一、前言
因为之前在项目中使用了Groovy对业务能力进行一些扩展,效果比较好,所以简单记录分享一下,这里你可以了解:
-
为什么选用Groovy作为脚本引擎
-
了解Groovy的基本原理和Java如何集成Groovy
-
在项目中使用脚本引擎时做的安全和性能优化
-
实际使用的一些建议
二、为什么使用脚本语言
2.1 脚本语言可解决的问题
互联网时代随着业务的飞速发展,不仅产品迭代、更新的速度越来越快,个性化需求也是越来越多,如:多维度(条件)的查询、业务流转规则等。办法通常有如下几个方面:
-
最常见的方式是用代码枚举所有情况,即所有查询维度、所有可能的规则组合,根据运行时参数遍历查找;
-
使用开源方案,例如drools规则引擎,此类引擎适用于业务基于规则流转,且比较复杂的系统;
-
使用动态脚本引擎,例如Groovy,JSR223。注:JSR即 Java规范请求,是指向JCP(Java Community Process)提出新增一个标准化技术规范的正式请求。任何人都可以提交JST,以向Java平台增添新的API和服务。JSR是Java界的一个重要标准。JSR223提供了一种从Java内部执行脚本编写语言的方便、标准的方式,并提供从脚本内部访问Java资源和类的功能,即为各脚本引擎提供了统一的接口、统一的访问模式。JSR223不仅内置支持Groovy、Javascript、Aviator,而且提供SPI扩展,笔者曾通过SPI扩展实现过Java脚本引擎,将Java代码“脚本化”运行。
引入动态脚本引擎对业务进行抽象可以满足定制化需求,大大提升项目效率。例如,笔者现在开发的内容平台系统中,下游的内容需求方根据不同的策略会要求内容平台圈选指定内容推送到指定的处理系统,这些处理系统处理完后,内容平台接收到处理结果再根据分发策略(规则)下发给推荐系统。每次圈选内容都要写一堆对于此次圈选的查询逻辑,内容下发的策略也经常需要变更。所以想利用脚本引擎的动态解析执行,使用规则脚本将查询条件以及下发策略抽象出来,提升效率。
2.2 技术选型
对于脚本语言来说,最常见的就是Groovy,JSR233也内置了Groovy。对于不同的脚本语言,选型时需要考虑性能、稳定性、灵活性,综合考虑后选择Groovy,有如下几点原因:
-
学习曲线平缓,有丰富的语法糖,对于Java开发者非常友好;
-
技术成熟,功能强大,易于使用维护,性能稳定,被业界看好;
-
和Java兼容性强,可以无缝衔接Java代码,可以调用Java所有的库。
2.3 业务改造
因为运营、产品同学对于内容的需求在不断的调整,内容平台圈选内容的能力需要能够支持各种查询维度的组合。内容平台起初开发了一个查询组合为(状态,入库时间,来源方,内容类型),并定向分发到内容理解和打标的接口。但是这个接口已经不能满足需求的变化,为此,最容易想到的设计就是枚举所有表字段(如发布时间、作者名称等近20个),使其成为查询条件。但是这种设计的开发逻辑其实是很繁琐的,也容易造成慢查询;比如:筛选指定合作方和等级S的up主,且对没有内容理解记录的视频,调用内容理解接口,即对这部分视频进行内容理解。为了满足需求,需要重新开发,结果就是write once, run only once,造成开发和发版资源的浪费。
不管是JDBC for Mysql,还是JDBC for MongoDB都是面向接口编程,即查询条件是被封装成接口的。基于面向接口的编程模式,查询条件Query接口的实现可以由脚本引擎动态生成,这样就可以满足任何查询场景。执行流程如下图3.1。
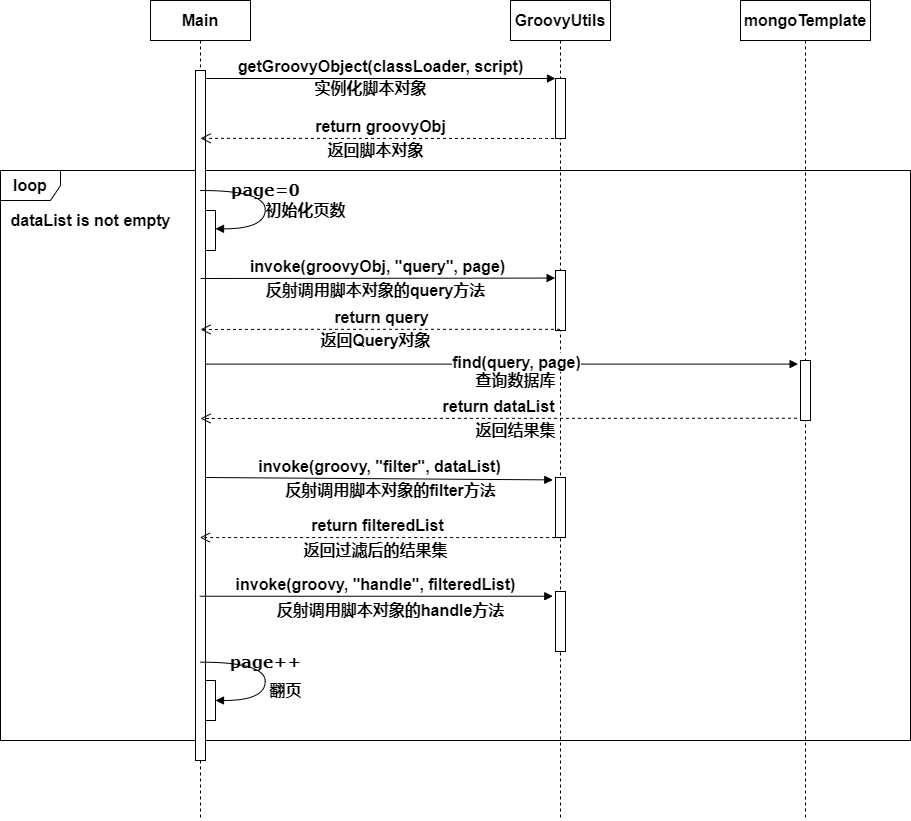
下面给出脚本的代码Demo:
/**
* 构建查询对象Query
* 分页查询mongodb
*/
public Query query(int page){
String source = "Groovy";
String articleType = 4; // (source,articleType) 组成联合索引,提高查询效率
Query query = Query.query(where("source").is(source)); // 查询条件1:source="Groovy"
query.addCriteria(where("articleType").is(articleType)); // 查询条件2:articleType=4
Pageable pageable = new PageRequest(page, PAGESIZE);
query.with(pageable);// 设置分页
query.fields().include("authorId"); // 查询结果返回authorId字段
query.fields().include("level"); // 查询结果返回level字段
