前言
深度卷积网络除了准确度,计算复杂度也是考虑的重要指标。本文列出了近年主流的轻量级网络,简单地阐述了它们的思想。由于本人水平有限,对这部分的理解还不够深入,还需要继续学习和完善。
最后我参考部分列出来的文章都写的非常棒,建议继续阅读。
复杂度分析
- 理论计算量(FLOPs):浮点运算次数(FLoating-point Operation)
- 参数数量(params):单位通常为M,用float32表示。
对比
- std conv(主要贡献计算量)
- params:(k_h imes k_w imes c_{in} imes c_{out})
- FLOPs:(k_h imes k_w imes c_{in} imes c_{out} imes H imes W)
- fc(主要贡献参数量)
- params:(c_{in} imes c_{out})
- FLOPs:(c_{in} imes c_{out})
- group conv
- params:((k_h imes k_w imes c_{in}/g imes c_{out}/g) imes g=k_h imes k_w imes c_{in} imes c_{out}/g)
- FLOPs:(k_h imes k_w imes c_{in} imes c_{out} imes H imes W/g)
- depth-wise conv
- params:(k_h imes k_w imes c_{in} imes c_{out}/c_{in}=k_h imes k_w imes c_{out})
- FLOPs:(k_h imes k_w imes c_{out} imes H imes W)
SqueezeNet
SqueezeNet:AlexNet-level accuracy with 50x fewer parameters and <0.5MB
核心思想
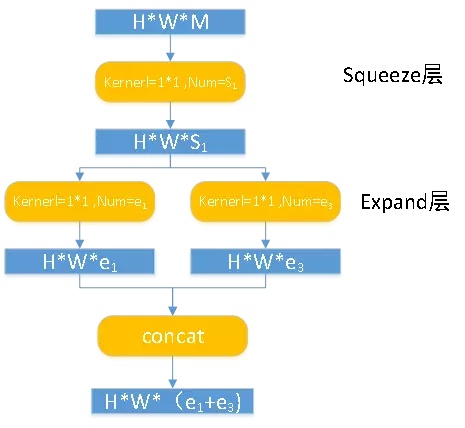
- 提出Fire module,包含两部分:squeeze和expand层。
- squeeze为1x1卷积,(S_1lt M),从而压缩
- Expand层为e1个1x1卷积和e3个3x3卷积,分别输出(H imes W imes e1)和(H imes W imes e_2)。
- concat得到(H imes W imes (e_1+e_3))
class Fire(nn.Module):
def __init__(self, in_channel, out_channel, squzee_channel):
super().__init__()
self.squeeze = nn.Sequential(
nn.Conv2d(in_channel, squzee_channel, 1),
nn.BatchNorm2d(squzee_channel),
nn.ReLU(inplace=True)
)
self.expand_1x1 = nn.Sequential(
nn.Conv2d(squzee_channel, int(out_channel / 2), 1),
nn.BatchNorm2d(int(out_channel / 2)),
nn.ReLU(inplace=True)
)
self.expand_3x3 = nn.Sequential(
nn.Conv2d(squzee_channel, int(out_channel / 2), 3, padding=1),
nn.BatchNorm2d(int(out_channel / 2)),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.squeeze(x)
x = torch.cat([
self.expand_1x1(x),
self.expand_3x3(x)
], 1)
return x
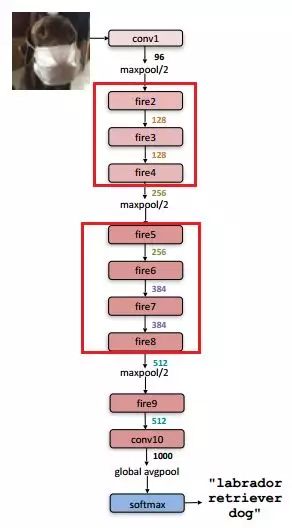
网络架构
class SqueezeNet(nn.Module):
"""mobile net with simple bypass"""
def __init__(self, class_num=100):
super().__init__()
