一、运算符及优先级
Python 运算符(算术运算、比较运算、赋值运算、逻辑运算、成员运算)
|
运算符 |
描述 |
实例,a=20,b=10 |
|
+ |
加 |
a+b输出结果30 |
|
- |
减 |
a-b输出结果10 |
|
* |
乘 |
a*b 输出结果200 |
|
/ |
除 |
a/b输出结果2 |
|
% |
取模 |
a/b输出结果0 |
|
** |
取幂 |
a**b输出结果20的10次方 |
|
// |
取整除 |
9/2输出结果4,9.0/2.0输出结果4.0 |
2.比较运算符
|
运算符 |
描述 |
实例 |
|
== |
等于 |
(a==b)返回False |
|
!= |
不等于 |
(a!=b)返回True |
|
<> |
不等于 |
(a<>b)返回True #3.x测试错误 |
|
> |
大于 |
(a>b)返回True |
|
>= |
大于等于 |
(a>=b)返回True |
|
< |
小于 |
(a<b)返回False |
|
<= |
小于等于 |
(a<=b)返回False |
3.赋值运算符
|
运算符 |
描述 |
实例 |
|
= |
简单的赋值运算符 |
c=a+b,将a+b的运算结果赋值给c(30) |
|
+= |
加法赋值运算符 |
c+=a 等效于c=c+a |
|
-= |
减法赋值运算符 |
c-=a 等效于c=c-a |
|
*= |
乘法赋值运算符 |
c*=a 等效于c=c*a |
|
/= |
除法赋值运算符 |
c/=a 等效于c=c/a |
|
%= |
取模赋值运算符 |
c%=a 等效于c=c%a |
|
**= |
取幂赋值运算符 |
c**=a 等效于c=c**a |
|
//= |
取整除赋值运算符 |
c//=a 等效于c=c//a |
4.逻辑运算符
|
运算符 |
描述 |
实例 |
|
and |
布尔“与” |
(a and b)返回True |
|
or |
布尔“或” |
(a or b)返回True |
|
not |
布尔“非” |
not(a and b)返回False |
5.成员运算符
|
运算符 |
描述 |
实例 |
|
in |
如果再指定的序列中找到值,返回True,否则返回False |
x在y序列中,如果x在y序列中返回True |
|
not in |
如果再指定的序列中找不到值,返回True,否则返回False |
x在y序列中,如果x在y序列中返回False |
a="abcdefg"
b="b"
if b in a :
print("b元素在a字符串中")
else:
print("b元素不在a字符串")
6.位运算符
|
运算符 |
描述 |
实例 a=00001010 b=00010100 |
|
& |
按位与运算符 |
(a&b)输出结果0 |
|
| |
按位或运算符 |
(a|b)输出结果30 |
|
^ |
按位异或运算符 |
(a^b)输出结果30 |
|
~ |
按位取反运算符 |
~10输出结果-11 |
|
<< |
左移运算符 |
a<<2输出结果40 |
|
>> |
右移运算符 |
a>>2输出结果2 |
7.身份运算符
|
运算符 |
描述 |
实例 |
|
is |
