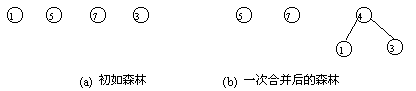树是一种“一对多”的数据结构,是n(n≥0)个结点的有限集,其中n=0时称为空树
树满足的一些性质和概念
- n>0时,根结点唯一
- n>1时,除去根结点的其他结点构成若干个互不相交的有限集T1,T2...,其中每一个集合又是一棵树,称为根的子树
- 结点拥有的子树数称为结点的度(Degree),度为0的结点称为叶子结点
- 树的度是树内各结点的度的最大值
- 结点的层数是从根开始定义起,根为第一层,根的孩子是第二层,以此类推。树中结点的最大层次称为树的深度(Depth)或高度
- 如果各子树看成从左至右不可互换的,则称为有序树,否则为无序树
- 森林是互不相交的树的集合,某个结点的子树可以看做是森林
树的存储结构:双亲表示法、孩子表示法、孩子兄弟表示法(这个表示法充分利用了二叉树的特性和算法来处理这棵树)
二叉树的定义:每个结点最多有两个子树的树结构。通常子树被称作“左子树”和“右子树”
二叉树满足的一些性质和概念
- 二叉树不存在度大于2的结点
- 左右子树是有顺序的,即使某结点只有一棵子树,也要区分它是左子树还是右子树
- 根据(2)所说,二叉树具有五种基本形态:空二叉树、只有一个根节点、只有左子树、只有右子树、左右子树都有
- 二叉树第i层上至多有2^(i-1)个结点(i≥1)
- 深度为k的二叉树至多有2^k - 1个结点(k≥1),此时为满二叉树
- 对任何一棵二叉树T,如果其叶子结点数为n0,度为2的结点数为n2,则n0 = n2 + 1。这个的推导:设结点数为n,可以知道结点间连接线数为n-1。于是有两个式子:n-1 = n1 + 2*n2 和 n = n0 + n1 +n2,联合解出n0 = n2 + 1
- 具有n个结点的完全二叉树的深度为log2 n向下取整然后加1 => 通过满二叉树2^n - 1可以推出
- 对于完全二叉树,在有左右子结点的情况下,设根结点的编号是n(这个编号从1开始),则左孩子的编号是2n,右孩子的编号是2n+1
特殊的二叉树
- 斜树:所有的结点都只有左子树或右子树,特点是结点的个数与二叉树的深度相同
- 满二叉树:所有的分支结点(非叶子)都存在左子树和右子树,并且所有的叶子都在同一层(完全对称,非叶子结点的度一定是2,结点数是2^n - 1)
- 完全二叉树:允许在满二叉树中去掉若干个最后的结点,但是存在的结点序号一定与满二叉树位置一致(比满二叉树要求低一点,所以满二叉树一定是完全二叉树,反之则不成立。如果某结点的度为1,则该结点只有左孩子)
二叉树的存储结构
1) 顺序存储:根据二叉树概念第8点,可以知道完全二叉树的父结点和孩子结点是有算术关系的,所以用一维数组存储很方便。但是对于一般的二叉树则会耗费很多存储空间(如有5层的斜树,只有1,2,4,8,16这几个索引值是存了值的,其他空间都没有作用)
2) 二叉链表:一个结点用(左孩子指针, 右孩子指针, 数据域)来表示,如果没有孩子结点,则指针域指向空即可,可以节省很多空间(当然如果有必要指向父结点,也可以构造三叉链表,略) ,以下是链表结构体定义:
typedef struct BiTNode
{
TElemType data;
struct BiTNode *lchild, *rchild;
} BiTNode, *BiTree;
二叉树的遍历
由于(链表结构的)二叉树没有明确的“次序”一说(不存在唯一的前驱和后继关系),所以只要是按照某种次序依次访问二叉树中所有结点,使得每个结点被访问且仅被访问一次就是二叉树的遍历。
习惯的方法有四种:前序遍历,中序遍历,后序遍历,层序遍历
前序遍历:先访问根结点,然后前序遍历左子树,再前序遍历右子树
=> 注意到这里是一个递归的过程,后面的遍历方法采用的也是这个思想。另外,这个“序”针对的是根结点的访问时机
中序遍历:先中序遍历根结点的左子树,然后访问根结点,再中序遍历右子树
后序遍历:先后序遍历根结点的左子树,然后后序遍历右子树,再访问根结点
层序遍历:从上到下从左到右对结点逐个访问
以上的遍历方法都是把树中的结点变成某种意义的线性序列,给程序的实现带来好处。以下例子:

# 代表指针域null
前序遍历:ABDCE
中序遍历:DBAEC