self.stem = nn.Sequential(
nn.Conv2d(3, 96, 3, padding=1),
nn.BatchNorm2d(96),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2)
)
self.fire2 = Fire(96, 128, 16)
self.fire3 = Fire(128, 128, 16)
self.fire4 = Fire(128, 256, 32)
self.fire5 = Fire(256, 256, 32)
self.fire6 = Fire(256, 384, 48)
self.fire7 = Fire(384, 384, 48)
self.fire8 = Fire(384, 512, 64)
self.fire9 = Fire(512, 512, 64)
self.conv10 = nn.Conv2d(512, class_num, 1)
self.avg = nn.AdaptiveAvgPool2d(1)
self.maxpool = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.stem(x)
f2 = self.fire2(x)
f3 = self.fire3(f2) + f2
f4 = self.fire4(f3)
f4 = self.maxpool(f4)
f5 = self.fire5(f4) + f4
f6 = self.fire6(f5)
f7 = self.fire7(f6) + f6
f8 = self.fire8(f7)
f8 = self.maxpool(f8)
f9 = self.fire9(f8)
c10 = self.conv10(f9)
x = self.avg(c10)
x = x.view(x.size(0), -1)
return x
def squeezenet(class_num=100):
return SqueezeNet(class_num=class_num)
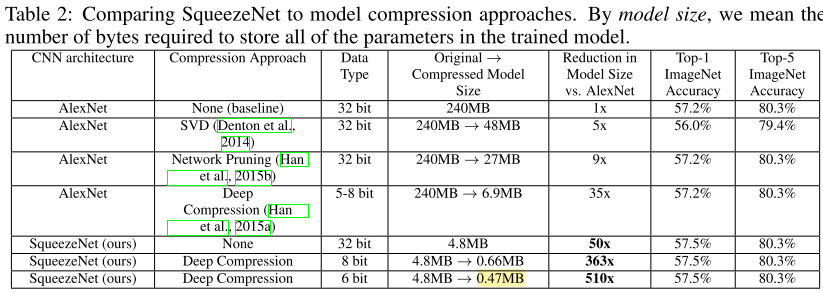
实验结果
- 注意:0.5MB是模型压缩的结果。
MobileNetV1
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
核心思想
-
使用了depth-wise separable conv降低了参数和计算量。
-
提出两个超参数Width Multiplier和Resolution Multiplier来平衡时间和精度。
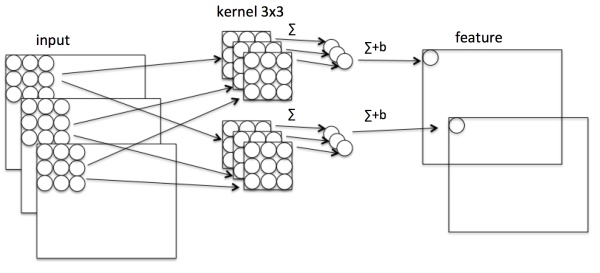
- depth-wise separable conv
Standard Conv
(D_K):kernel size
(D_F):feature map size
(M):input channel number
(N):output channel number
参数量:(D_K imes D_K imes M imes N (3 imes3 imes 3 imes 2))
计算量:(D_K cdot D_K cdot M cdot N cdot D_F cdot D_F)
用depth-wise separable conv来替代std conv,depth-wise conv分解为depthwise conv和pointwise conv。
std conv输出的每个通道的feature包含了输入所有通道的feature,depth-wise separable conv没有办法做到,所以需要用pointwise conv来结合不同通道的feature。
Depthwise Conv
对输入feature的每个通道单独做卷积操作,得到每个通道对应的输出feature。
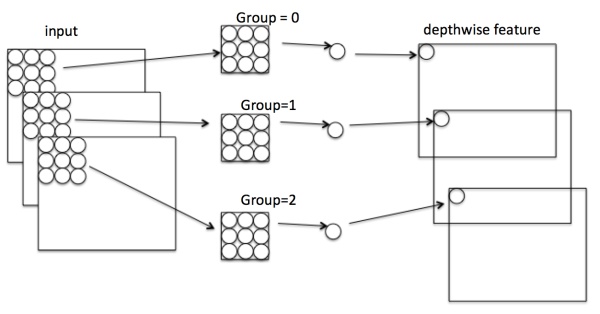
参数量:(D_K imes D_K imes M(3 imes 3 imes 3))
计算量:(D_K cdot D_K cdot M cdot D_F cdot D_F)
Pointwise Conv
将depthwise conv的输出,即不同通道的feature map结合起来,从而达到和std conv一样的效果。