is是判断两个标识符是不是引用自一个对象 |
x is y,如果id(x)等于id(y),is返回结果1 |
|
is not |
is not是判断两个标识符是不是引用不同对象 |
x is not y,如果id(x)不等于id(y),is not返回1 |
8.三目运算符
三目运算符可以简化条件语句的缩写,可以使代码看起来更加简洁,三目可以简单的理解为有三个变量,它的形式是这样的 name= k1 if 条件 else k2 ,如果条件成立,则 name=k1,否则name=k2,下面从代码里面来加深一下理解,从下面的代码明显可以看出三目运算符可以使代码更加简洁。
a=1
b=2
if a<b: #一般条件语句的写法
k=a
else:
k=b
k=a if a<b else b #三目运算符的写法
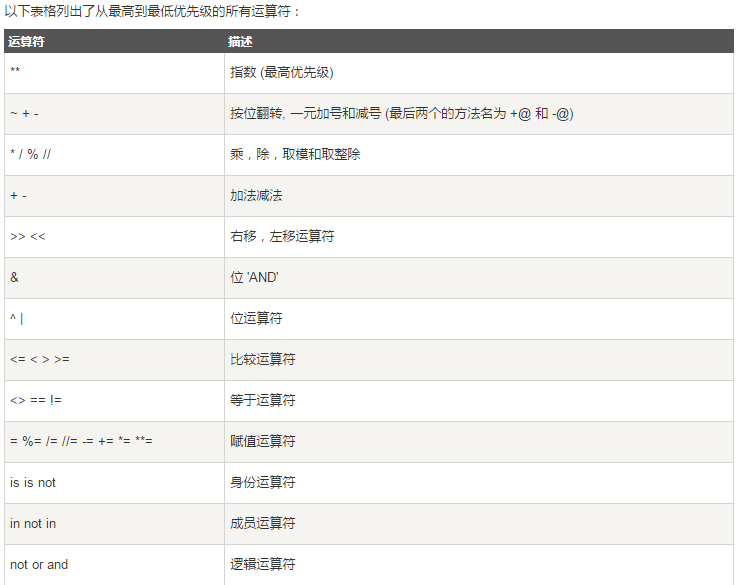
9.运算符优先级
二、数据类型及常用操作(数字, bool, str, list, tuple, dict, set)
数据类型:数字、字符串、布尔值、字符串、列表、元组、字典、集合
序列:字符串、列表、元组
散列:集合、字典
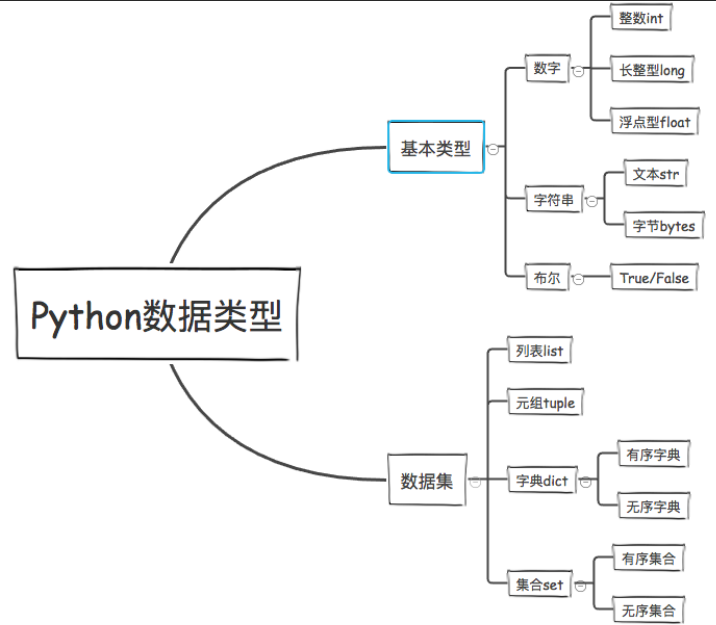
查看不同数据类型的方法,dir(),列如:
1、数字
int
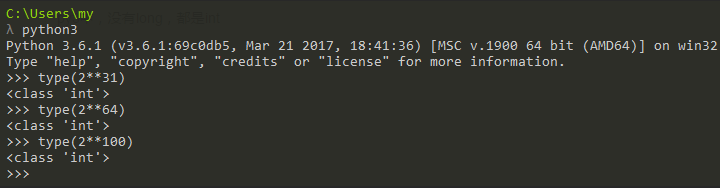
Python可以处理任意大小的正负整数,但是实际中跟我们计算机的内存有关,
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807。
long
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
注意:在Python3里不再有long类型了,全都是int。
py2中

py3中
float
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x109和12.3x108是相等的。浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
2、布尔值(bool)
布尔类型很简单,就两个值 ,一个True(真),一个False(假),,主要用记逻辑判断
也可以将bool值归类为数字,是因为我们也习惯用1表示True,0表示False
bool([x]) Return a Boolean value, i.e. one of True or False. x is converted using the standard truth testing procedure. If x is false or omitted, this returns False; otherwise it returns True. The bool class is a subclass of int (see Numeric Types — int, float, complex). It cannot be subclassed further. Its only instances are False and True (see Boolean Values).
