编码的使用
ascii: 数字,字母, 特殊字符 组成
字节: 8bit 1byte
gbk: 国标码。16bit, 2byte
unicode: 万国码。32bit, 4byte
utf-8:可变长度的unicode
英文: 1byte 8bit
欧洲文字: 2byte,16bit
中文: 3byte, 24bit
以上的所有的编码都兼容ascii码,所以除了ascii码之外,其他信息不能直接进行转换
因为python2默认使用的是asslli 码进行编码,所以在python 2中的编码文件如下
 指明python解释器所在路径和编码的方式
指明python解释器所在路径和编码的方式
在python3中的内存里使用的是unicode编码,但是在保存代码时使用的是utf-8的编码方式。原因是unicode适合进行计算但是不适合存储,utf-8适合存储和传输
在python3的内存中. 在程序运行阶段. 使用的是unicode编码. 因为unicode是万国码. 什么内容都可以进行显示. 那么在数据传输和存储的时候由于unicode比较浪费空间和资源. 需要把unicode转存成UTF-8或者GBK进行存储. 怎么转换呢. 在python中可以把文字信息进行编码.编码之后的内容就可以进行传输了. 编码之后的数据是bytes类型的数据.其实啊. 还是原来的数据只是经过编码之后表现形式发生了改变而已.
bytes的表现形式(一般认为bytes是python中最小的数据单元)
b'xxxxx' 这种格式的数据是bytes类型的数据,数据传输中。包括文字。 图片。 视频都是bytes。转换成bytes的时候一般是用于传输和存储
对于英文: 无论使用什么的编码方式转换的bytes都是与ascii码一样的
eg:
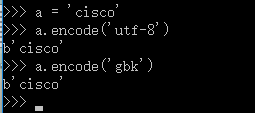
对于中文:由于utf-8 与 gbk中对于中文的编码使用的字节是不一样的utf-8使用的是3个字节表示一个中文字符,而gbk 使用的是2个字节对应一个中文字符
所以中文转化成bytes,如下:
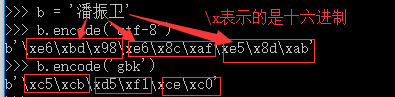
在网络传输和存储的时候我们python是保存和存储的bytes类型. 那么在对方接收的时候. 也是接收的bytes类型的数据. 我们可以使用decode()来进行解码操作. 把bytes类型的数据还原回我们熟悉的字符串:
对上面的进行解码如下:

小数据池
小数据池. 一种数据缓存机制. 也被称为驻留机制. 各大编程语言中都有类似的东西. 在⽹上搜索常量量池,小数据池指的都是同一个内容.小数据池只针对:整数, 字符串, 布尔值. 其他的数据类型不存在驻留机制,对于整数,python中对-5到256之间的整数会被驻留在内存中. 但是不在这个区间的话,是不存在驻留机制的

但在pycharm 中只要你只是对变量进行赋值,但是没有进行运算的话,那么无论字符串是多长或者数据有多大都是用友驻留的机制,但是进行运算之后都会按照上面的方式判断是否存在驻留
小数据池 is和==的区别
== 判断左右两端的值是否相等. 是不是一致.
判断左右两端内容的内存地址是否一致. 如果返回True, 那可以确定这两个变量使
用的是同一个对象