![v2-b2f4c69bc63c2de4728039d409573e6f_r[1]](https://img2018.cnblogs.com/blog/1519578/201905/1519578-20190524105001390-131456990.jpg)
参数量:(1 imes 1 imes M imes N(1 imes1 imes3 imes2))
计算量:(Mcdot N cdot D_F cdot D_F)
从而总计算量为(D_K cdot D_K cdot M cdot D_F cdot D_F+Mcdot Ncdot D_F cdot D_F)
通过拆分,相当于将standard conv计算量压缩为:
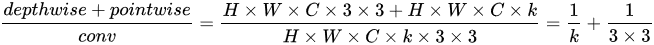
-
代码实现
BasicConv2d & DepthSeperableConv2d

class DepthSeperabelConv2d(nn.Module):
def __init__(self, input_channels, output_channels, kernel_size, **kwargs):
super().__init__()
self.depthwise = nn.Sequential(
nn.Conv2d(
input_channels,
input_channels,
kernel_size,
groups=input_channels,
**kwargs),
nn.BatchNorm2d(input_channels),
nn.ReLU(inplace=True)
)
self.pointwise = nn.Sequential(
nn.Conv2d(input_channels, output_channels, 1),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return x
class BasicConv2d(nn.Module):
def __init__(self, input_channels, output_channels, kernel_size, **kwargs):
super().__init__()
self.conv = nn.Conv2d(
input_channels, output_channels, kernel_size, **kwargs)
self.bn = nn.BatchNorm2d(output_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
- Two hyper-parameters
- Width Multiplier (alpha):以系数(1,0.75,0.5和0.25)乘以input、output channel
计算量变为(D_K cdot D_K cdot alpha M cdot D_F cdot D_F+alpha Mcdot alpha Ncdot D_F cdot D_F)
- Resoltion Multiplier ( ho):将输入分辨率变为(224,192,160或128)。
计算量变为(D_K cdot D_K cdot alpha M cdot ho D_F cdot ho D_F+alpha Mcdot alpha Ncdot ho D_F cdot ho D_F)
网络架构
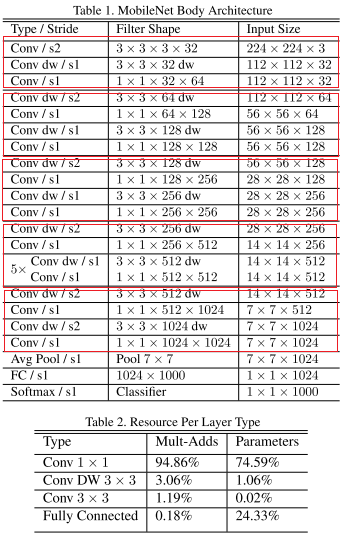
def mobilenet(alpha=1, class_num=100):
return MobileNet(alpha, class_num)
class MobileNet(nn.Module):
"""
Args:
width multipler: The role of the width multiplier α is to thin
a network uniformly at each layer. For a given
layer and width multiplier α, the number of
input channels M becomes αM and the number of
output channels N becomes αN.
