看起来只是在C++后面多写了一个“/CLI”,然而其意义却远不止于此,google的c++.moderated版上为此还发起了数星期的讨论,在国内大部分人对C++/CLI还不是很了解的情况下,google上面已然硝烟四起...
就像我们作出其它任何选择一样,在选择之前最重要的是先要清楚为什么作出这样或那样的选择——C++/CLI到底提供了哪些优势?为什么我们(标准C++程序员)要选择C++/CLI而不是C#?我们能够得到什么?CLI平台会不会束缚C++的能力?
这些都是来自标准C++社区的疑问。从google上面的讨论看来,更多来自标准C++社区的程序员担心的是C++/CLI会不会约束标准C++的能力,或者改变标准C++发展的方向,也有一部分人对C++/CLI的能力持怀疑态度。另外一些人则是询问C++/CLI能够带来什么。
这些被提出的问题在google上面一一得到了答案。好消息是:情况比乐观的人所想象的或许还要更好一些——
世界改变了吗?
对于谙于标准C++的程序员来说,最为关心的还是:在C++/CLI中,世界还是他们熟悉的那个世界吗?在标准C++的世界里,他们手里的各种魔棒——操作符重载|模板|多继承(语言),STL|Boost|ACE(库)——还能挥舞出五彩缤纷的火焰吗?是不是标准C++到了.NET环境下就像被拔掉了牙的老虎一样——Managed C++ Extension的阴影是不是还笼罩在他们的心头?
答案是:以前你所能做的,现在仍然能做,世界只是变得更广阔了——
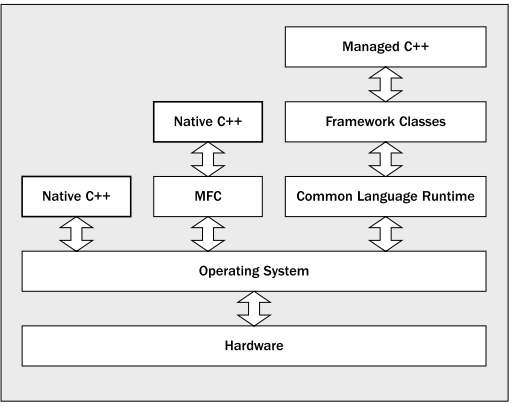
什么是C++/CLI?
l C++/CLI是一集标准化的语言扩展(对标准C++进行扩展),而并非另起炉灶的另一门新语言。所以C++/CLI是标准C++的一个超集。
l C++/CLI是一门ECMA标准[1](并且会被提交给ISO标准化委员会),而不是微软的专有语言。参与C++/CLI标准的修订的有很多组织(或公司),其中包括Edison Design Group,Dinkumware公司等,微软在把C++/CLI标准草案提交给ECMA组织后就放弃了对其的控制权,而是将它作为一份公开发展的标准,任何使用C++/CLI的用户都可以为它的发展提出自己的建议。
l C++/CLI的目的是把C++带到CLI平台上,使C++能够在CLI平台上发挥最大的能力。而并非把C++约束在CLI平台(CLI本身也是ISO标准化的)上。相反,原来标准C++的能力丝毫没有减弱,并且,通过C++/CLI中的标准扩展,C++具有了原来没有的动态编程能力以及一系列的first class的.NET特性。这些扩展并非是专有的,而是以一种标准的方式呈现。
C++/CLI有什么优越性?