# 参数如果缺省,则返回False
print(bool()) # False
# 传入布尔类型时,按原值返回
print(bool(True)) # True
print(bool(False)) # False
# 传入字符串时,空字符串返回False,否则返回True
print(bool('')) # False
print(bool('0')) # True
# 传入数值时,0值返回False,否则返回True
print(bool(0)) # False
print(bool(0,)) # False
print(bool(1)) # True
# 传入元组、列表、字典等对象时,元素个数为空返回False,否则返回True
print(bool(())) # False
print(bool((0,))) # True
print(bool([])) # False
print(bool([0])) # True
print(bool({})) # False
print(bool({'name':'jack'})) # True
3、字符串(str)
字符串特性:有序、不可变
在Python中,加了引号的字符都被认为是字符串!
那单引号、双引号、多引号有什么区别呢? 单双引号木有任何区别,只有下面这种情况 你需要考虑单双的配合
msg = "My name is jack, I'm 22 years old!"
多引号什么作用呢?作用就是多行字符串必须用多引号
msg = ''' 我在学python, python功能很强大, 你是否要一起学习呢? ''' print(msg)
常用操作
s="abcdef ghg k"
print(s.title()) #将字符串转换成标题,输出 Abcdef Ghg K
print(s.capitalize()) #将字符串首字母大写,输出 Abcdef ghg k
print(s.count('d',0,len(s))) #计算出子串 'd'在母串中出现的次数,默认是在整个母串中查找,
#可以在后面跟两个参数指定起始位置查找,这里我指定了在(0,len(s))中查找,
#其中len(s)代表获取字符串长度
print(s.startswith('a')) #判断字符串是否以什么开头,这里输出True,
print(s.find('g',0,len(s))) #查找子串第一次在母串中出现的位置,这里输出7,同样可以自己指定位置范围来搜查
print(s.upper()) #将字符串转换成大写,这里输出ABCDEF GHG K
print(s.join(['a','b','c'])) #用字符串 s 来连接列表['a','b','c'] 输出 aabcdef ghg kbabcdef ghg kc
print(s.strip()) #移除两侧空格
print(s.split()) #分割字符串,返回一个列表 这里输出['abcdef', 'ghg', 'k']
print(s.replace('g','G',1)) #替换,默认全部替换,可以设置为1,只替换一次,这里只替换一次输出abcdef Ghg k
print(s[0:4]) #切片,[0:4]代表将字符串s的前面4位取出来,这里输出 abcd
4、空值(None)
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
5、列表(list)
列表是Python内置的一种数据类型,是一种有序的集合,可以放任何数据类型,可对集合进行方便的增删改查操作。
查看列表的方法,help(list)
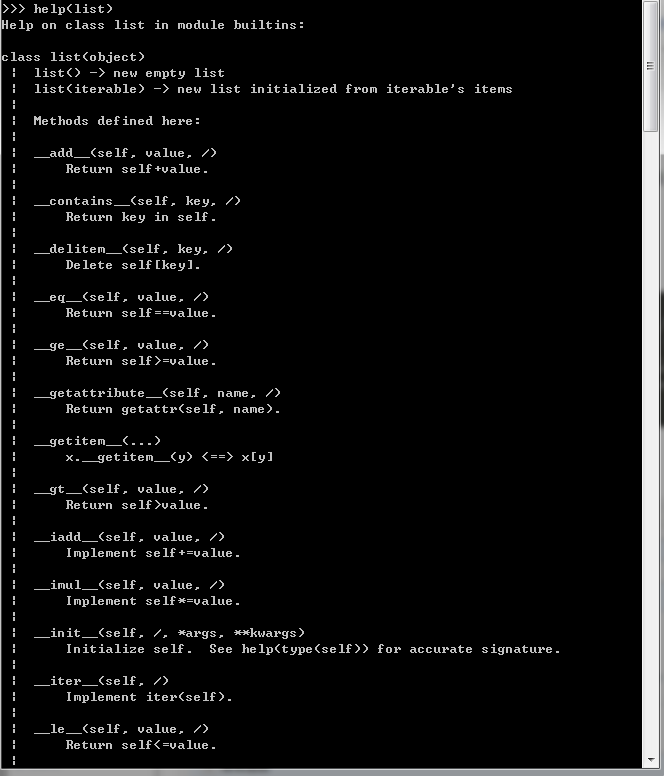
更简便看列表的方法:dir(列表)

l=['a','b','cc',4] #定义一个列表
l.append(5) #添加一个元素,l=['a', 'b', 'cc', 4, 5]
l.pop() #从尾部删除一个元素,l=['a', 'b', 'cc', 4]
l.remove('a') #从列表中移除 'a',l=['b', 'cc', 4]
l.extend(['gg','kk']) #添加一个列表['gg','kk'], l=['b', 'cc', 4, 'gg', 'kk']
l.reverse() #反转一个列表,l=['kk', 'gg', 4, 'cc', 'b']
print(l.count('kk')) #某元素出现的次数,输出 1