"""
def __init__(self, width_multiplier=1, class_num=100):
super().__init__()
alpha = width_multiplier
self.stem = nn.Sequential(
BasicConv2d(3, int(32 * alpha), 3, padding=1, bias=False),
DepthSeperabelConv2d(
int(32 * alpha),
int(64 * alpha),
3,
padding=1,
bias=False
)
)
#downsample
self.conv1 = nn.Sequential(
DepthSeperabelConv2d(
int(64 * alpha),
int(128 * alpha),
3,
stride=2,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(128 * alpha),
int(128 * alpha),
3,
padding=1,
bias=False
)
)
#downsample
self.conv2 = nn.Sequential(
DepthSeperabelConv2d(
int(128 * alpha),
int(256 * alpha),
3,
stride=2,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(256 * alpha),
int(256 * alpha),
3,
padding=1,
bias=False
)
)
#downsample
self.conv3 = nn.Sequential(
DepthSeperabelConv2d(
int(256 * alpha),
int(512 * alpha),
3,
stride=2,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(512 * alpha),
int(512 * alpha),
3,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(512 * alpha),
int(512 * alpha),
3,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(512 * alpha),
int(512 * alpha),
3,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(512 * alpha),
int(512 * alpha),
3,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(512 * alpha),
int(512 * alpha),
3,
padding=1,
bias=False
)
)
#downsample
self.conv4 = nn.Sequential(
DepthSeperabelConv2d(
int(512 * alpha),
int(1024 * alpha),
3,
stride=2,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(1024 * alpha),
int(1024 * alpha),
3,
padding=1,
bias=False
)
)
self.fc = nn.Linear(int(1024 * alpha), class_num)
self.avg = nn.AdaptiveAvgPool2d(1)
def forward(self, x):
x = self.stem(x)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.avg(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
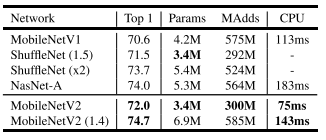
实验结果
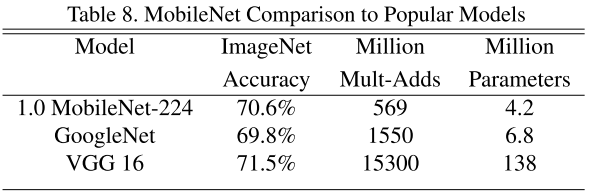
MobileNetV2
核心思想
- Inverted residual block:引入残差结构和bottleneck层。
- Linear Bottlenecks:ReLU会破坏信息,故去掉第二个Conv1x1后的ReLU,改为线性神经元。
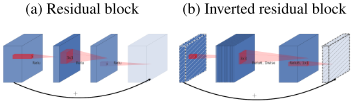
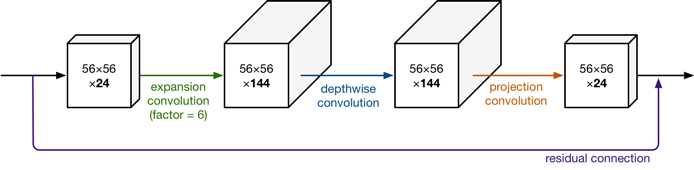
MobileNetv2与其他网络对比
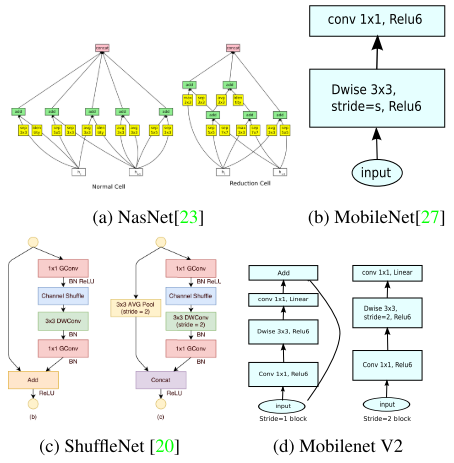
MobileNetV2 block
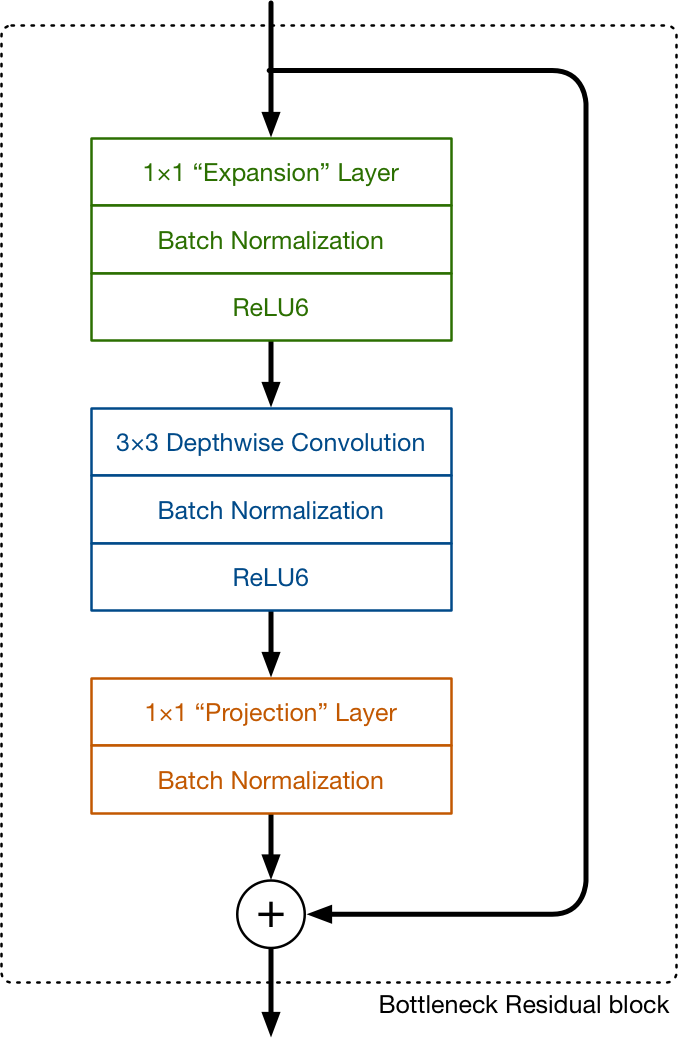
- 代码实现
class LinearBottleNeck(nn.Module):
def __init__(self, in_channels, out_channels, stride, t=6, class_num=100):
super().__init__()
self.residual = nn.Sequential(
nn.Conv2d(in_channels, in_channels * t, 1),
nn.BatchNorm2d(in_channels * t),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channels * t, in_channels * t, 3, stride=stride, padding=1, groups=in_channels * t),