return query;
}
/**
* 过滤每一页查询结果
*/
public boolean filter(UpAuthor upAuthor){
return !"S".equals(upAuthor.getLevel(); // 过滤掉 level != S 的作者
}
/**
* 对查询结果集逐条处理
*/
public void handle(UpAuthor upAuthor) {
UpAthorService upAuthorService = SpringUtil.getBean("upAuthorService"); // 从Spring容器中获取执行java bean
if(upAuthorService == null){
throw new RuntimeException("upAuthorService is null");
}
AnalysePlatService analysePlatService = SpringUtil.getBean("analysePlatService"); // 从Spring容器中获取执行java bean
if(analysePlatService == null){
throw new RuntimeException("analysePlatService is null");
}
List<Article> articleList = upAuthorService.getArticles(upAuthor);// 获取作者名下所有视频
if(CollectionUtils.isEmpty(articleList)){
return;
}
articleList.forEach(article->{
if(article.getAnalysis() == null){
analysePlatService.analyse(article.getArticleId()); // 提交视频给内容理解处理
}
})
}
理论上,可以指定任意查询条件,编写任意业务逻辑,从而对于流程、规则经常变化的业务来说,摆脱了开发和发版的时空束缚,从而能够及时响应各方的业务变更需求。
三、Groovy与Java集成
3.1 Groovy基本原理
Groovy的语法很简洁,即使不想学习其语法,也可以在Groovy脚本中使用Java代码,兼容率高达90%,除了lambda、数组语法,其他Java语法基本都能兼容。这里对语法不多做介绍,有兴趣可以自行阅读 https://www.w3cschool.cn/groovy 进行学习。
3.2 在Java项目中集成Groovy
3.2.1 ScriptEngineManager
按照JSR223,使用标准接口ScriptEngineManager调用。
ScriptEngineManager factory = new ScriptEngineManager();
ScriptEngine engine = factory.getEngineByName("groovy");// 每次生成一个engine实例
Bindings binding = engine.createBindings();
binding.put("date", new Date()); // 入参
engine.eval("def getTime(){return date.getTime();}", binding);// 如果script文本来自文件,请首先获取文件内容
engine.eval("def sayHello(name,age){return 'Hello,I am ' + name + ',age' + age;}");
Long time = (Long) ((Invocable) engine).invokeFunction("getTime", null);// 反射到方法
System.out.println(time);
String message = (String) ((Invocable) engine).invokeFunction("sayHello", "zhangsan", 12);
System.out.println(message);
3.2.2 GroovyShell
Groovy官方提供GroovyShell,执行Groovy脚本片段,GroovyShell每一次执行时代码时会动态将代码编译成Java Class,然后生成Java对象在Java虚拟机上执行,所以如果使用GroovyShell会造成Class太多,性能较差。
final String script = "Runtime.getRuntime().availableProcessors()";
