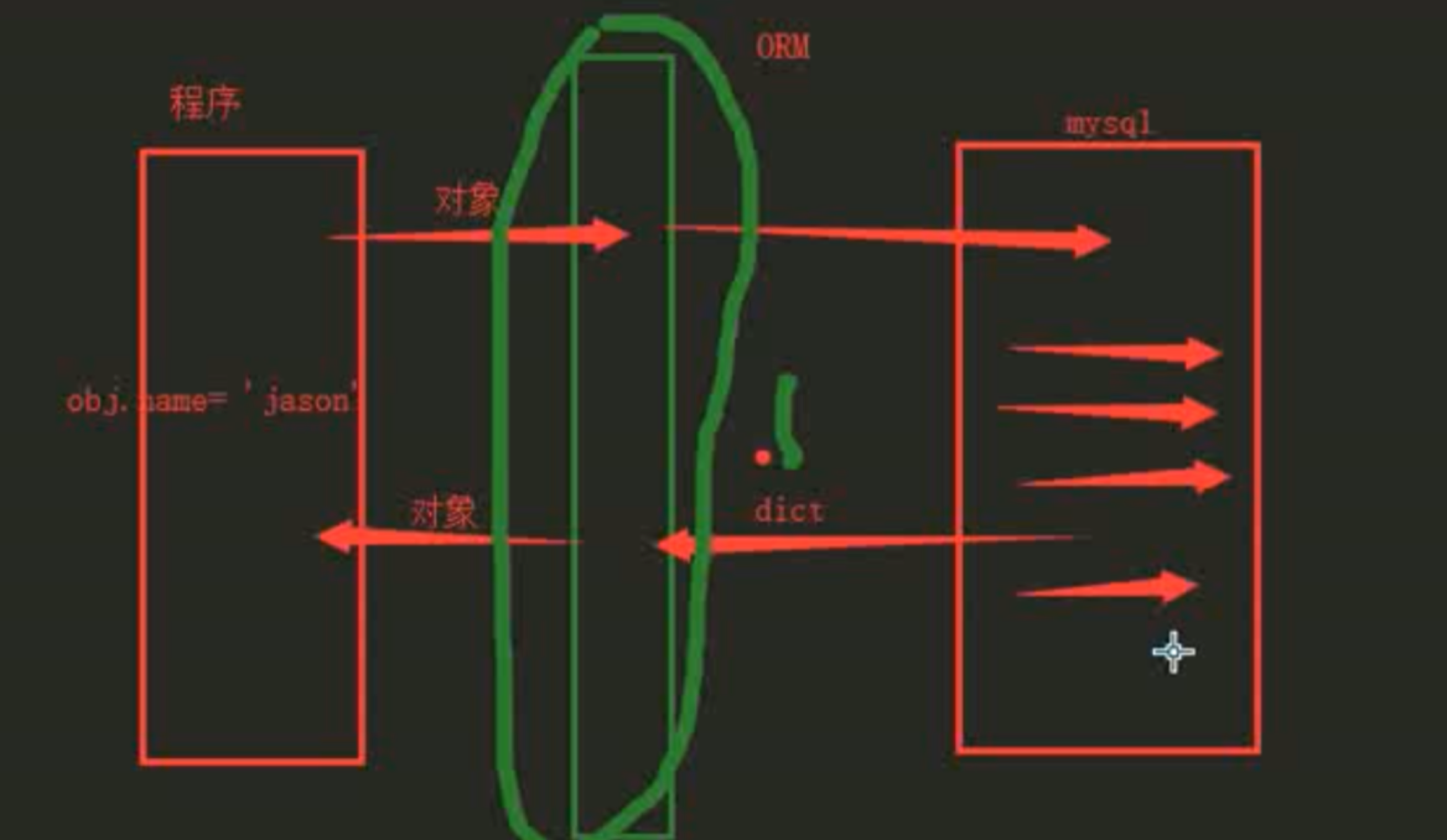
数据库中不能直接进行存储类对象,所以这时候就出现了ORM,将数据库中的一张表通过一些操作映射成了一个类
这就可以方便用户可以直按照平时操作类的方式,来对数据库中的信息进行增删改查等操作。
1、定义一个字段所拥有的相关属性
2、自定义ORM中需要的数据类型,在优酷中用到的:int、varchar
3、要定义一个中间件方便用户可以通过点操作来直接操作表中的信息
4、在ORM中比较关键的是元类的定义,通过判断类名称空间中的内容是否是我需要的,是的话就要将所有的字段信息放到自定义的容器中存储起来
然后通过找出主键,和表名(主要是为了后面在Model中操作的时候可以直接拿到表名称进行查询),
当找出了这些字段信息之后,就产生了一个问题--> 类名称空间中和我们定义的容器中产生了重复,所以这时候就需要手动去除一下重复的数据,
去玩重复数据之后,我们就可以将主键、存放字段类型的容器放到当前类名称空间中了(方便后面的调用)
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Cookie和Session
Cookie:
什么是Cookie:
Cookie具体指的只是一段信息,它是服务器发送出来存储在浏览器上面的一组组的键值对,当你在下次访问的服务器的时候浏览器会自动携带这些键值对,以方便服务器提取有用的信息
Cookie的原理:
Cookie的工作原理:由服务器产生内容,浏览器收到请求之后保存在本地,当浏览器再次访问的时候,浏览器会自动带上Cookie,这样服务器就能通过Cookie的内容来判断这个时候“谁”了。
Session:
由来:Cookie在一定程度上解决了“保持状态”的需求,但是Cookie本身最大支持4096字节,以及Cookie本身保存在客户端,会有被拦截或者窃取的可能,所以这时候就需要一种新的东西,他能支持更多的字节,并且它是保存在服务端的,安全性相比于Cookie要更高,所以随之产生了Session
Cookie连接桥:
HTTP协议的无状态特征,服务器根本就不知道访问的是“谁”。那么Cookie就起到了连接桥的作用,我们可以给每个客户端的Cookie分配一个唯一的id,这样用户在访问的时候,通过这个Cookie,服务器就知道来的人是哪一个了。之后我们在根据不同的Cookie的id,在服务端上保存一段时间的私密资料,(账号、密码等等)
总结:Cookie弥补了HTTP无状态的不足,让服务器知道来的人是哪一个;但是Cookie以文本的形式保存在本地,自身的安全性是比较差的;所以我们通过Cookie识别不同的用户,对应的Session里保存相对的私密信息以及超过4096字节的文本
另外,Cookie和Session其实是共同性的东西,是不限于语言和框架的。
相对于优酷项目的Cookie和Session的大白话:
服务端要保存客户端登陆的一条信息,然后返回到客户端进行保存,然后那个客户端在进行别的操作就要带上这个信息一起发送到服务端,服务端进行比较,如果一样代表已经登陆过了,可以直接进行操作,如果没有这个信息就提示用户先去登陆
主要的点就是在服务端的那个装饰器的写法,在每次用户进行别的操作的时候,都要对那个唯一的加密内容进行验证,如果:
def login_auth(func): @wraps(func) def inner(*args, **kwargs): # args: conn, back_dic for value in user_data.alive_user.values(): # [session, user_id] if args[1].get('session') == value[0]: args[1]['user_id'] = value[1] break if args[1].get("user_id"): func(*args, **kwargs) else: back_dic = {'flag': False, "msg": '请先去登陆...'} send_msg(args[0], back_dic) return inner