nn.BatchNorm2d(in_channels * t),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channels * t, out_channels, 1),
nn.BatchNorm2d(out_channels)
)
self.stride = stride
self.in_channels = in_channels
self.out_channels = out_channels
def forward(self, x):
residual = self.residual(x)
if self.stride == 1 and self.in_channels == self.out_channels:
residual += x
return residual
网络架构
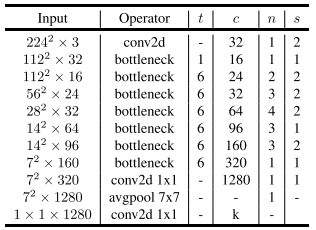
class MobileNetV2(nn.Module):
def __init__(self, class_num=100):
super().__init__()
self.pre = nn.Sequential(
nn.Conv2d(3, 32, 1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU6(inplace=True)
)
self.stage1 = LinearBottleNeck(32, 16, 1, 1)
self.stage2 = self._make_stage(2, 16, 24, 2, 6)
self.stage3 = self._make_stage(3, 24, 32, 2, 6)
self.stage4 = self._make_stage(4, 32, 64, 2, 6)
self.stage5 = self._make_stage(3, 64, 96, 1, 6)
self.stage6 = self._make_stage(3, 96, 160, 1, 6)
self.stage7 = LinearBottleNeck(160, 320, 1, 6)
self.conv1 = nn.Sequential(
nn.Conv2d(320, 1280, 1),
nn.BatchNorm2d(1280),
nn.ReLU6(inplace=True)
)
self.conv2 = nn.Conv2d(1280, class_num, 1)
def forward(self, x):
x = self.pre(x)
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.stage5(x)
x = self.stage6(x)
x = self.stage7(x)
x = self.conv1(x)
x = F.adaptive_avg_pool2d(x, 1)
x = self.conv2(x)
x = x.view(x.size(0), -1)
return x
def _make_stage(self, repeat, in_channels, out_channels, stride, t):
layers = []
layers.append(LinearBottleNeck(in_channels, out_channels, stride, t))
while repeat - 1:
layers.append(LinearBottleNeck(out_channels, out_channels, 1, t))
repeat -= 1
return nn.Sequential(*layers)
def mobilenetv2():
return MobileNetV2()
实验结果
ShuffleNetV1
核心思想
- 利用group convolution和channel shuffle来减少模型参数量。

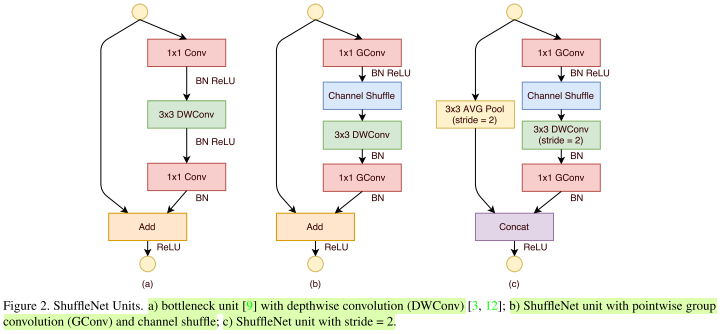
- ShuffleNet unit
从ResNet bottleneck 演化得到shuffleNet unit
- (a)带depth-wise conv的bottleneck unit
- (b)将1x1conv换成1x1Gconv,并在第一个1x1Gconv后增加一个channel shuffle。
- (c)旁路增加AVG pool,减小feature map的分辨率;分辨率小了,最后不采用add而是concat,从而弥补分辨率减小带来的信息损失。
- 代码实现
class ChannelShuffle(nn.Module):
def __init__(self, groups):
super().__init__()
self.groups = groups
def forward(self, x):
batchsize, channels, height, width = x.data.size()
channels_per_group = int(channels / self.groups)
#"""suppose a convolutional layer with g groups whose output has
#g x n channels; we first reshape the output channel dimension
#into (g, n)"""
x = x.view(batchsize, self.groups, channels_per_group, height, width)
#"""transposing and then flattening it back as the input of next layer."""