Binding intBinding = new Binding();
GroovyShell shell = new GroovyShell(intBinding);
final Object eval = shell.evaluate(script);
System.out.println(eval);
3.2.3 GroovyClassLoader
Groovy官方提供GroovyClassLoader类,支持从文件、url或字符串中加载解析Groovy Class,实例化对象,反射调用指定方法。
GroovyClassLoader groovyClassLoader = new GroovyClassLoader();
String helloScript = "package com.vivo.groovy.util" + // 可以是纯Java代码
"class Hello {" +
"String say(String name) {" +
"System.out.println("hello, " + name)" +
" return name;"
"}" +
"}";
Class helloClass = groovyClassLoader.parseClass(helloScript);
GroovyObject object = (GroovyObject) helloClass.newInstance();
Object ret = object.invokeMethod("say", "vivo"); // 控制台输出"hello, vivo"
System.out.println(ret.toString()); // 打印vivo
3.3 性能优化
当JVM中运行的Groovy脚本存在大量并发时,如果按照默认的策略,每次运行都会重新编译脚本,调用类加载器进行类加载。不断重新编译脚本会增加JVM内存中的CodeCache和Metaspace,引发内存泄露,最后导致Metaspace内存溢出;类加载过程中存在同步,多线程进行类加载会造成大量线程阻塞,那么效率问题就显而易见了。
为了解决性能问题,最好的策略是对编译、加载后的Groovy脚本进行缓存,避免重复处理,可以通过计算脚本的MD5值来生成键值对进行缓存。下面我们带着以上结论来探讨。
3.3.1 Class对象的数量
3.3.1.1 GroovyClassLoader加载脚本
上面提到的三种集成方式都是使用GroovyClassLoader显式地调用类加载方法parseClass,即编译、加载Groovy脚本,自然地脱离了Java著名的ClassLoader双亲委派模型。
GroovyClassLoader主要负责运行时处理Groovy脚本,将其编译、加载为Class对象的工作。查看关键的GroovyClassLoader.parseClass方法,如下所示代码3.1.1.1(出自JDK源码)。
public Class parseClass(String text) throws CompilationFailedException {
return parseClass(text, "script" + System.currentTimeMillis() +
Math.abs(text.hashCode()) + ".groovy");
}
public Class parseClass(GroovyCodeSource codeSource, boolean shouldCacheSource) throws CompilationFailedException {
synchronized (sourceCache) { // 同步块
Class answer = sourceCache.get(codeSource.getName());
if (answer != null) return answer;
answer = doParseClass(codeSource);
if (shouldCacheSource) sourceCache.put(codeSource.getName(), answer);
return answer;
}
}
系统每执行一次脚本,都会生成一个脚本的Class对象,这个Class对象的名字由 "script" + System.currentTimeMillis()+Math.abs(text.hashCode()组成,即使是相同的脚本,也会当做新的代码进行编译、加载,会导致Metaspace的膨胀,随着系统不断地执行Groovy脚本,最终导致Metaspace溢出。
继续往下跟踪代码,GroovyClassLoader编译Groovy脚本的工作主要集中在doParseClass方法中,如下所示代码3.1.1.2(出自JDK源码):
