内置函数
大纲:


一:作用域相关(2)
① locals()返回本地作用域中的所有关键字
② globals()返回全局作用域中的所有关键字
基于字典的形式获取局部变量和全局变量
二:迭代器/生成器相关(3)
① next(迭代器) 相当于 迭代器.__next__() ② Iter(可迭代的) 相当于 可迭代的.__iter___() ③ range(1,11) 取1~10 range是可迭代的,不是迭代器
三:其他(12)
① 查看内置属性:——dir
dir查看查看一个变量拥有的方法
②调用相关:——callable———返回True或者false
如:print(callable(a)) #结果是False print(callable(函数名))#结果是True
③帮助——help
作用与dir相似,但内容更加详细,如help(str)
④模块相关——import
import time #导入时间模块 import os #导入操作系统模块
◆某个方法属于某个数据类型就用 . 调用(list.append)
◆如果某个方法不依赖于任何数据类型,就直接调用(有自定义函数和内置函数)
⑤文件操作相关——open
f = open(‘file’) print((f.writable()) #判断能不能写 print((f.readable()) #判断能不能读
⑥内存相关——hash id
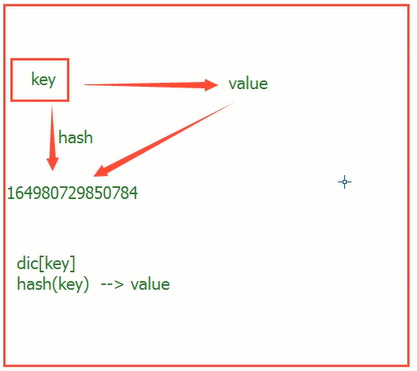
Id 查看变量的内存地址
Hash 对于相同可哈希数据的hash值再一次执行过程中总是不变的
通过hash更了解了字典的寻址方式 ;通过hash(key)直接找到value的内存地址
⑦输入输出相关——input print
print('祖国',end = '') #指定输出的结束符
print('祖国',sep = '|') #指定输出多个值之间的分隔符


import time for i in range(0,101,2): time.sleep(0.3) char_num = i//2 per_str = ' %s%% : %s '%(i,'*'*char_num) if i == 100 else' %s%% : %s'%(i,'*'*char_num) print(per_str,end='',flush=True)
⑧字符串类型代码的执行-———eval exec compile
◆eval和exec都可执行字符串类型的代码,但是eval有返回值,exec没有
◆eval只能用在明确知道要执行的代码时什么;适合处理有结果的简单运算
◆exec适合处理简单的流程控制
◆compile 将字符串类型的代码编译。代码对象能够通过exec语句来执行或者eval进行求值
code1 = 'for i in range(1,10,2):print(i)' compile1 = compile(code1,'','exec') exec(compile1)
code2 = '1+2+3+4' compile2 = compile(code2,'','eval') print(eval(compile2))
和数字相关(14):
数据类型----bool,int,float,complex
◆float:浮点数(有限循环小数和无限循环小数时浮点数)(无限不循环小数不是浮点数)
◆complex:复数 5+12j =复数(其中5是实部,12j是虚部,j是虚部的单位)
进制转换———bin oct hex
◆bin:二进制 用0b表示
◆oct:八进制 用0o表示
◆hex:十六进制 用0x表示
数学运算———abs divmod round pow sum min max
◆divmod 除余法;divmod(7,2)——>(3,1)
◆round 精确值 round(3,1415,2)——>3.14
◆pow 幂运算 pow(2,3)——>8 pow(2,3,3)幂运算之后再取余
◆sum sum(iterable,start)
◆min min(iterable,key,default) min(*args,key,default)
◆max max(iterable,key,default) max(*args,key,default)
和数据结构相关:
列表和元组———list tuple
数据类型:int bool str set tuple dic
数据结构:dic tuple list set str (dic 和 tuple 是python独有的)
相关内置函数-----slice reversed
l = (1,2,3,4,5) sli = slice(1,2,3,4,5) print(l[sli]) reversed :反转,但不改变原来的顺序,而是返回一个迭代器
字符串(9)----str format bytes bytearray memoryview ord chr ascii repr
◆str
◆format 调整格式 format(‘test’,'<20')右对齐
format(‘test’,'>20')左对齐
format(‘test’,'^20')居中
◆bytes 转化成对应编码格式的字节码
print(bytes('你好',encoding = 'GBK')) 结果:b'xc4xe3xbaxc3'
print(bytes('你好',encoding = 'utf-8'))结果:b'xe4xbdxa0xe5xa5xbd'
应用:网络编程;照片和视频也是bytes类型存储;html网页爬取到的也是bytes编码
◆ord 字符按照Unicode转数字 print(ord('a'))———97
◆chr 数字按照Unicode转字符 print(ord('49'))———1
◆ASCII 只要是ASCII中的内容,就打印出来,不是就转换成u
print(ascii('好'))——>u597d
print(ascii('2'))——>2
◆repr 用于%r格式化输出,让一个变量原封不动的输出
数据集合(3)-----dic set frozenset
相关内置函数-----len enumerate all any zip filter map sorted
◆all([可迭代的]) 若可迭代的了吗有空或者0,就返回false
◆zip 返回一个迭代器
l = [1,2,3]
l2 = ['a','b','c']
for i in zip(l,l2):
print(i)
#结果: (1, 'a')
# (2, 'b')
# (3, 'c')
◆filter 相当于一个过滤器过滤出符合条件的值:执行了filter之后的结果集合小于或者等于执行之前的个数,且filter只管筛选,不改变原来的值
filter(函数名,可迭代的) 得到一个迭代器
def is_odd(x): return x % 2==1 ret = filter(is_odd,[1,2,3,4,5,6,7,8,9]) for i in ret: print(i) #结果:[1,3,5,7,9]
def is_no(x): return x and str(x).strip() ret = filter(is_no,[1,'hello','',' ','none',6,7,[]]) l = [] for i in ret: res = l.append(i) print(l) #结果:[1, 'hello', 'none', 6, 7]
◆map 执行前后元素个数不变,值可能改变
格式; map(函数名,可迭代的) 得到一个迭代器
ret = map(abs,[-1,-4,6,-8]) for i in ret: print(i) #结果[1,4,6,8]
◆sorted 排序
sorted(iterable,key,reverse) 其中reverse默认为false 从小到大排序
sort 排序 是再源列表的基础上排序,而sorted是生成一个新列表,不改变原来的列表,但是占用内存
l = [1,-4,6,5,-10] l.sort() print(l) l.sort(key = abs) print(l) #结果[-10, -4, 1, 5, 6] #结果[1, -4, 5, 6, -10]