l 动态编程和refelection——标准C++是一门非常静态的语言,其原则是尽量在编译期对程序的合法性和逻辑作出检查。而在运行时的动态信息方面,标准C++是有所欠缺的。例如,标准C++在运行期能够对动态对象进行查询的就只有typeid操作符,而typeid()返回的typeinfo类虽然是个唯一标识,但是也仅仅止于“唯一”而已,首先标准C++并未规定typeinfo的底层二进制表示,所以用它作为跨平台的类唯一标识符就不可能了,其次typeinfo类几乎仅仅就表示类名字而已,这种非常“薄”的运行时类型信息阻止了标准C++在分布式领域的能力(IDL就是为了弥补标准C++在运行期类型信息的不足,但是IDL对于拥有元数据的语言如JAVA或C#根本就不是必须的,同时IDL也使C++在分布式领域的使用不那么简易)。由于标准C++的Native特点,所以其代码一经编译便几乎丧失所有的类型信息,从而使得运行期无法对程序本身做几乎任何的改动,换句话说,标准C++的代码一经编译就几乎变成了死的。而C++/CLI改变了这一现状,C++/CLI拥有完备的元数据,允许程序在运行期查询完整的类型信息,并可以由类型信息动态创建对象,甚至可以动态创建类型,添加方法等等,这种强大的运行期的动态特性对于现代应用领域(例如分布式WEB应用)是必须的。
l GC——现在谁也不会说“往C++中加入GC就是终结了C++”这种话了。就连Bjarne Stroustrup也同意如果C++要被用于大型或超大型的软件开发中去,最好要有一个良好的可选的GC支持。GC与否,已经不再是个值得争论的问题,问题是,我们如何把它实现的更好——C++/CLI中的GC是目前最为强大的GC机制之一——分代垃圾收集。GC的好处是可以简化软件的开发模型,在效率并非极其关键的领域,GC可以很大程度上提高生产率。C++/CLI中的GC很重要的一点是:它正是可选的。这一点不同于JAVA或C#,对于后者,GC无处不在,对象只能分配在托管堆上。而在C++/CLI中,如果把你的对象分配在Native Heap上,你就得到和标准C++一样的高效内存管理。如果把对象分配在Managed Heap上,那么该对象的内存就由GC来自动回收。这种混合式的内存管理环境和C++/CLI的定位有关——毕竟,C++/CLI的定位是.NET平台上的系统级编程语言,所以效率以及对底层的控制很重要,故保留了Native Heap。后面你会看到这种编程环境的优点。
l BCL——.NET平台上的基础类库,BCL中丰富的类极大的方便了开发者。C++/CLI可以完全使用BCL中的任何类。
l 可移植性——毫无疑问,可移植性是个至关重要的问题,特别是对于标准C++社群的人们。C++/CLI对这个问题的答案是:“如果你的代码不依赖于本地二进制库,就可以“一次编译,随处运行(在.NET平台上)”(使用“/clr:pure”编译选项将代码编译成可移植的纯MSIL代码)。如果你的代码某部分依赖于本地的二进制库(如C输入输出流库),那么这些部分仍然是源代码可移植的,而其它部分则可以“一次编译,随处运行”。对于标准C++来说,向来保证的只是源代码的可移植性,所以我们并没有失去什么,相反,如果遵守协定——不用本地二进制库,例如,用BCL里的输入输出流库代替C输入输出流库——你就可以得到“一次编译,随处运行”的承诺,也就是说,你的代码经过编译(/clr:pure)后可以在其它任何.NET平台上运行——Unix,Linux下的Mono(移植到Unix,Linux下的.NET),以及FreeBSD,Mac OSX下的Rotor(.NET的开放源代码项目),等等。
习惯了标准C++输入输出流的程序员可能要抱怨了——我们为什么要使用BCL里面的输出输出流?标准的iostream已经很好了!这里其实有一个解决方案,使用 iostream的代码之所以不能“一次编译,随处运行”是因为代码要依赖于本地的二进制lib文件,而如果可以把iostream的实现重新也编译成纯MSIL代码,那么使用它的代码编译后就完全可随处运行了。目前,这是个有待商榷的方案。不过,至少当面对“总得依赖于某些平台相关的二进制代码”这种情况时,可以把平台相关的代码封装成DLL文件——对各个目标平台编译成不同的二进制版本,而程序的其它部分仍然只需一次编译即可,只要使用.NET的P/Invoke就可以对不同平台调用相应的DLL了。
l 效率——作为.NET平台上的系统级编程语言,C++/CLI混合了Native和Managed两种环境。而不象C#那样只能进行托管编程。所以相对来说,C++/CLI可以具有更高的效率——前提是你愿意把效率敏感的代码用极具效率的Native C++来写(当然,谁不愿意呢?)另外,因为标准C++是静态语言,所以作为标准C++的一个超集的C++/CLI能够在编译期得到更多的优化(静态语言总是能够得到更多的优化,因为编译器能够知道更多的信息),从而具有更高的效率。相比之下,C#的编译期优化就弱了很多。
l 混合式的编程环境——这是C++/CLI独有的一种编程环境。你既可以进行高效的底层开发——对应于C++/CLI的标准C++子集,也可以在效率要求不那么严格的地方使用托管式编程以提高生产率。然后把两者平滑的联结在一起,而这一切都在你熟悉的编程语言中完成,你使用你熟悉的编程习惯,熟悉的库,熟悉的语言特性和风格… 不需要从头学习一门新的语言,不需要面对语言之间如何交互的问题。
l 习惯——谁也不能小觑习惯的力量。对于标准C++程序员,如果要在.NET平台上开发,C++/CLI是毫无疑问的首选语言,因为他们在标准C++中积累起来的任何编程技巧,惯用法,以及对库的使用经验,代码的表达方式等等全都可以“移植”到C++/CLI中。C++/CLI保持对标准C++代码的完全兼容,同时以最小最一致的语法扩展提供托管环境下编程的必要语义。
你需要改变什么?
简单的答案是,几乎没有什么需要改变的。是的,你看到“几乎”两个字,总有些不安心:o)事实是:把现存的C++代码移植到C++/CLI环境下不用作任何的改变——我曾经用Native C++写了一个程序,其中用到了STL,Boost里面的Lambda,MPL,Signal等库,然后我把编译选项“/clr”(甚至“/clr:pure”)打开,结果是程序完全通过了编译。而对于使用C++/CLI进行开发的程序员,则需要熟悉的就是.NET平台上的编程范式以及库的使用等,至于以前你所熟悉的标准C++编程的各种编程手法,技巧,各种库的使用——Just Keep Them!
所以,确切的说,你需要的是学习,而不是改变。
C++/CLI——优秀的混血儿
C++/CLI最大的成功在于引入了混合式编程的环境,这是一种非常自由的环境,其中Native和Managed代码可以共存,可以相互沟通,从而完全接纳了标准C++的世界,同时也为另一个世界敞开了大门...
下面就是C++/CLI扩展的几大关键特性——
Handle和gcnew——通往Managed世界的钥匙
还记得在Managed C++ Extension世界里是如何访问托管类的吗?丑陋的__gc关键字无处不在——事实上,不仅是“丑陋”而已(MC++为什么会消亡?)。而在C++/CLI里则引入了一个新的语法元素,名为Handle,写作“^”——你可以把它看成Managed世界里的Pointer(不过不能进行指针算术)。
Handle用于持有Managed Heap上的对象,那么如何在Managed Heap上创建对象呢?原来的new显然不能用,那样会混淆其语义,所以C++/CLI引入了一个对应的gcnew关键字,这两个新的语法元素是操纵Managed世界的关键。现在,使用Handle和gcnew,你就可以和任何托管类进行沟通。另外,既然有了Handle这个Managed指针,当然,基于另外一些重要原因,Managed世界里也要有一个和Native引用类似的语法元素——这就是Managed引用“%”——“^”对应“*”,“%”对应“&”,这样一来,从语法的层面上,指针、引用、以及在堆上创建对象的语法就在两个世界里面对称一致了——哦,等等,还有解引用:对Native Pointer解引用是以“*”,出于模板对形式统一性的要求,对Handle解引用也是用“*”。例如:
void foo(int% a);//传引用
void foo(String^% str);//传引用 SomeManagedClass^ handle = gcnew SomeManagedClass( ... );
handle->someMethod();
SomeManagedClass% ref = *handle;
那么,既然有gcnew,有没有gcdelete呢?答案是没有——虽然它们看起来很对称。理由是对于托管类,根本就不用回收内存。但更为重要的还是,delete的语义不仅仅是回收内存,从广义上说,delete是回收资源的意思,从这个意义上,delete托管类还是Native类的对象都是一个意思。所以,即使你需要delete你的托管类对象,以强制其释放资源,你也应该用delete,这时候托管类的析构函数会被调用——是的,托管类也有析构函数,它的语义和Dispose()一样,但是在C++/CLI里面,你不应该为你的托管类定义Dispose()函数,而总是应该用析构函数来代替它(编译器会根据析构函数自动生成Dispose()函数),因为析构函数有一个最大的优点——
Deterministic Destruction & RAII —— 资源管理的利器
正如每一个熟悉标准C++的程序员所清楚的:由C++构造及析构函数的语义保证所支持的RAII(“资源获取即初始化”[2])技术是资源自动和安全管理的利器,这里的资源可以包括内存,文件句柄,mutex,lock等。通过正确的使用RAII,管理资源的代码可以变得惊人的优雅和简单。相信有经验的C++程序员都熟悉应该类似下面的语句:
void f()
{
ofstream outf(“out.txt”);
out<<”...”;
...
} //outf在这里析构!
