Hive是基于Hadoop的一个数据仓库工具,使用hive的优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析(可加强具体了解统计目标和分析方法)。
可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
还可以将 SQL 语句转换为 MapReduce 任务进行运行,通过自己的 SQL 去 查询分析需要的内容,这套 SQL 简称HQL。
Hive将元数据存储在数据库(RDBMS)中,
比如MySQL、Derby中。
Hive有三种模式连接到数据,其方式是:
单用户模式,多用户模式和远程服务模式。
(也就是内嵌模式、本地模式、远程模式)。
Hive特点:
1.可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
2. 延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
3.容错
良好的容错性,节点出现问题SQL仍可完成执行。
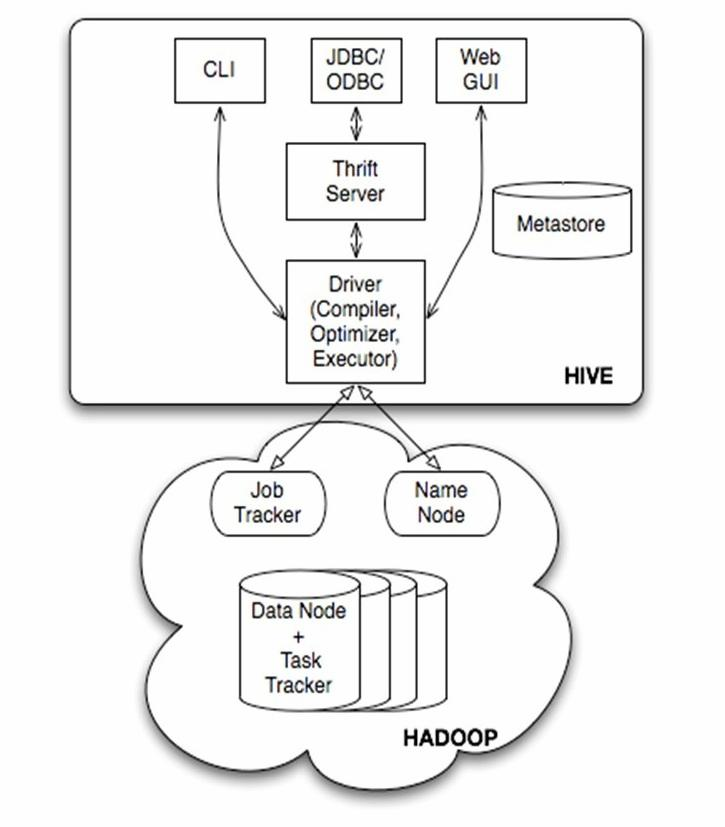
Jobtracker是hadoop1.x中的组件,它的功能相当于hadoop2.x中的: Resourcemanager+AppMaster
TaskTracker 相当于: Nodemanager + yarnchild
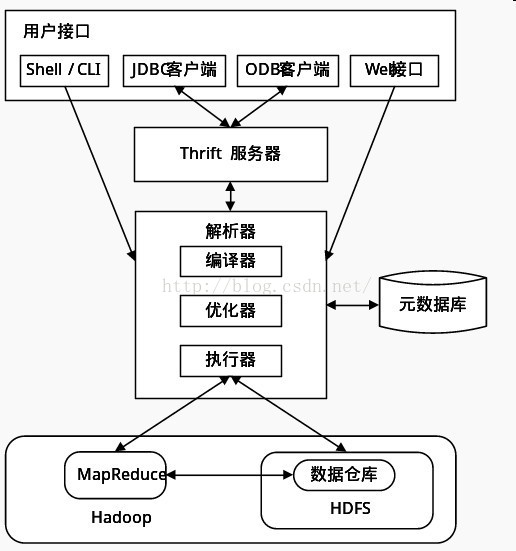
从上图可以看出,Hive体系结构大概分成一下四个部分:
1.用户接口:
包括 CLI, Client, WUI:
CLI为shell命令行,Cli 启动的时候,会同时启动一个 Hive 副本。
Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。
WUI 是通过浏览器访问 Hive。
2.元数据存储:通常是存储在关系数据库如 mysql, derby 中
3.解释器、编译器、优化器、执行器:
完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。
生成的查询计划存储在 HDFS 中,并在随后有MapReduce 调用执行。
4.Hadoop:
Hive中数据用 HDFS 进行存储,利用 MapReduce 进行计算。