后序遍历:DBECA
层序遍历:ABCDE
前序遍历算法示例(其他算法可以参考这个)
void PreOrderTraverse(BiTree T)
{
if(T == NULL) return;
access(T->data); // 访问结点
PreOrderTraverse(T->lchild); // 递归前序遍历左子树
PreOrderTraverse(T->rchild); // 递归前序遍历右子树
}
有个性质:已知中序遍历和其他两种遍历中的其中一种,可以唯一确定一棵二叉树。(证明略)
二叉树的建立
需要引入“扩展二叉树”的概念,其实就是在所有的叶子结点后添加一个空指针的标记,用#表示,就如上面的图所示。
上面的图前序遍历的结果是(包括#的情况):ABD###CE###,将这段结果输入到程序中,即可生成二叉树结构:
void CreateBiTree(BiTree *T)
{
TElemType ch;
scanf("%c", &ch);
if(ch == '#') *T = NULL;
else{
*T = (BiTree) malloc (sizeof(BiTNode));
if(! *T) exit(OVERFLOW);
(*T)->data = ch;
CreateBiTree(& (*T)->lchild);
CreateBiTree(& (*T)->rchild);
}
}
以上是基于前序遍历的建立二叉树的函数。
线索二叉树
上面的CreateBiTree方法有一个浪费空间的点,就是有很多空指针域的存在(虽然已经比顺序结构少了很多),可以把这些空间利用起来。
首先要知道有多少个空指针域:对于一个有n个结点的二叉链表,一共有2n个指针域,而n个结点对应有n-1条分支线数,所以就存在n+1个空指针域
由于遍历是根据前面的4个算法来得到结果,但是遍历之后由于没有记录信息,所以不能直接知道某个结点的前驱和后继是谁,可以考虑在创建就(利用这几个空指针域)记住这些前驱和后继,我们把这种指向前驱和后继的指针称为线索,加上线索的二叉链表称为线索链表,响应的二叉树叫线索二叉树。对二叉树以某种次序遍历使其变为线索二叉树的过程称做是线索化。
过程:对于空的左孩子指针域,指向该父结点的前驱;对于空的右孩子指针域,指向该父结点的后继。另外,需要一个区分标志,用于辨别到底下一个是左右孩子还是前驱后继,于是,结构体变成了(lchild, rchild, ltag, rtag, data),其中tag为0的时候表示指向该结点的左右孩子,为1的时候指向前驱后继。
例:中序遍历线索化的过程
BiThrTree pre; // 全局变量,指向刚刚访问的结点
// 中序遍历
void InThreading(BiThrTree p)
{
if(p)
{
InThreading(p->lchild);
if(!p->lchild)
{
p->LTag = Thread; // 这是个常量
p->lchild = pre;
}
if(!pre->rchild)
{
pre->RTag = Thread;
pre->rchild = p;
}
pre = p;
InThreading(p->rchild);
}
}
如果所用的二叉树需经常遍历或查找结点时需要某种遍历序列中的前驱和后继,那么采用线索二叉链表的存储结构就是非常不错的选择
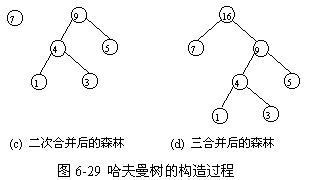
赫夫曼树
概念:给定n个权值作为n的叶子结点,构造一棵二叉树,若带权路径长度(WPL)达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树
路径长度:从树的一个结点到另一个结点之间的分支构成两个结点之间的路径,路径上的分支数目称为路径长度(其实就是两个结点之间的线有多少根)
树的路径长度:从树根到每一个结点的路径长度之和
结点之间的带权路径长度:从树的一个结点到另一个结点之间的分支上的权值的总和
树的带权路径长度:树中所有叶子结点的带权路径长度之和(需要使用到这个)
赫夫曼树(最优二叉树)的作用是优化对树中结点的访问次数,使权值大(通常是访问次数多的)尽可能放在靠近根结点的位置 => 树的带权路径长度最短
构造方法: