Base64隐写的原理
为什么Base64可以做隐写[1]
1. 先要了解Base64的解码过程
rawStr = Base64编码后的字符串 cnt = 编码尾部的等号数 for i in rawStr: 根据Base编码表,转化为6位的二进制数 删除尾部 cnt*8 位的数据 按8位一组,分割二进制数据 对应转为ASCII
2. 因此下图所示,尾部加粗的0会在解码过程中删去,即使被修改也不会影响解码结果,所以这部分数据是可以用于隐写的。
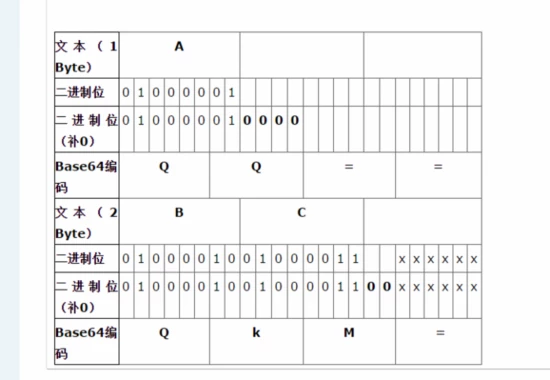
如何提取隐写的数据
py2代码[2]如下:
1 # py2 2 def get_base64_diff_value(s1, s2): 3 base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' 4 res = 0 5 for i in xrange(len(s2)): 6 if s1[i] != s2[i]: 7 return abs(base64chars.index(s1[i]) - base64chars.index(s2[i])) 8 return res 9 10 def solve_stego(): 11 with open('2.txt', 'rb') as f: 12 file_lines = f.readlines() 13 bin_str = '' 14 for line in file_lines: 15 steg_line = line.replace(' ', '') 16 norm_line = line.replace(' ', '').decode('base64').encode('base64').replace(' ', '') 17 diff = get_base64_diff_value(steg_line, norm_line) 18 pads_num = steg_line.count('=') 19 if diff: 20 bin_str += bin(diff)[2:].zfill(pads_num * 2) 21 else: 22 bin_str += '0' * pads_num * 2 23 res_str = '' 24 for i in xrange(0, len(bin_str), 8): 25 res_str += chr(int(bin_str[i:i+8], 2)) 26 print res_str 27 28 solve_stego()
1. 第16行代码为什么先解码再编码?
steg_line读入的行,是带有隐写数据的。norm_line将读入的带有隐写数据的行,进行解码,实际上已经消除了隐写的数据。再进行编码时,尾部不够6bit做填充时,填充的是0,因此norm_line是常规的不带隐写数据的Base64值。
比如一例:
| line | 'c3RlZx== ' |
| steg_line | 'c3RlZx==' |
| norm_line | 'c3RlZw==' |
可以看到,尾部是不一样的。还原一下得到norm_line的过程:先解码得到的是steg,steg的ASCII二进制表示为01110011 01110100 01100101 01100111,以6bit一组分割,得到011100,110111,010001,100101,011001,110000(后四位的0是填充的)。根据Base64编码表[3]可以得到c3RlZw==,steg_line隐写的方法是将解码时会删去的后四位0改成了0001,110001对应编码表中的x。
2. 第17行的get_base64_diff_value有什么作用
steg_line和norm_line最后一个数据位(也即不带等号的最后一位)的差值的绝对值。
3. 往后的代码
是为了不断地拼接,从隐写部位获得的位数据,再将其转为ASCII显示。由于在拼接过程中,后续数据还没有接上,会有二进制位数不等于8的倍数的情况,所以print出来的数据,有的并不是ASCII值。zfill控制填充0的数目,是为了可以正常地获取到包含隐写数据的部分,防止因为位数的错误,导致拼接后的数据不可打印。
填充的0的个数和等号的个数相关。(所以如有n个等号,则需要将带有隐写数据的部分的二进制位数,设定为2*n)
Reference
[1] https://www.tuicool.com/articles/RRr2miE
[2] http://delimitry.blogspot.com/2014/02/olympic-ctf-2014-find-da-key-writeup.html (需ke'xue上网)