print(l.index('gg')) #元素出现的位置,输出 1
for i in l: #循环输出列表元素
print(i)
print(l[0:4:2]) #列表切片,以步长2递增,输出['kk', 4]
6、元组(tuple)
不可修改,是只读列表
元组中不仅可以存放数字、字符串,还可以存放更加复杂的数据类型
元组本身不可变,如果元组中还包含其他可变元素,这些可变元素可以改变
uple和list非常类似,但是tuple一旦初始化就不能修改,tuple也是有序的,tuple使用的是小括号标识。
t=('a','b','b','c') #定义一个元组
print(t.index('b')) #索引出元素第一次出现的位置,还可以指定在某一范围里查找,这里默认在整个元组里查找输出1
print(t.count('b')) #计算元素出现的次数,这里输出2
print(len(t)) #输出远组的长度,这里输出4
for i in t:
print(i) #循环打印出元组数据
print(t[1:3]) #切片 输出('b','b')
7、字典(dict)
字典是无序的,使用键-值(key-value)存储,具有极快的查找速度。
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
d.get('Bob') #根据key获取values,如果不存在返回None,这里输出75
d.pop('Bob') #根据键删除某一元素 d={'Michael': 95, 'Tracy': 85}
d['Jason']=99 #新增元素 d={'Michael': 95, 'Tracy': 85, 'Jason': 99}
print(len(d)) #输出字典长度,这里输出3
print('Jason' in d) #python3 中移除了 has_key,要判断键是否存在用in
for i in d:
print(i) #循环默认按键输出
for i in d.values(): #循环按值输出
print(i)
for k,v in d.items(): #循环按键值输出
print(k,v)
8、集合(set)
set是一个无序(不支持索引和切片)而且不重复的集合,有些类似于数学中的集合,也可以求交集,求并集等,下面从代码里来看一下set的用法,如果对这些用法不太熟悉的话,可以照着下面的代码敲一遍。
s1={1,2,3,1} #定义一个set s1 如果s1={}为空则默认定义一个字典
s2=set([2,5,6]) #定义一个set s2
print(s1) #s1={1,2,3} 自动去除重复的元素
s1.add(5) #s1={1,2,3,5} 添加一个元素
print(s1)
s3=s1.difference(s2) #返回一个s1中存在而不存在于s2的字典s3,s3={1,3},而s1并没有改变
print(s3)
s1.difference_update(s2) #s1跟新成上面的s3 s1={1,3}
s1.discard(1) #删除元素1,不存在的话不报错 s1={3}
print(s1)
s1.remove(3) #删除元素3,不存在的话报错 s1={}
print(s1)
s1.update([11,2,3]) #跟新s1中的元素,其实是添加 s1={11,2,3}
print(s1)
k=s1.pop() #删除一个元素,并将删除的元素返回给一个变量,无序的,所以并不知道删除谁
s1={1,2,3,4} #这里重新定义了集合s1,s2
s2={3,4,5,6}
r1=s1.intersection(s2) #取交集,并将结果返回给一个新的集合 r1={3,4}
print(r1)
print(s1)
s1.intersection_update(s2) #取交集,并将s1更新为取交集后的结果 s1={3,4}
print(s1)
k1=s1.issubset(s2) #s1是否是s2的的子序列是的话返回True,否则False 这里k1=true
print(k1)
k2=s1.issuperset(s2) #s1是否是s2的父序列 k2=False
k3=s2.isdisjoint(s1) #s1,s2,是否有交集,有的话返回False,没有的话返回True
print(k3)
s1.update([1,2]) #s1={1,2,3,4}
r3=s1.union(s2) #取并集将结果返回给r3 r3={1,2,3,4,5,6}
print(r3)
r2=s1.symmetric_difference(s2) #r2=s1并s2-s1交s2 r2={1,2,5,6}
print(r2)
s1.symmetric_difference_update(s2) #s1更新为 s1并s2 - s1交s2 s1={1,2,5,6}
print(s1)
三、深浅拷贝
浅拷贝会创建一个新的对象,只拷贝了原列表中嵌套列表的内存地址(里面的嵌套列表与原列表指向同一个内存地址),嵌套列表中的内容改变了,所以就跟随改变了;
对于不可变数据类型,深浅拷贝都只拷贝了引用,对于可变数据类型,深浅拷贝都会创建一个新的对象。
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的。
赋值,只是创建一个变量,该变量指向原来内存地址
浅拷贝,在内存中只额外创建第一层数据
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
在python中,对象赋值实际上是对象的引用。当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用。
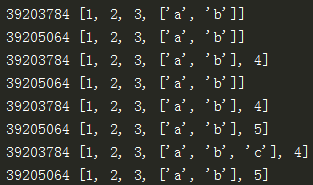
lia = [1,2,3,["a","b"]]
一般有三种方法:
(1)直接赋值,传递对象的引用而已,原始列表改变,被赋值的lib也会做相同的改变
lia = [1,2,3,["a","b"]]
lib = lia
print(id(lia), lia)
print(id(lib), lib)
lia.append(4)
print(id(lia), lia)
print(id(lib), lib)
lib.append(5)
print(id(lia), lia)
print(id(lib), lib)
lia[3].append('c')
print(id(lia), lia)
print(id(lib), lib)
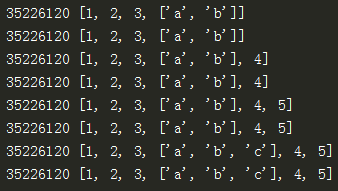
(2)copy浅拷贝,没有拷贝子对象,所以原始数据改变,子对象会改变
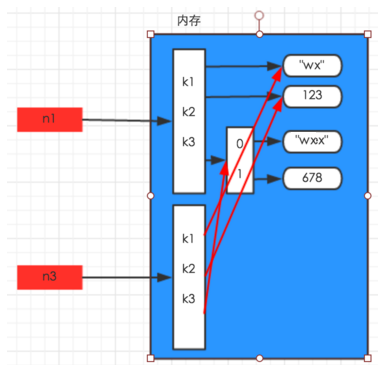
import copy
lia = [1,2,3,["a","b"]]
lib = copy.copy(lia)
print(id(lia), lia)
print(id(lib), lib)
lia.append(4)
print(id(lia), lia)
print(id(lib), lib)
lib.append(5)
print(id(lia), lia)
print(id(lib), lib)
lia[3].append('c')
print(id(lia), lia)
print(id(lib), lib)
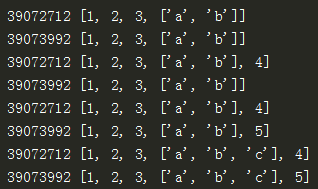
(3)深拷贝,包含对象里面的子对象的拷贝,所以原始对象的改变不会造成深拷贝里任何子元素的改变
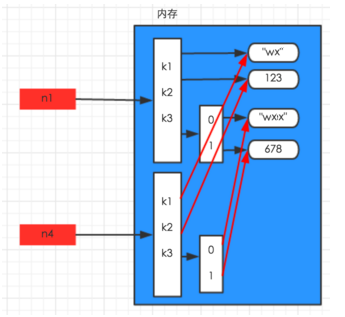
import copy
lia = [1,2,3,["a","b"]]
lib = copy.deepcopy(lia)
print(id(lia), lia)
print(id(lib), lib)
lia.append(4)
print(id(lia), lia)
print(id(lib), lib)
lib.append(5)
print(id(lia), lia)
print(id(lib), lib)
lia[3].append('c')
print(id(lia), lia)
print(id(lib), lib)
四、练习题(参考答案已放在Q群文件中)
1.一个列表,找出只出现一次的元素。
2.列表 [11,22,33,44,55,66,77,88,99],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。即: {'k1': 大于66的所有值, 'k2': 小于66的所有值}
3.两个列表,其中一个列表比另外一个列表多一个元素,写一个函数,返回这个元素
4.三级菜单
可依次选择进入各子菜单
可从任意一层往回退到上一层
可从任意一层退出程序