本文讲述了以下几个方面:
1.何为迭代,何为可迭代对象,何为生成器,何为迭代器?
2.可迭代对象与迭代器之间的区别
3.生成器内部原理解析,for循环迭代内部原理解析
4.可迭代对象,迭代器,生成器,生成器函数之间关系
1.迭代
要搞清楚什么关于迭代器,生成器,可迭代对象,前提是我们要理解何为迭代。
第一,迭代需要重复进行某一操作
第二,本次迭代的要依赖上一次的结果继续往下做,如果中途有任何停顿,都不能算是迭代.
下面来看看几个例子,你就会更能理解迭代的含义。
# example1
# 非迭代 count = 0 while count < 10: print("hello world") count += 1
# example2
# 迭代 count = 0 while count < 10: print(count) count += 1
例子1,仅仅只是在重复一件事,那就是不停的打印"hello world",并且,这个打印的结果并不依赖上一次输出的值。而例子2,就很好地说明迭代的含义,重复+继续。
2.可迭代对象
按照上面迭代的含义,我们应该能够知道何为可迭代对象。顾名思义,就是一个对象能够被迭代的使用。那么我们该如何判断一个对象是否可迭代呢?
Python提供了模块collections,其中有一个isinstance(obj,string)的函数,可以判断一个对象是否为可迭代对象。看下面实例:
from collections import Iterable f = open('a.txt') i = 1 s = '1234' d = {'abc':1} t = (1,2,344) m = {1,2,34,} print(isinstance(i, Iterable)) # 判断整型是否为可迭代对象 print(isinstance(s, Iterable)) # 判断字符串对象是否为可迭代对象 print(isinstance(d, Iterable)) # 判断字典对象是否为可迭代对象 print(isinstance(t, Iterable)) # 判断元组对象是否为可迭代对象 print(isinstance(m, Iterable)) # 判断集合对象是否为可迭代对象 print(isinstance(f, Iterable)) # 判断文件对象是否为可迭代对象 ########输出结果######### False True True True True True
由上面得出,除了整型之外,python内的基本数据类型都是可迭代对象,包括文件对象。那么,python内部是如何知道一个对象是否为可迭代对象呢?答案是,在每一种数据类型对象中,都会有有一个__iter__()方法,正是因为这个方法,才使得这些基本数据类型变为可迭代。
如果不信,我们可以来看看下面代码片段:


f = open('a.txt') i = 1 s = '1234' d = {'abc':1} t = (1,2,344) m = {1,2,34,} # hasattr(obj,string) 判断对象中是否存在string方法 print(hasattr(i, '__iter__')) print(hasattr(s, '__iter__')) print(hasattr(d, '__iter__')) print(hasattr(t, '__iter__')) print(hasattr(m, '__iter__')) print(hasattr(f, '__iter__')) #########输出结果####### C:Python35python3.exe D:/CODE_FILE/python/day21/迭代器.py False True True True True True
如果大家还是不信,可以继续来测试。我们自己来写一个类,看看有__iter__()方法和没有此方法的区别。
# 没有__iter__()方法 class Animal: def __init__(self): pass cat = Animal() print(isinstance(cat, Iterable)) ######输出结果########## False # 有__iter__()方法 class Animal: def __init__(self): pass def __iter__(self): pass cat = Animal() print(isinstance(cat, Iterable)) ######输出结果########## True
从上面,实验结果可以看出一个对象是否可迭代,关键看這个对象是否有__iter__()方法。
3.迭代器
在介绍迭代器之前,我们先来了解一下容器这个概念。
容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个地迭代获取。简单来说,就好比一个盒子,我们可以往里面存放数据,也可以从里面一个一个地取出数据。
在python中,属于容器类型地有:list,dict,set,str,tuple.....。容器仅仅只是用来存放数据的,我们平常看到的 l = [1,2,3,4]等等,好像我们可以直接从列表这个容器中取出元素,但事实上容器并不提供这种能力,而是可迭代对象赋予了容器这种能力。
说完了容器,我们在来谈谈迭代器。迭代器与可迭代对象区别在于:__next__()方法。
我们可以采用以下方法来验证一下:
from collections import Iterator f = open('a.txt') i = 1 s = '1234' d = {'abc':1} t = (1, 2, 344) m = {1, 2, 34, } print(isinstance(i,Iterator)) print(isinstance(s,Iterator)) print(isinstance(d,Iterator)) print(isinstance(t,Iterator)) print(isinstance(m,Iterator)) print(isinstance(f,Iterator)) ########输出结果########## False False False False False True
结果显示:除了文件对象为迭代器,其余均不是迭代器
下面,我们进一步来验证一下:
print(hasattr(i,"__next__")) print(hasattr(s,"__next__")) print(hasattr(d,"__next__")) print(hasattr(t,"__next__")) print(hasattr(m,"__next__")) print(hasattr(f,"__next__")) #######结果########### False False False False False True
从输出结果可以表明,迭代器与可迭代对象仅仅就是__next__()方法的有无。
4.for内部机制剖析
先来看看一段普通的迭代过程:
l = [1,2,3,4,5] for i in l: print(i)
根据之前的分析,我们知道 l = [1,2,3,4,5]是一个可迭代对象。而且可迭代对象是不可以直接从其中取到元素。那么为啥我们还能从列表L中取到元素呢?这一切都是因为for循环内部实现。在for循环内部,首先L会调用__iter__()方法,将列表L变为一个迭代器,然后这个迭代器再调用其__next__()方法,返回取到的第一个值,这个元素就被赋值给了i,接着就打印输出了。
下面,我们通过一系列的实验来证明上述所说的。
