第2章 词法分析的理论与实践
词法分析是编译过程的第一步,也是编译过程必不可少的步骤。编译过程中执行词法分析的程序称为词法分析器。本章主要介绍词法分析器的手动构造和自动构造的原理。
2.1 词法分析器的需求分析
本节首先介绍词法分析器的功能及其输出的单词符号的表示方式,然后研究将词法分析独立出来的原因。
2.1.1 词法分析器的功能
词法分析器的功能是从左往右逐个字符地对源程序进行扫描,然后按照源程序的构词规则识别出一个个单词符号,把作为字符串的源程序等价地转化为单词符号串的中间程序。因此词法分析器又叫作扫描器。单词符号是程序设计语言中基本的语法单元,通常分为5种:
1)关键字(又称基本字或保留字):程序设计语言中定义的具有固定意义的英文单词,通常不能用作其他用途,如C语言中的while、if、for等都是关键字。
2)标识符:用来表示名字的字符串,如变量名、数组名、函数名等。
3)常数:包括各种类型的常数,如整型常数386、实型常数0.618、布尔型常数TRUE等。
4)运算符:又分为算术运算符,如+、-、*、/等;关系运算符,如=、>=、>等;逻辑运算符,如 or、not、and等。
5)界符:如“,”“;”“(”“)”“:”等。
在上面所给出的5种单词符号类中,关键字、运算符和界符是程序设计语言提前定义好的,因此它们的数量是固定的,通常只有几十个或者上百个。而标识符和常数是程序设计人员根据编程需要按照程序设计语言的规定构造出来的,因此数量即便不是无穷,也是非常大的。
词法分析程序输出的单词符号通常用二元式(单词种别,单词符号的属性值)表示。其中:
1)单词种别。单词种别表示单词种类,常用整数编码,这种整数编码又称为种别码。至于一种程序设计语言的单词如何分类、怎样编码,主要取决于技术上的方便。一般来说,基本字可“一字一种”,也可将其全体视为一种;运算符可“一符一种”,也可按运算符的共性分为几种;界符一般采用“一符一种”分法;标识符通常统归为一种;常数可统归为一种,也可按整型、实型、布尔型等分为几种。
2)单词符号的属性值。单词符号的属性值是反映单词特征或者特性的值,是编译中其他阶段所需要的信息。如果一个种别只含有一个单词符号,那么其种别编码就完全代表了自身的值,因此相应的属性值就不需要再单独给出。如果一个种别含有多个单词符号,那么除了给出种别编码之外还应给出单词符号自身的属性值,以便把同一种类的单词区别开来。例如,对于标识符,可以用它在符号表的入口指针作为它自身的值;而常数也可用它在常数表的入口指针或者其二进制值作为它自身的值。
例2.1 假定基本字、运算符、界符都是一符一种,词法分析器只给出种别编码不给出属性值,标识符和常量分别单列一种。考虑如下的程序段
if(a>1)
b=10;
则它所输出的单词符号是:
(1,-)
(29,-)
(10,指向a的符号表项的指针)
(23,-)
(11,'1'的二进制)
(30,-)
(10,指向b的符号表项的指针)
(17,-)
(11,'10'的二进制)
(26,-)
其中1为关键字if的种别编码,10为标识符的种别编码,11为常数的种别编码,26、29和30分别为界符“;”“(”和“)”的种别编码,17和23分别为运算符“=”和“>”的种别
编码。
2.1.2 分离词法分析的原因
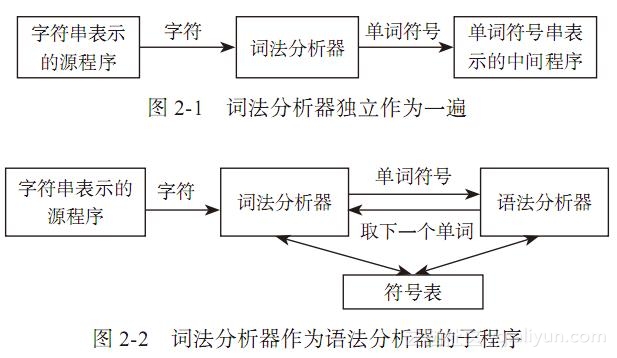
可以将词法分析独立地作为“一遍”来完成,此时词法分析器读入整个源程序,将字符串形式的源程序改造成单词符号串形式的中间程序,并将所得到的中间程序存放于文件中,待语法分析程序工作时再从文件中读入这些中间程序作为其输入,如图2-1所示。
也可将词法分析和语法分析放在同一遍中执行,此时将词法分析程序设计为一个独立子程序,在进行语法分析时,每当语法分析程序需要新单词符号,便调用该子程序,每调用一次这个子程序,其便从源程序字符串中识别出一个单词符号交给语法分析程序,如图2-2所示,采用这种设计方法,省掉了中间文件上的存取工作。
编译程序通常采用第二种处理结构。无论采用哪种结构,词法分析程序作为一个独立的阶段存在,主要是基于以下几方面的考虑:
1)简化编译器的设计,降低语法分析的复杂性。词法分析要比语法分析简单很多,在对源程序字符串进行扫描的过程中,词法分析程序可以对源程序做一些必要的预处理,比如删除其中的注释和空格等不影响程序的语法结构和执行语义的元素,这样便于语法分析程序致力于语法分析,降低其分析复杂性。
2)提高编译效率。编译的大部分时间花费在扫描源程序字符串来识别单词符号上,把词法分析独立出来,可以采用专门的技术读字符和分离单词以加快编译速度。再者,单词的结构便于采用有效的方法和工具进行描述和识别,进而可实现词法分析器的自动生成。
3)增加编译器的可移植性。与机器有关的特征以及语言字符集中的非标准符号的处理可以放在词法分析器中处理,而不影响编译器其他部分的设计。