x = x.transpose(1, 2).contiguous()
x = x.view(batchsize, -1, height, width)
return x
class ShuffleNetUnit(nn.Module):
def __init__(self, input_channels, output_channels, stage, stride, groups):
super().__init__()
#"""Similar to [9], we set the number of bottleneck channels to 1/4
#of the output channels for each ShuffleNet unit."""
self.bottlneck = nn.Sequential(
PointwiseConv2d(
input_channels,
int(output_channels / 4),
groups=groups
),
nn.ReLU(inplace=True)
)
#"""Note that for Stage 2, we do not apply group convolution on the first pointwise
#layer because the number of input channels is relatively small."""
if stage == 2:
self.bottlneck = nn.Sequential(
PointwiseConv2d(
input_channels,
int(output_channels / 4),
groups=groups
),
nn.ReLU(inplace=True)
)
self.channel_shuffle = ChannelShuffle(groups)
self.depthwise = DepthwiseConv2d(
int(output_channels / 4),
int(output_channels / 4),
3,
groups=int(output_channels / 4),
stride=stride,
padding=1
)
self.expand = PointwiseConv2d(
int(output_channels / 4),
output_channels,
groups=groups
)
self.relu = nn.ReLU(inplace=True)
self.fusion = self._add
self.shortcut = nn.Sequential()
#"""As for the case where ShuffleNet is applied with stride,
#we simply make two modifications (see Fig 2 (c)):
#(i) add a 3 × 3 average pooling on the shortcut path;
#(ii) replace the element-wise addition with channel concatenation,
#which makes it easy to enlarge channel dimension with little extra
#computation cost.
if stride != 1 or input_channels != output_channels:
self.shortcut = nn.AvgPool2d(3, stride=2, padding=1)
self.expand = PointwiseConv2d(
int(output_channels / 4),
output_channels - input_channels,
groups=groups
)
self.fusion = self._cat
def _add(self, x, y):
return torch.add(x, y)
def _cat(self, x, y):
return torch.cat([x, y], dim=1)
def forward(self, x):
shortcut = self.shortcut(x)
shuffled = self.bottlneck(x)
shuffled = self.channel_shuffle(shuffled)
shuffled = self.depthwise(shuffled)
shuffled = self.expand(shuffled)
output = self.fusion(shortcut, shuffled)
output = self.relu(output)
return output
网络架构
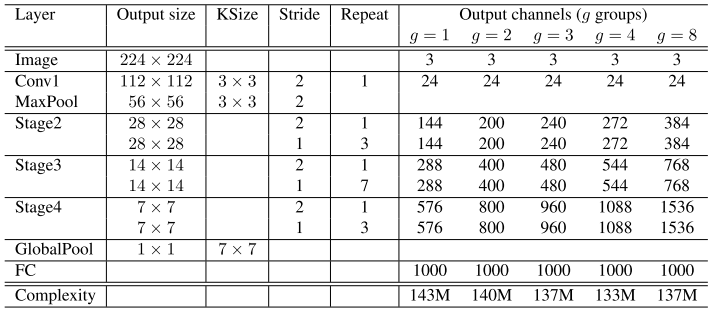
- 代码实现
class ShuffleNet(nn.Module):
def __init__(self, num_blocks, num_classes=100, groups=3):
super().__init__()
if groups == 1:
out_channels = [24, 144, 288, 567]
elif groups == 2:
out_channels = [24, 200, 400, 800]
elif groups == 3:
out_channels = [24, 240, 480, 960]
elif groups == 4:
out_channels = [24, 272, 544, 1088]
elif groups == 8:
out_channels = [24, 384, 768, 1536]
self.conv1 = BasicConv2d(3, out_channels[0], 3, padding=1, stride=1)
self.input_channels = out_channels[0]
self.stage2 = self._make_stage(
ShuffleNetUnit,
num_blocks[0],
out_channels[1],
stride=2,
stage=2,
groups=groups
)
self.stage3 = self._make_stage(
ShuffleNetUnit,
num_blocks[1],
out_channels[2],
stride=2,
stage=3,
groups=groups
)
self.stage4 = self._make_stage(
ShuffleNetUnit,
num_blocks[2],
out_channels[3],
stride=2,
stage=4,
groups=groups
)
self.avg = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(out_channels[3], num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.avg(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def _make_stage(self, block, num_blocks, output_channels, stride, stage, groups):
"""make shufflenet stage
Args:
block: block type, shuffle unit
out_channels: output depth channel number of this stage
num_blocks: how many blocks per stage
stride: the stride of the first block of this stage
stage: stage index
groups: group number of group convolution
Return:
return a shuffle net stage
"""
strides = [stride] + [1] * (num_blocks - 1)
stage = []
for stride in strides:
stage.append(
block(
self.input_channels,
output_channels,
stride=stride,
stage=stage,
groups=groups
)
)
self.input_channels = output_channels
return nn.Sequential(*stage)
def shufflenet():
return ShuffleNet([4, 8, 4])
实验结果
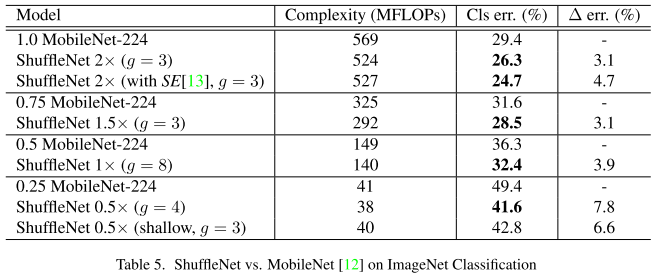
ShuffleNetV2
核心思想
-
基于四条准则,改进了SuffleNetv1
G1)同等通道最小化内存访问量(1x1卷积平衡输入和输出通道大小)
G2)过量使用组卷积增加内存访问量(谨慎使用组卷积)
G3)网络碎片化降低并行度(避免网络碎片化)
G4)不能忽略元素级操作(减少元素级运算)
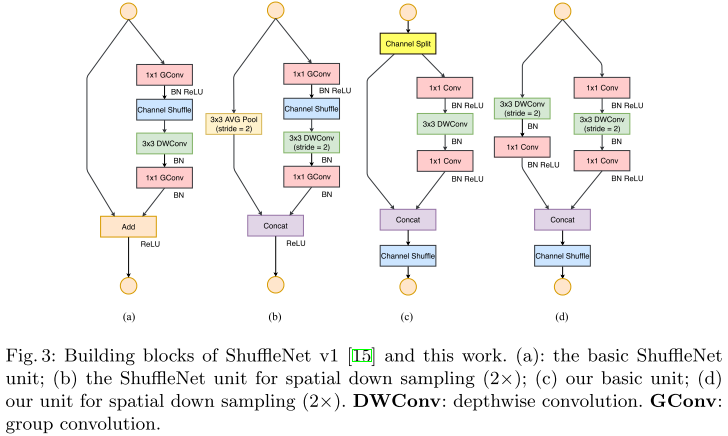
- 代码实现
def channel_split(x, split):
"""split a tensor into two pieces along channel dimension
Args:
x: input tensor
split:(int) channel size for each pieces
"""
assert x.size(1) == split * 2
return torch.split(x, split, dim=1)
def channel_shuffle(x, groups):
"""channel shuffle operation
Args:
x: input tensor
groups: input branch number
"""
batch_size, channels, height, width = x.size()
channels_per_group = int(channels / groups)
x = x.view(batch_size, groups, channels_per_group, height, width)
x = x.transpose(1, 2).contiguous()
x = x.view(batch_size, -1, height, width)
return x
class ShuffleUnit(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super().__init__()
self.stride = stride
self.in_channels = in_channels
self.out_channels = out_channels
if stride != 1 or in_channels != out_channels:
self.residual = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, in_channels, 3, stride=stride, padding=1, groups=in_channels),
nn.BatchNorm2d(in_channels),
nn.Conv2d(in_channels, int(out_channels / 2), 1),
nn.BatchNorm2d(int(out_channels / 2)),
nn.ReLU(inplace=True)
)
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 3, stride=stride, padding=1, groups=in_channels),
nn.BatchNorm2d(in_channels),
nn.Conv2d(in_channels, int(out_channels / 2), 1),
nn.BatchNorm2d(int(out_channels / 2)),
nn.ReLU(inplace=True)
)
else:
self.shortcut = nn.Sequential()
in_channels = int(in_channels / 2)
self.residual = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, in_channels, 3, stride=stride, padding=1, groups=in_channels),
nn.BatchNorm2d(in_channels),
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
if self.stride == 1 and self.out_channels == self.in_channels:
shortcut, residual = channel_split(x, int(self.in_channels / 2))
else:
shortcut = x
residual = x
shortcut = self.shortcut(shortcut)
residual = self.residual(residual)
x = torch.cat([shortcut, residual], dim=1)
x = channel_shuffle(x, 2)
return x
网络架构
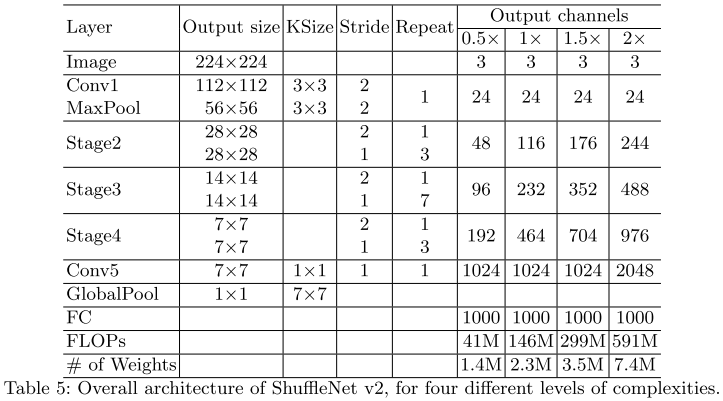
class ShuffleNetV2(nn.Module):
def __init__(self, ratio=1, class_num=100):
super().__init__()
if ratio == 0.5:
out_channels = [48, 96, 192, 1024]
elif ratio == 1:
out_channels = [116, 232, 464, 1024]
elif ratio == 1.5:
out_channels = [176, 352, 704, 1024]
elif ratio == 2:
out_channels = [244, 488, 976, 2048]
else:
ValueError('unsupported ratio number')
self.pre = nn.Sequential(
nn.Conv2d(3, 24, 3, padding=1),
nn.BatchNorm2d(24)
)
self.stage2 = self._make_stage(24, out_channels[0], 3)
self.stage3 = self._make_stage(out_channels[0], out_channels[1], 7)
self.stage4 = self._make_stage(out_channels[1], out_channels[2], 3)
self.conv5 = nn.Sequential(
nn.Conv2d(out_channels[2], out_channels[3], 1),
nn.BatchNorm2d(out_channels[3]),
nn.ReLU(inplace=True)
)
self.fc = nn.Linear(out_channels[3], class_num)
def forward(self, x):
x = self.pre(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = F.adaptive_avg_pool2d(x, 1)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def _make_stage(self, in_channels, out_channels, repeat):
layers = []
layers.append(ShuffleUnit(in_channels, out_channels, 2))
while repeat:
layers.append(ShuffleUnit(out_channels, out_channels, 1))
repeat -= 1
return nn.Sequential(*layers)
def shufflenetv2():
return ShuffleNetV2()
实验结果

参考
纵览轻量化卷积神经网络:SqueezeNet、MobileNet、ShuffleNet、Xception
http://machinethink.net/blog/mobilenet-v2/