l = [1,2,3,4,5,6] item = l.__iter__() # 将l变为迭代器 print(item.__next__()) # 迭代器调用next方法,并且返回取出的元素 print(item.__next__()) print(item.__next__()) print(item.__next__()) print(item.__next__()) print(item.__next__()) print(item.__next__()) # 报错 #######输出结果############# 1 2 3 4 5 6 ######上面为什么报错呢??########## #当调用了最后一个next方法,没有下一个元素可取 #就会报错StopIteration异常错误。你可能会想会 #为什么for循环没有报错?答案很简单,因为for循 #环内部帮我们捕捉到了这个异常,一旦捕捉到异常 #说明,迭代应该结束了! ###########################
上述实验,与我上面说明的一致。
下面,我们可以while循环来模拟for循环,输出列表中的元素。
l = [1,2,3,4,5] item = l.__iter__() # 生成一个迭代器 while True: try: i = item.__next__() print(i) except StopIteration: # 捕获异常,如果有异常,说明应该停止迭代 break
由上分析,我们可以总结出:当我们试图用for循环来迭代一个可迭代对象时候,for循环在内部进行了两步操作:第一,将可迭代对象S变为迭代器M;第二,迭代器M调用__next__()方法,并且返回其取出的元素给变量i。
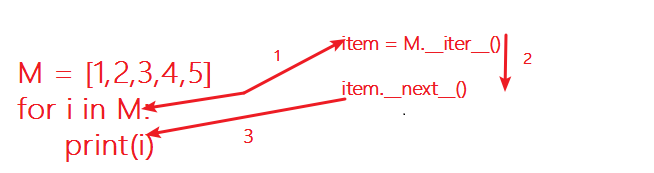
你可能看见过这种写法,for i in iter(M):xxx ,其实这一步操作和我们上面没什么区别。iter()函数,就是将一个可迭代对象M变为迭代器也就是M调用__iter__()方法,然后内部在调用__next__()方法。也就是说,
M = [1,2,3,4,5] for i in iter(M): # 等价于 M.__iter()__ 人为显示调用 print(i) for i in M: # 解释器隐式调用 print(i) ################# # #上面输出的结果完全一样 # #################
还有next(M)等价于M.__next__。
迭代器优点:
1.节约内存
2.不依赖索引取值
3.实现惰性计算(什么时候需要,在取值出来计算)
5.生成器(本质就是迭代器)
什么是生成器?可以理解为一种数据类型,这种数据类型自动实现了迭代器协议(其他的数据类型需要调用自己内置的__iter__方法)。
按照我们之前所说的,迭代器必须满足两个条件:既有__iter__(),又有__next__()方法。那么生成器是否也有这两个方法呢?答案是,YES。具体来通过以下代码来看看。
def func(): print("one------------->") yield 1 print("two------------->") yield 2 print("three----------->") yield 3 print("four------------>") yield 4 print(hasattr(func(),'__next__')) print(hasattr(func(),'__iter__')) #########输出结果########### True True
实验表明,生成器就是迭代器。
Python有两种不同的方式提供生成器:
1.生成器函数(函数内部有yield关键字):常规函数定义,但是,使用yield语句而不是return语句返回结果。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次重它离开的地方继续执行
2.生成器表达式:类似于列表推导,但是,生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
既然生成器就是迭代器,那么我们是不是也可以通过for循环来遍历出生成器中的内容呢?看下面代码.
def func(): print("one------------->") yield 1 print("two------------->") yield 2 print("three----------->") yield 3 print("four------------>") yield 4 for i in func(): print(i) #########输出结果######## one-------------> 1 two-------------> 2 three-----------> 3 four------------> 4
很显然,生成器也可以通过for循环来遍历出其中的内容。
下面我们来看看生成器函数执行流程:
def func(): print("one------------->") yield 1 print("two------------->") yield 2 print("three----------->") yield 3 print("four------------>") yield 4 g = func() # 生成器 == 迭代器 print(g.__next__()) print(g.__next__()) print(g.__next__()) print(g.__next__())
每次调用g.__next__()就回去函数内部找yield关键字,如果找得到就输出yield后面的值并且返回;如果没有找到,就会报出异常。上述代码中如果在调用g.__next__()就会报错。
Python使用生成器对延迟操作提供了支持。所谓延迟操作,是指在需要的时候才产生结果,而不是立即产生结果。这也是生成器的主要好处。
实例:生成器模拟Linux下tail -f a.txt | grep 'error' | grep '404'
import time def tail(filepath): with open(filepath, encoding='utf-8') as f: f.seek(0, 2) # 停到末尾开头 1从当前位置 2从文件末尾 while True: line = f.readline() if line: # 如果有内容读出 #print(line,end='') yield line # 遍历时停在此行,并且将其返回值传递出去 else: time.sleep(0.5) # 如果文件为空,休眠 等待输入 def grep(lines, patterns): # lines为生成器类型 for line in lines: # 遍历生成器 if patterns in line: yield line g = grep(tail('a.txt'), 'error') # 动态跟踪文件新添加的内容,并且过滤出有patterns的行 g1 = grep(g,'404') # g1为生成器 for i in g1: # 通过for循环来隐式调用__next__()方法 print(i)
生成器小结:
1.是可迭代对象
2.实现了延迟计算,省内存啊
3.生成器本质和其他的数据类型一样,都是实现了迭代器协议,只不过生成器附加了一个延迟计算省内存的好处,其余的可迭代对象可没有这点好处!
6.可迭代对象、迭代器、生成器关系总结