private Class doParseClass(GroovyCodeSource codeSource) {
validate(codeSource); // 简单校验一些参数是否为null
Class answer;
CompilationUnit unit = createCompilationUnit(config, codeSource.getCodeSource());
SourceUnit su = null;
if (codeSource.getFile() == null) {
su = unit.addSource(codeSource.getName(), codeSource.getScriptText());
} else {
su = unit.addSource(codeSource.getFile());
}
ClassCollector collector = createCollector(unit, su); // 这里创建了GroovyClassLoader$InnerLoader
unit.setClassgenCallback(collector);
int goalPhase = Phases.CLASS_GENERATION;
if (config != null && config.getTargetDirectory() != null) goalPhase = Phases.OUTPUT;
unit.compile(goalPhase); // 编译Groovy源代码
answer = collector.generatedClass; // 查找源文件中的Main Class
String mainClass = su.getAST().getMainClassName();
for (Object o : collector.getLoadedClasses()) {
Class clazz = (Class) o;
String clazzName = clazz.getName();
definePackage(clazzName);
setClassCacheEntry(clazz);
if (clazzName.equals(mainClass)) answer = clazz;
}
return answer;
}
继续来看一下GroovyClassLoader的createCollector方法,如下所示代码3.1.1.3(出自JDK源码):
protected ClassCollector createCollector(CompilationUnit unit, SourceUnit su) {
InnerLoader loader = AccessController.doPrivileged(new PrivilegedAction<InnerLoader>() {
public InnerLoader run() {
return new InnerLoader(GroovyClassLoader.this); // InnerLoader extends GroovyClassLoader
}
});
return new ClassCollector(loader, unit, su);
}
public static class ClassCollector extends CompilationUnit.ClassgenCallback {
private final GroovyClassLoader cl;
// ...
protected ClassCollector(InnerLoader cl, CompilationUnit unit, SourceUnit su) {
this.cl = cl;
// ...
}
public GroovyClassLoader getDefiningClassLoader() {
return cl;
}
protected Class createClass(byte[] code, ClassNode classNode) {
GroovyClassLoader cl = getDefiningClassLoader(); // GroovyClassLoader$InnerLoader
Class theClass = cl.defineClass(classNode.getName(), code, 0, code.length, unit.getAST().getCodeSource()); // 通过InnerLoader加载该类
this.loadedClasses.add(theClass);
// ...
return theClass;
}
// ...
