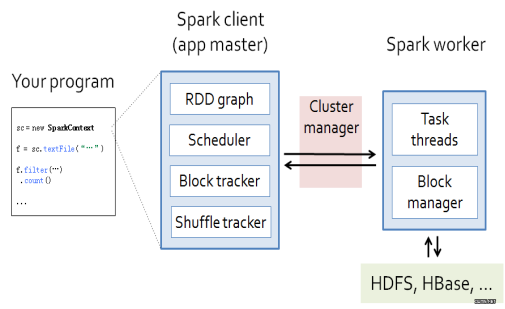
Spark工作流程由4个主体联系构成(如上图所示):
- Application:指用户编写的Spark应用程序,其中包括一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码
- Master:主节点,布置作业
- Block Tracker用于记录计算数据在Worker节点上的块信息
- Shuffle Blocker用于记录RDD在计算过程中遇到Shuffle过程时会进行物化,Shuffle Tracker用于记录这些物化的RDD的存放信息
- Cluster Manager:控制整个集群,监控worker
- Worker:从节点,负责控制计算,启动Executor或者Driver。
- Driver: 运行Application 的main()函数
- Executor:执行器,是为某个Application运行在worker node上的一个进程
工作流程:
- 用户编写应用程序以后交给Master
- Master启动RDD Graph,对任务进行划分,构建DAG图。将DAG图分解成Stage,将Taskset发送给Task Scheduler。
- 由Task Scheduler将Task发送给Executor运行
- 在这期间,Manager会负责监管Worker的运行。计算结果层层返回。
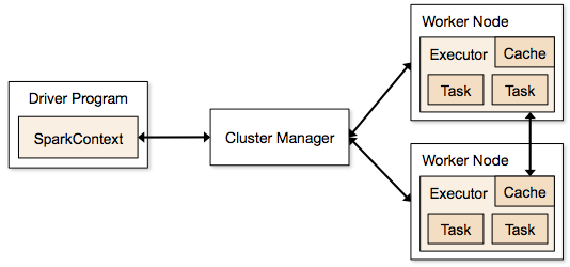
具体实现:
- 构建Spark Application的运行环境,启动SparkContext
- SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动StandaloneExecutorbackend
- Executor向SparkContext申请Task
- SparkContext将应用程序分发给Executor
- SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行
- Task在Executor上运行,运行完释放所有资源
参考文献:spark工作流程及原理(一)