这里,程序员根本不用手动清理outf,在函数结束(outf超出作用域)时,outf会自动析构,并释放其所有资源。即使后续的代码抛出了异常,C++语言也能保证析构函数会被调用。事实上,在异常抛出后,栈开解(stack unwind)的过程中,所有已经正确构造起来的局部对象都会被析构。这就为异常环境中资源的管理提供了一种强大而优雅的方式。
而对于C#或Java,代码就没有这么优雅了(特别是java)——C#虽然有using关键字,但是代码仍然显得臃肿,而Java为了保证在异常情况下资源能够正常释放,不得不用了丑陋冗长的try-finally块,在情况变得复杂化时,C#的和Java的代码都会变得越发臃肿。
那么,在C++/CLI中,原来的那种优雅的,靠析构函数来确保资源正确释放的手段还存在吗?答案正如你所期望和熟悉的,RAII仍然可以使用,仍然和标准C++中的能力一样强大:
ref struct D
{
D(){System::Console::WriteLine(“in D::D()
”);}
~D(){System::Console::WriteLine(“in D::~D()
”);}
!D(){System::Console::WriteLine(“Finalized!
”);}
};
int main()
{
D d; // in D::D()
...
} //d在这里析构!in D::~()
ref关键字表示该类是Managed类。所有的ref类都继承自一个公共基类System::Object。至于struct和class的区别仍然和标准C++中的一样。如你所见,对于ref类,你同样可以像在标准C++中那样定义析构函数,该析构函数会在确定的时候被调用——也就是D超出作用域时。一切都与你以前的经验相符。
值得注意的是,对于了解Java或C#的程序员,ref类的析构函数就是Dispose(),你不必也不应该另外手动定义一个Dispose()成员函数。那么,Finalize函数到那里去了?既然ref类创建在托管堆上,那么迟早要被GC回收,这时候,应该被调用的Finalize函数在哪儿呢?C++/CLI为此引入了一个新的语法符号“!D()”,这就是D的Finalize函数,这个“!D”函数被调用的时机是不确定的,要看GC什么时候决定回收该类占用的空间。
~D()析构函数和标准C++里的用法完全相同,释放以前获取的资源。而对!D()的用法则和Finalize函数一样,由于其调用时机是不确定的,所以千万不要依赖于它来释放关键资源(如文件句柄,Lock等)。
为ref类引入~D()和!D()极大的方便了资源管理,也符合了标准C++程序员所熟悉的方式。Herb Sutter[3]把这个能力看成C++/CLI在Managed环境下最为强大的能力之一。
pin_ptr —— 定身法
千万不要小看了pin_ptr的能力,它是Native世界和Managed世界之间的桥梁。在通常情况下,任何时候,GC都会启动,一旦进行GC,托管堆就会被压缩,对象的位置就会被移动,这时候所有指向对象的Handle都会被更新。但是,往往有时候程序员会希望能够把托管堆上的数据(的地址)传给Native接口,比如,为了复用一个Native的高效算法,或者为了高效的做某些其它事情,这种情况下普通的Native指针显然不能胜任,因为如果允许Native指针指向托管堆上的对象,那么一旦发生了GC,这些得不到更新的Native指针将指向错误的位置,造成严重的后果。办法是先把对象“定”在Managed堆上,然后再把地址传给Native接口,这个“定身法”就是pin_ptr——它告诉GC:在压缩堆的时候请不要移动该对象!
array<char>^ arr = gcnew array<char>(3); //托管类
arr[0] = 'C';
arr[1] = '+';
arr[2] = '+';
pin_ptr<char> p = &arr[0]; // 整个arr都被定在堆上
char* pbegin=p;
std::sort(pbegin,pbegin+3); //复用Native的算法!
std::cout<<pbegin[0]<<pbegin[1]<<pbegin[2]; //输出 “++C”
在上面的代码中,我们复用了STL里的sort算法。事实上,既然有了pin_ptr,我们可以复用绝大部分的Native算法。这就为我们构建一个紧凑高效的程序内核提供了途径。
值得注意的是,一旦对象中的成员被定在了堆上,那么该对象整个就被定在了堆上——这很好理解,因为对象移动必然意味着其成员的移动。
还有另一个值得注意的地方就是:pin_ptr只能指向某些特定的类型如基本类型,值类型等。因为这些类型的内存布局都是特定的,所以对于Native代码来说,通过Native指针访问它们不会引起意外的后果。但是,ref class的内存布局是动态的,CLR可以对它的布局进行重整以做某些优化(如调整数据成员排布以更好的利用空间),从而不再是Native世界所能理解的静态结构。然而,这里最主要的问题还是:ref class底层的对象模型和Native世界的对象模型根本就不一致(比如vtbl的结构和vptr的位置),所以用Native指针来接受一个ref class实例的地址并调用它的方法简直肯定是一种灾难。由于这个原因,编译器严格禁止pin_ptr指向ref class的实例。
interior_ptr —— 托管环境下的Native指针
Handle的缺憾是不能进行指针运算(由于其固有的语义要求,毕竟Handle面对的是一个要求“安全”的托管环境),所以Handle的能力较为有限,不如标准C++程序员所熟悉的Native指针那么强大。在STL中,iterator是一种极为强大也极具效率的工具,其底层实现往往用到Native指针。而到了托管堆上,我们还有Native指针吗?当然,原来的形如T*的指针是不能再用了,因为它不能跟踪托管堆上对象的移动。所以C++/CLI中引入了一种新的指针形式——interior_ptr。interior_ptr和Native指针的语义几乎完全一样,只不过interior_ptr指向托管堆,在GC时interior_ptr能够得到更新,除此之外,interior_ptr允许你进行指针运算,允许你解引用,一切和Native指针并无二致。interior_ptr为你操纵托管堆上的数据序列(如array)提供了强大而高效的工具,iterator模式因此可以原版照搬到托管环境中,例如:
template<typename T>
void sort2(interior_ptr<T> begin,interior_ptr<T> end)
{
... //排序算法
for(interior_ptr<T> pn=begin;pn!=end;++pn)
{
System::Console::WriteLine(*pn);
}
}
int main()
{
array<char>^ arr = gcnew array<char>(3);
... //赋值
interior_ptr<char> begin = &arr[0]; //指向头部的指针
interior_ptr<char> end = begin + 3; //注意,不能写&arr[3],会下标越界
sort2(begin,end); //类似STL的排序方式!
}
T*,pin_ptr,interior_ptr——把它们放到一起
T*,pin_ptr,interior_ptr是C++/CLI中三种最为重要的指针形式。它们之间的关系像这样:
强大的Override机制
在标准C++中,虚函数重写机制是隐式的,只要两个函数的签名(Signature)一样,并且基类的同名函数为虚函数,那么不管派生类的函数是否为virtual,都会发生虚函数重写。某种程度上,这就限制了用户对它的派生类的控制能力——虚函数的版本问题就是其一。而在C++/CLI中,你拥有最为强大的override机制,你可以更为明显的来表示你的意图,例如下面的代码:
class B
{
public:
virtual void f() ;
virtual void g() abstract; //纯虚函数,需要派生类重写,否则派生类就是纯虚类
virtual void h() sealed; //阻止派生类重写该函数
virtual void i() ;
}
class D:public B
{
virtual void f() new ; //新版本的f,虽然名字和B::f相同,但是并没有重写B::f。
virtual void h() override ; //错误!sealed函数不能被重写
virtual void k() = B::i ; //“命名式”重写!
}
通过正确的使用这些强大的override机制,你可以获得对类成员函数更强大的描述能力,避免出乎意料的隐式重写和版本错误。不过需要提醒的是,“命名式”重写是一种强大的能力,但是需要谨慎使用,如果使用不当或滥用很可能导致名字错乱。
值类型&封箱和拆箱
如果你来自C#,我几乎可以听到你的叹气声J 的确,在.NET平台上编程,你无可避免的要面对值类型和引用类型的微妙差别以及“疯狂”的隐式封箱——引用类型(对应于ref class)的实例是第一流的对象,继承自公共基类System::Object,拥有方法表,对象头等等。但是值类型(对应于value class)却极为简单,类似于C++中的POD[4]类型,没有方法表和对象头等,值类型应该被分配在栈上,而当你用Handle来持有值类型实例时,它就会被隐式的封箱到托管堆上(因为Handle必须持有一个一流的对象),只有当值类型的实例被封箱到堆上的时候,它才会拥有第一流的对象特征,可以被Object^来引用。
这些都是.NET内在的特性,所有使用.NET平台的语言都必须遵守,从这个意义上说,.NET的确是最高统治者J
幸运的是,情况或许没有你想象的那么糟糕,或许比在C#里面还要好一些——因为C++/CLI中的Handle的语法特征是如此明显,所以你几乎可以立即发现什么地方会出现封箱拆箱(尽管如此,还是要面对一些微妙的情况),我们来看一个例子:
value class V //value关键字表示这是个值类型,值类型应该分配在栈上
{ int i;};
V v; //在栈上创建V的实例
//由于V^必须引用一个“完整”的对象,也就是具有方法表,元数据以及对象头并继承自System::Object公共基类的对象,所以v被隐式封箱到托管堆上。
V^ hv1 = v; //注意,隐式封箱!
V^ hv2 =%v; //也是封箱!把”%”用到值类型上会导致一个Handle,
//所以会封箱,这种形式比较明确!
hv1->i = 10; //改变的不过是堆上封箱后的对象中的i,v的成员i的值并未改变
v = *hv1; //unbox,然后逐位拷贝到栈上,这时候v.i为10
这里你可能意识到了问题——既然用Handle来持有值类型总会导致它被封箱到托管堆上,那么万一我要写一个函数,接受一个(栈上的)值类型实例为实参并改变其成员的值,该怎么办呢?如果使用Handle,那么你所指向的就不是原来的值而是封箱后的对象,从而看起来改变了其成员,其实只不过改变了一个“临时”对象的值而已!所以,Handle在这里应该退居二线,这里是“%”(托管的引用,对应于Native引用——“&”)的用武之地——把一个托管引用绑定到位于栈上的值类型不会引起封箱操作,我们看一个例子:
void adjust(V% ref_v)
{
ref_v.i = 10; //改变ref_v的成员!
}
int main()
{
V v;
adjust(v); //不会引起封箱操作
System::Console::WriteLine(v.i); //打印出10
}
原则是:要修改栈上的值类型实例,优先使用“%”,而不是“^”。这样你将获得最好的效率和程序的正确性。
STL.NET
STL是标准C++中最为优雅,使用最广泛的库之一,标准C++程序员在使用STL的过程中积累了大量的经验。当然,在C++/CLI的扩展世界里,人们也期望能有这样的库,能够沿用他们熟悉以久的经验和技法,这就是STL.NET,为托管世界准备的STL!Stan Lippman[5]在MSDN上的一篇文展STL.NET Primer以简明扼要的方式阐述了STL.NET的优点[6]。
代码的组织
虽然C++/CLI带来了强大的能力,但是对于从标准C++社群来的人们,则更愿意将他们的标准C++代码和使用了C++/CLI扩展特性的代码隔离开来,以便让前者可以在不同平台上移植,而不是绑定到CLI平台。毕竟,用C++/CLI编程并不意味着你的所有代码都是和C++/CLI的扩展特性相关的——C++/CLI的定位是系统级编程,所以可以想象会有很大一部分人会非常愿意用标准C++来写效率关键的代码部分,例如你可以用标准C++来写高效的算法,而这些算法应该可以被复用到其它Native环境中去。那么,如何把这些标准C++代码和C++/CLI的扩展特性隔离开来呢?如何隔离?不同编译单元之间的界限就是最好的栅栏——把你的标准C++代码放在独立的头文件和源文件中,把使用了C++/CLI扩展的代码放在另外的头文件和源文件中。并且,尽量不要在你的Native class中使用CLI的语法特性,如property,delegate,index等,尽量不要让你的Native Class继承自ref Class。总之,尽量保证代码结构的清晰,你将得到最大程度上的可移植性。
小结
C++/CLI是一个创举,它把托管环境和Native环境整合在一起,使开发者同时拥有了“上天入地”的强大能力。显而易见,微软为了C++/CLI花费了大量的心力。以使得标准C++程序员能够平滑的过渡到C++/CLI上面。所谓平滑,就是能够尽量保证原来的编程技巧,习惯,范式等,它的确做到了。面对C++/CLI,已经不是争论该不该学习的问题,而是如何让它发挥更大的能量的问题。
[1] C++/CLI标准下载:http://msdn.microsoft.com/visualc/homepageheadlines/ecma/default.aspx。
[2] 见Bjarne Stroustrup的《The C++ Programming Language》
[3] Herb Sutter’s Blog: http://www.pluralsight.com/blogs/hsutter/default.aspx或http://blogs.msdn.com/hsutter/。
[4] Plain Old Data类型,简单的说就是纯粹一集数据的聚合体。没有虚函数,构造函数,析构函数等“C++”特性。
[5] Stan Lippman的 Blog: http://blogs.msdn.com/slippman。
[6] STL.NET Primer:http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dnvs05/html/stl-netprimer.asp
转载于:https://www.cnblogs.com/bile/p/8081497.html