本文内容整理来自【敏捷运维大讲堂】蒋君伟老师的线上直播分享。分别从以下3个维度来分享:1、云时代监控分析的窘境;2、使用标签标记监控数据的维度;3、监控数据应用场景。
云时代监控分析的窘境
在虚拟化与容器技术广泛应用的情况下,运维对象大规模地增长,监控平台每天存储的指标都以亿计,所以监控数据如今已经成了大数据。传统的监控工具在这种场景下,对于数据的提取分析,已经力不从心,反而成为了运维的负担。
我们用一个典型的互联网档案分析应用举例说明:

这个应用支持容灾与负载均衡,它部署在三个数据中心,并同时提供服务;
应用按微服务思想设计,内部划分为多个技术组件,包括APIGateway、档案、登记、通知、支付及一些数据库服务
技术组件可弹性扩缩容
这样的应用目前很常见,它有这样一些特征:
变:架构变、实例变
由于研发每周都在迭代,可能随时都加增加新的技术组件种类,如增加一个MongoDB作为文档类数据存储;同时由于弹性扩缩容,每个技术组件的实例时刻也在变,比如下图,就减少了一个档案服务,增加了一个支付服务:
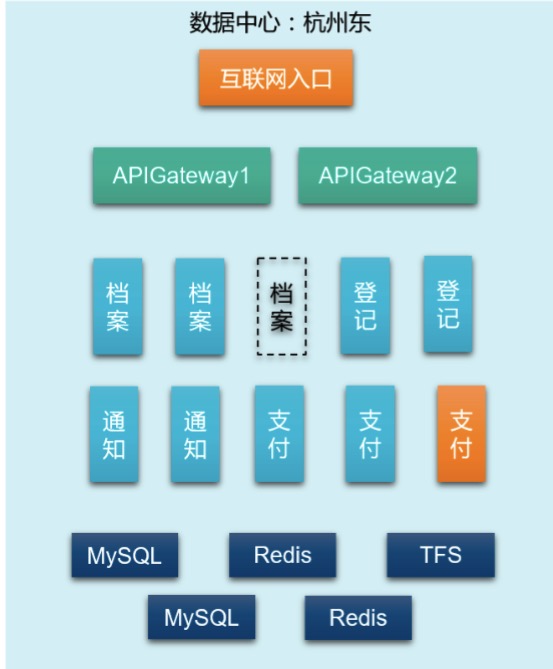
这给监控带来了难题:如何监控经常变化的目标? 答案是:监控配置自动化,随基础架构扩展,并标记监控目标。
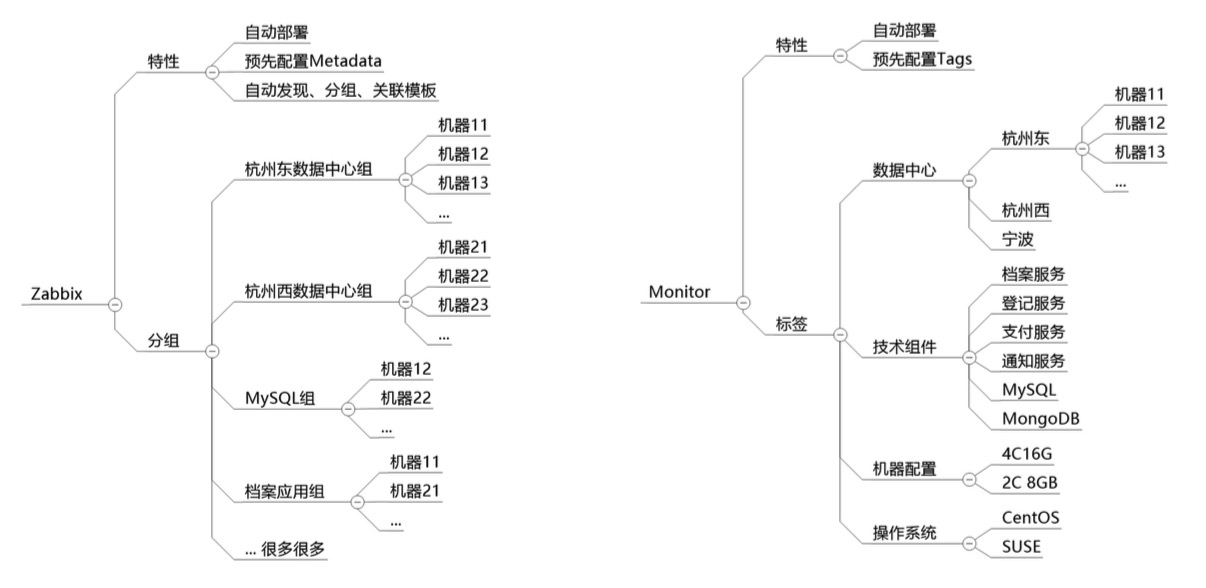
在Zabbix与UYUN Monitor产品中,都可以使用自动部署与发现来实现自动扩展监控。Zabbix主要使用标记与自动分组的方式,而Monitor则使用标签的方式:
多:种类多、实例多
一个公司可能存在30多个这样的集群应用,它使用上百种技术组件,数千个虚拟机或容器实例。如此大的规模,带来了巨大的监控复杂度,新的难题是:我们变得更难预测的故障诊断场景!