}
ClassCollector的作用,就是在编译的过程中,将编译出来的字节码,通过InnerLoader进行加载。另外,每次编译groovy源代码的时候,都会新建一个InnerLoader的实例。那有了 GroovyClassLoader ,为什么还需要InnerLoader呢?主要有两个原因:
加载同名的类
类加载器与类全名才能确立Class对象在JVM中的唯一性。由于一个ClassLoader对于同一个名字的类只能加载一次,如果都由GroovyClassLoader加载,那么当一个脚本里定义了com.vivo.internet.Clazz这个类之后,另外一个脚本再定义一个com.vivo.internet.Clazz类的话,GroovyClassLoader就无法加载了。
回收Class对象
由于当一个Class对象的ClassLoader被回收之后,这个Class对象才可能被回收,如果由GroovyClassLoader加载所有的类,那么只有当GroovyClassLoader被回收了,所有这些Class对象才可能被回收,而如果用InnerLoader的话,由于编译完源代码之后,已经没有对它的外部引用,它就可以被回收,由它加载的Class对象,才可能被回收。下面详细讨论Class对象的回收。
3.3.1.2 JVM回收Class对象
什么时候会触发Metaspace的垃圾回收?
-
Metaspace在没有更多的内存空间的时候,比如加载新的类的时候;
-
JVM内部又一个叫做_capacity_until_GC的变量,一旦Metaspace使用的空间超过这个变量的值,就会对Metaspace进行回收;
-
FGC时会对Metaspace进行回收。
大家可能这里会有疑问:就算Class数量过多,只要Metaspace触发GC,那应该就不会溢出了。为什么上面会给出Metaspace溢出的结论呢?这里引出下一个问题:JVM回收Class对象的条件是什么?
-
该类所有的实例都已经被GC,也就是JVM中不存在该Class的任何实例;
-
加载该类的ClassLoader已经被GC;
-
java.lang.Class对象没有在任何地方被引用。
条件1,GroovyClassLoader会把脚本编译成一个类,这个脚本类运行时用反射生成一个实例并调用它的入口函数执行(详见图3.1),这个动作一般只会被执行一次,在应用里面不会有其他地方引用该类或它生成的实例,该条件至少是可以通过规范编程来满足。条件2,上面已经分析过,InnerClassLoader用完后即可被回收,所以条件可以满足。条件3,由于脚本的Class对象一直被引用,条件无法满足。
为了验证条件3是无法满足的结论,继续查看GroovyClassLoader中的一段代码3.1.2.1(出自JDK源码):
/**
* this cache contains the loaded classes or PARSING, if the class is currently parsed
*/
protected final Map<String, Class> classCache = new HashMap<String, Class>();
protected void setClassCacheEntry(Class cls) {
synchronized (classCache) { // 同步块
classCache.put(cls.getName(), cls);
}
}
加载的Class对象,会缓存在GroovyClassLoader对象中,导致Class对象不可被回收。
3.3.2 高并发时线程阻塞
上面有两处同步代码块,详见代码3.1.1.1和代码3.1.2.1。当高并发加载Groovy脚本时,会造成大量线程阻塞,一定会产生性能瓶颈。
3.3.3 解决方案
-
对于 parseClass 后生成的 Class 对象进行缓存,key 为 Groovy脚本的md5值,并且在配置端修改配置后可进行缓存刷新。这样做的好处有两点:(1)解决Metaspace爆满的问题;(2)因为不需要在运行时编译加载,所以可以加快脚本执行的速度。
-
GroovyClassLoader的使用用参考Tomcat的ClassLoader体系,有限个GroovyClassLoader实例常驻内存,增加处理的吞吐量。
-
脚本静态化:Groovy脚本里面尽量都用Java静态类型,可以减少Groovy动态类型检查等,提高编译和加载Groovy脚本的效率。
四、安全
4.1 主动安全
4.1.1 编码安全
Groovy会自动引入java.util,java.lang包,方便用户调用,但同时也增加了系统的风险。为了防止用户调用System.exit或Runtime等方法导致系统宕机,以及自定义的Groovy片段代码执行死循环或调用资源超时等问题,Groovy提供了SecureASTCustomizer安全管理者和SandboxTransformer沙盒环境。
final SecureASTCustomizer secure = new SecureASTCustomizer();// 创建SecureASTCustomizer
secure.setClosuresAllowed(true);// 禁止使用闭包
List<Integer> tokensBlacklist = new ArrayList<>();
tokensBlacklist.add(Types.**KEYWORD_WHILE**);// 添加关键字黑名单 while和goto
tokensBlacklist.add(Types.**KEYWORD_GOTO**);
secure.setTokensBlacklist(tokensBlacklist);
secure.setIndirectImportCheckEnabled(true);// 设置直接导入检查
List<String> list = new ArrayList<>();// 添加导入黑名单,用户不能导入JSONObject
list.add("com.alibaba.fastjson.JSONObject");
secure.setImportsBlacklist(list);
List<Class<? extends Statement>> statementBlacklist = new ArrayList<>();// statement 黑名单,不能使用while循环块
statementBlacklist.add(WhileStatement.class);
secure.setStatementsBlacklist(statementBlacklist);
final CompilerConfiguration config = new CompilerConfiguration();// 自定义CompilerConfiguration,设置AST
config.addCompilationCustomizers(secure);
GroovyClassLoader groovyClassLoader = new GroovyClassLoader(this.getClass().getClassLoader(), config);
4.1.2 流程安全
通过规范流程,增加脚本执行的可信度。
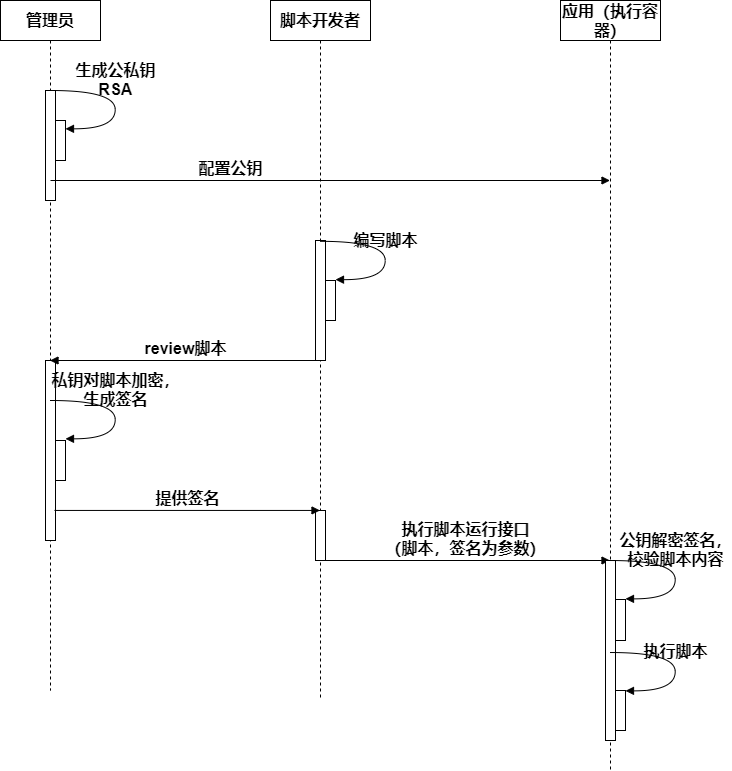
4.2 被动安全
虽然SecureASTCustomizer可以对脚本做一定程度的安全限制,也可以规范流程进一步强化,但是对于脚本的编写仍然存在较大的安全风险,很容易造成cpu暴涨、疯狂占用磁盘空间等严重影响系统运行的问题。所以需要一些被动安全手段,比如采用线程池隔离,对脚本执行进行有效的实时监控、统计和封装,或者是手动强杀执行脚本的线程。
五、总结
Groovy是一种动态脚本语言,适用于业务变化多又快以及配置化的需求实现。Groovy极易上手,其本质也是运行在JVM的Java代码。Java程序员可以使用Groovy在提高开发效率,加快响应需求变化,提高系统稳定性等方面更进一步。
作者:vivo互联网服务器团队-Gao Xiang