我们举几个具体的场景来说明这点:
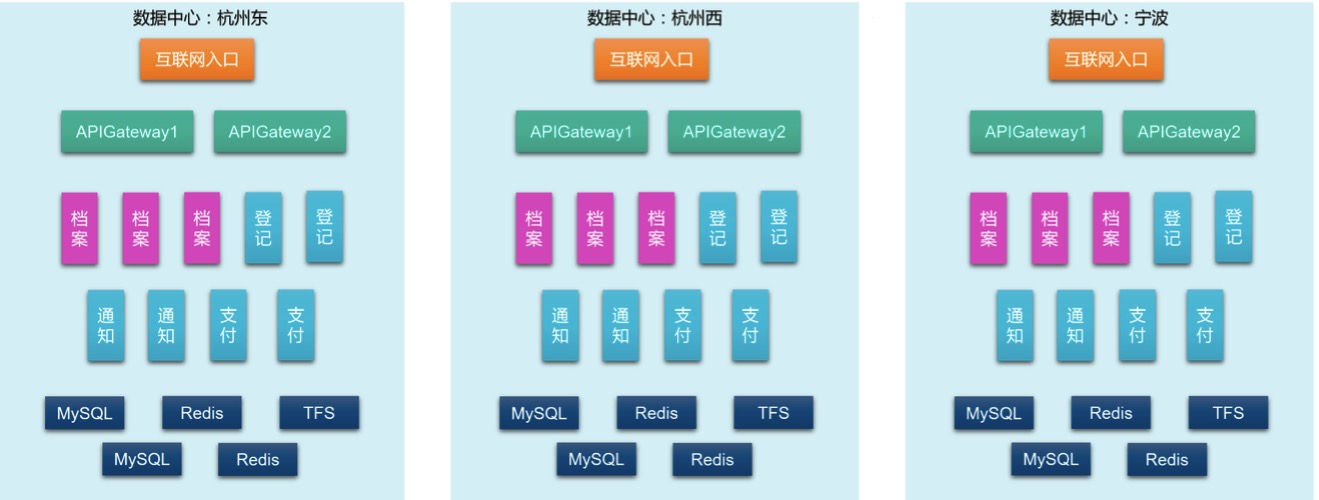
场景1:我想要知道所有的档案查询次数
档案查询次数是衡量整个应用业务量的一个重要指标,这个场景的难点是档案服务是多实例的,并且分布在多个数据中心。针对这个场景,我们的解题思路是:合计所有数据中心的所有档案服务的查询API调用次数,即下图中所有红色部份:
使用Zabbix时,可以按如下步骤:
创建一个档案服务group,包含所有数据中心的所有档案服务
创建一个item,使用汇聚 groupfunc 合计 group 内的所有查询API调用次数
使用UYUM Monitor时,则配置如下字符串即可:
m=sum:查询API调用次数{技术组件=档案服务}
实现效果:

场景2:我想知道APIGateway TCP连接数三个中心的各自占比
通过连接数占比,我们可以分析出各个数据中心的负载是否均衡。其解题思路是:独立合计每个数据中心的APIGateway TCP连接数,即如下红色部份:

使用Zabbix时,可以按如下步骤配置:
创建三个数据中心APIGateway group g1. 杭州东 APIGateway group g2. 杭州西 APIGateway group g3. 宁波 APIGateway group
创建对应item 分别统计其TCP连接数合计
使用UYUM Monitor时,还是配置如下字符串即可:
m=sum:TCP连接数{数据中心=*,技术组件=APIGateway}
实现效果:

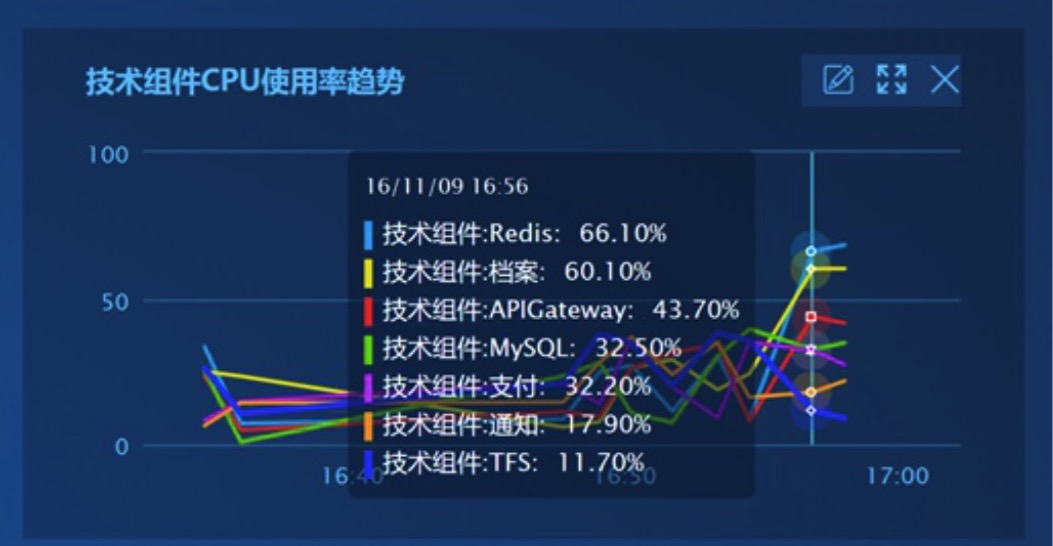
场景3:我想知道各种服务的主机CPU平均利用率趋势
通过将一些技术组件的CPU利用率在一个趋势图中显示,我们可以利用指标间的正相关性,来分析组件间的影响,比如档案服务的CPU利用率升高时,提供其数据的Redis服务CPU使用率也在升高。其解题思路为:分别为每种服务求得其主机CPU平均利用率,并在一个趋势图中展示。
使用Zabbix时,可以按如下步骤配置:
创建各个技术组件对应的group,包含:是APIGateway、档案、登记、通知、支付、MySQL等等
创建对应item 分别统计其主机CPU利用率平均值
而使用UYUM Monitor时,依然是配置如下字符串:
起始时间=30分钟前&m=avg:主机CPU利用率{技术组件=*}
实现效果:
使用标签标记监控数据的维度
我们可以看出,Zabbix与Monitor针对一些数据的提取方式是不一样的。Zabbix更多的是使用Group分组的方式,来梳理某些维度同类型的信息,这种方式是我们过去惯用的,组织一棵树来抽象世界。
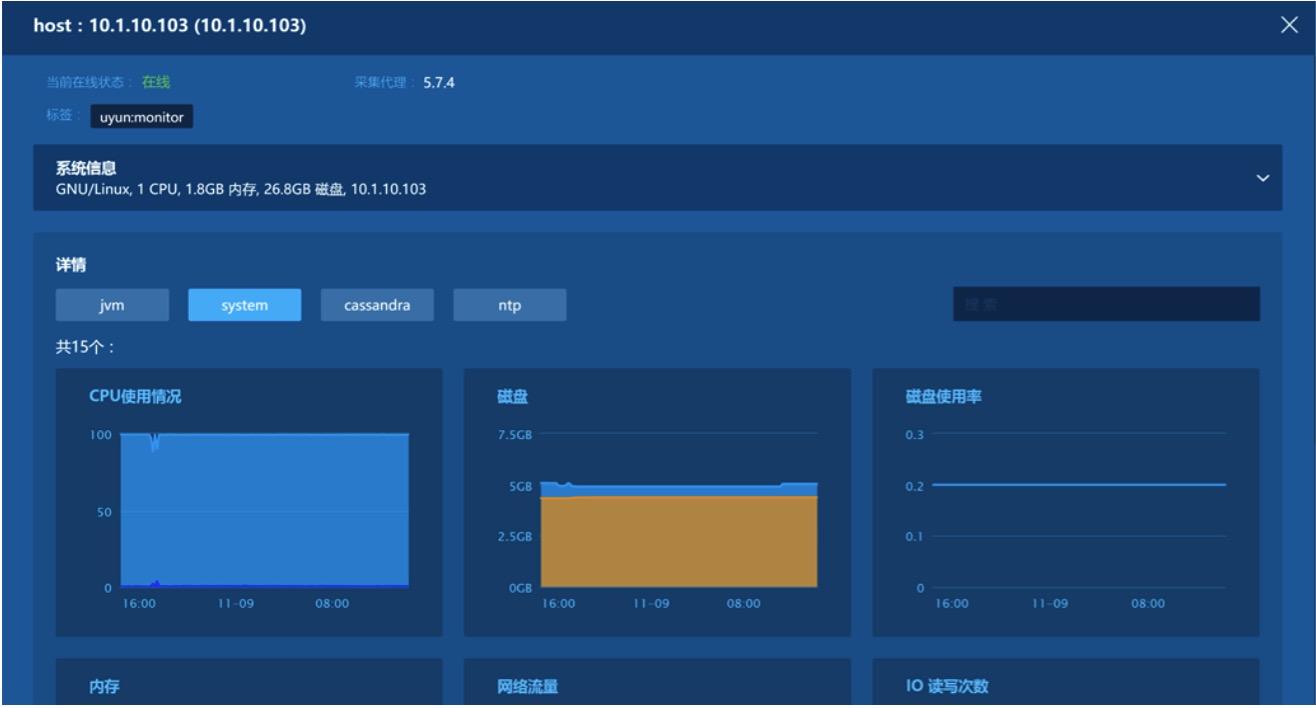
但是,世界其实是平的,各种事物实际上是平等存在的,只是它们有着各自的特性而已。所以,我们所需要的只是按需用这些特性标签来提取它们。举例来说,下图就可以看到两个主机的各种标签:

使用UYUN Monitor时,可以按很多种不同的方式来建立标签,包括:
1、安装代理时指定
2、查看主机信息时指定
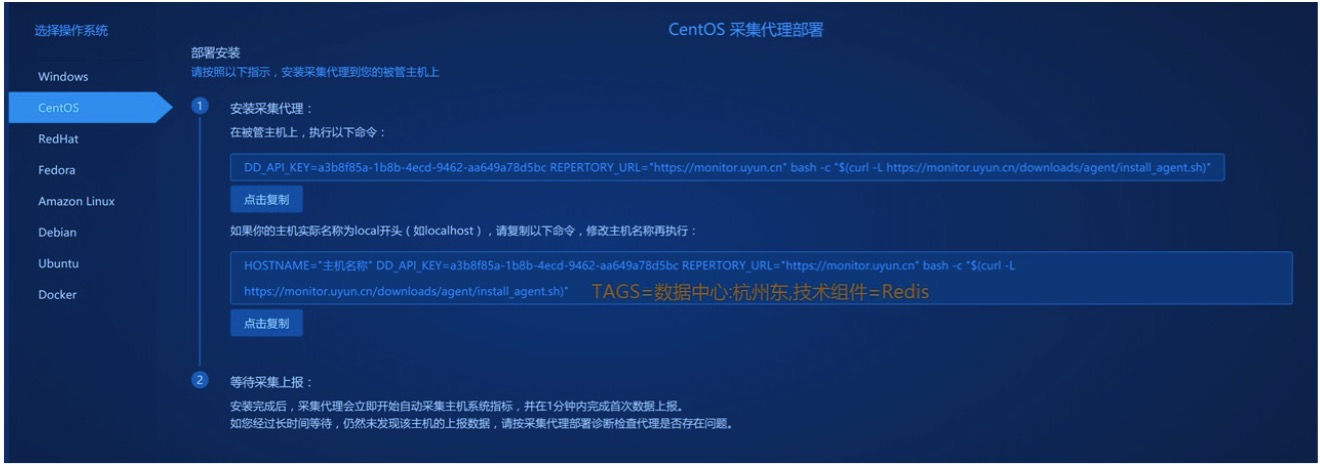
3、以及通过自定义脚本推送指标时指定 推送到本机代理:
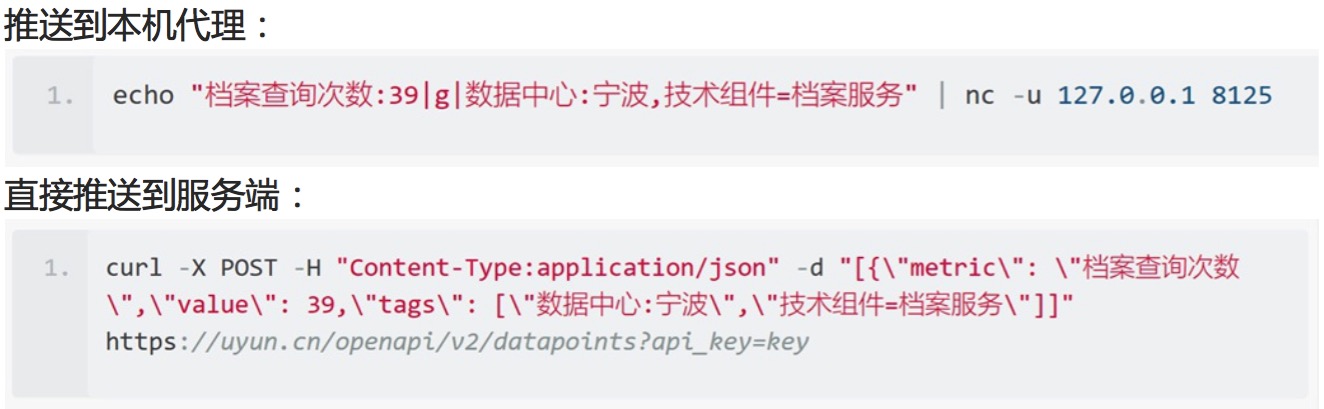
在为监控对象建立好这些标签后,我们就可以充分使用标签带来的便利,随需查询,不预设场景。
监控数据应用场景
新一代的监控系统,其本质实际上是一个监控大数据收集与分析平台,它不限定监控底层的数据来源以便全面覆盖运维对象,通过海量存储与灵活的数据提取能力,为上层的各种运维场景,提供如大屏可视化、报警、分析报表等功能。

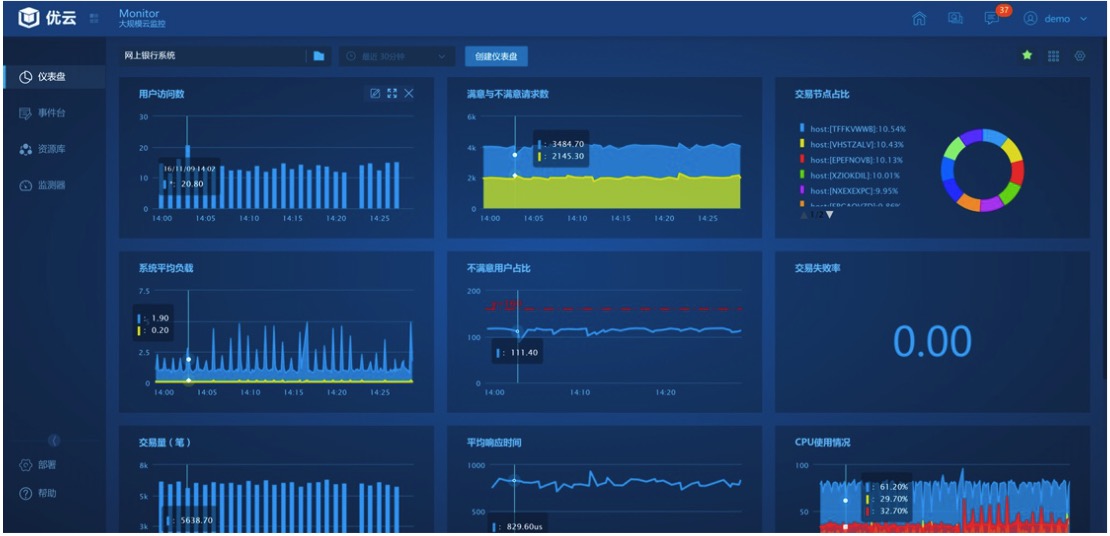
UYUN Monitor 也提供了多种上层的运维分析功能,包括:
1、个性丰富的仪表盘,能灵活提取各类监控数据按多种方式展现
2、指标的阈值检查策略,能对集群指标进行综合汇聚与告警
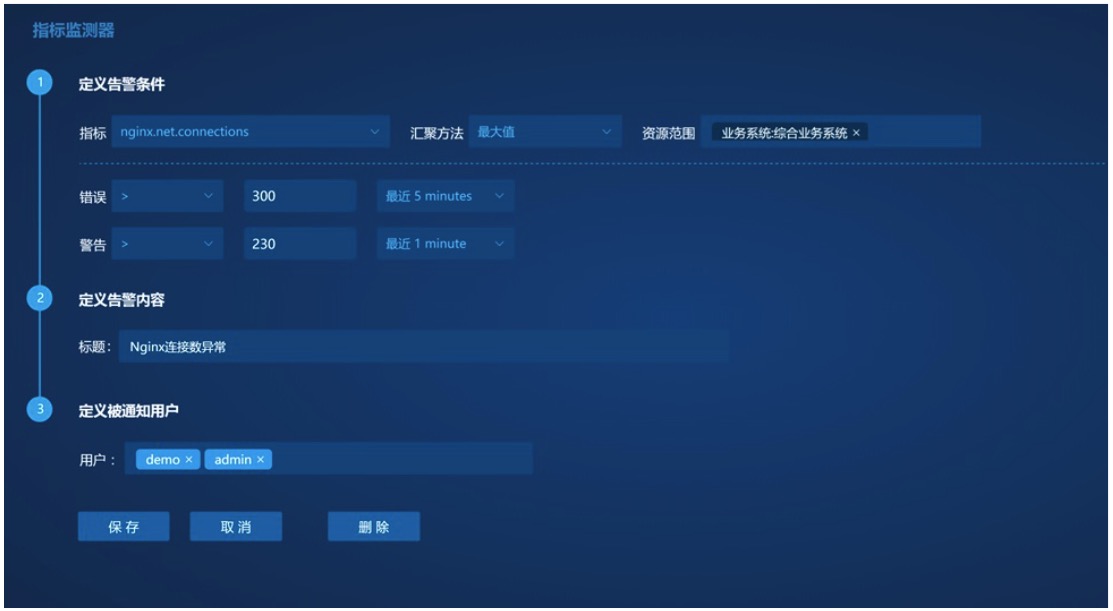
3、第三方数据查询OpenAPI,提供数据的二次消费入口

可以看出,面对云时代,我们对监控系统的要求已经产生了变化,监控系统实际上已经转变 为一个监控大数据收集与分析平台,它不限定监控底层的数据来源以便全面覆盖运维对象, 通过海量存储与灵活的数据提取能力,为上层的各种运维场景,提供如大屏可视化、报警、 分析报表等功能。
本次主题《监控大数据的提取与分析》的分享希望对大家有所帮助,优云敏捷运维大讲堂面向运维领域的技术分享、最佳实践将不定期与大家见面,敬请期待。
讲师介绍
蒋君伟
• IT运维领域资深专家,优云软件产品总监,拥有10年运维实战经验