4.1
强化学习——一开始什么都不知道
通过采取action之后得到的分数来进行学习——具有分数导向性
这个分数和监督学习中的标签类似
强化学习一开始没有数据和标签:通过一次次的尝试来获得数据和标签
比较有名的算法

4.2
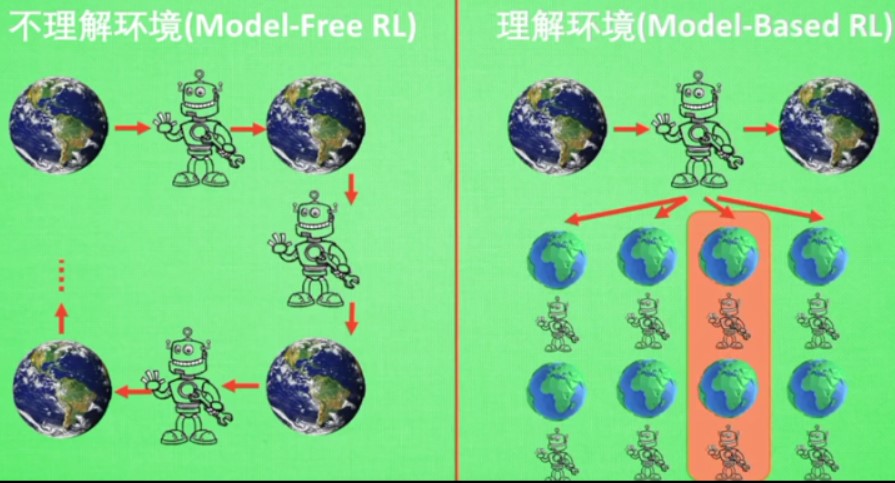
强化学习算法分为

- 理解环境(model-based RL)
用模型建立对环境的描述 - 不理解环境(model-free RL)
model-free RL不理解环境,只能一步步等待环境给予反馈,然后根据反馈采取下一步的行动
而model-based RL 可以想象所有可能的反馈,然后根据最好的情况采取行动
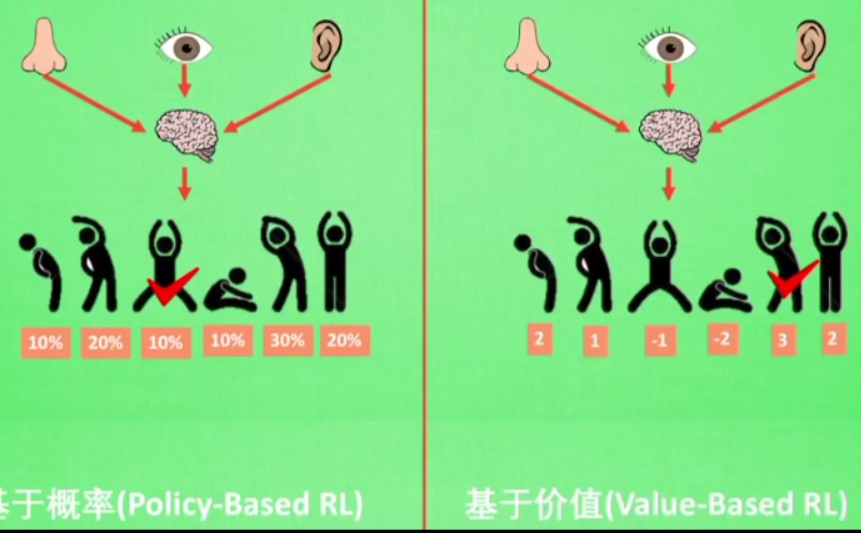
另一种分类方法:
- 基于概率
每个动作都可能被选中,只是概率不同而已
如果动作是连续的,那么基于价值的就不行 - 基于价值
相对比较固定,只选择价值最高的
还有一种分类方法
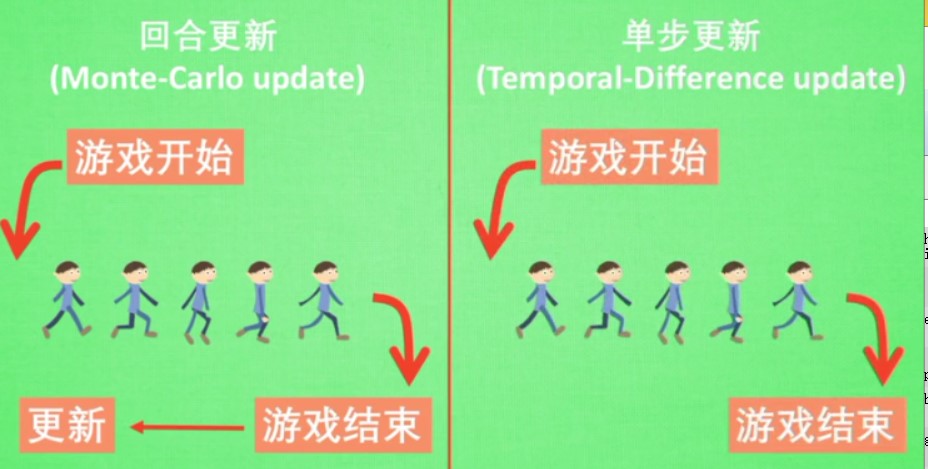

在线学习和离线学习
离线学习:不一定是自己的经历,也不一定是边玩边学习


4.3 什么是Q learning

关键在于Q表的生成,更新的
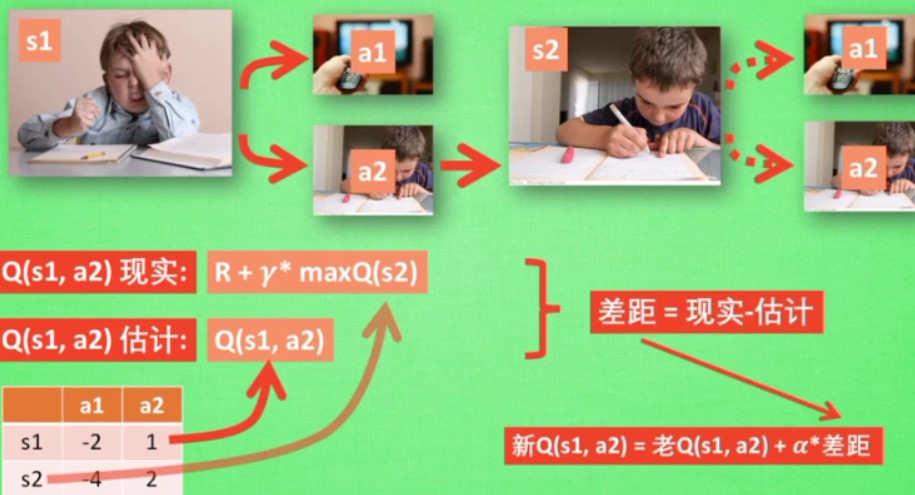
对于这个图,先进行一定的估计,然后根据估计的结果更新之后,再进行新的真正的选择

e-greedy表示有多少的概率根据Q表进行走的
α表示学习速度
γ表示未来奖励的衰减值
4.4 sarsa
和Q learning类似
也是用Q表
区别在于sarse中Q表的更新方式
在Qlearning中用于更新Q表的a2不一定是后续实际执行的动作,但是在Sarsa中,用于更新Q表的一定也是后续实际执行的动作,所以在Q现实中会去掉max
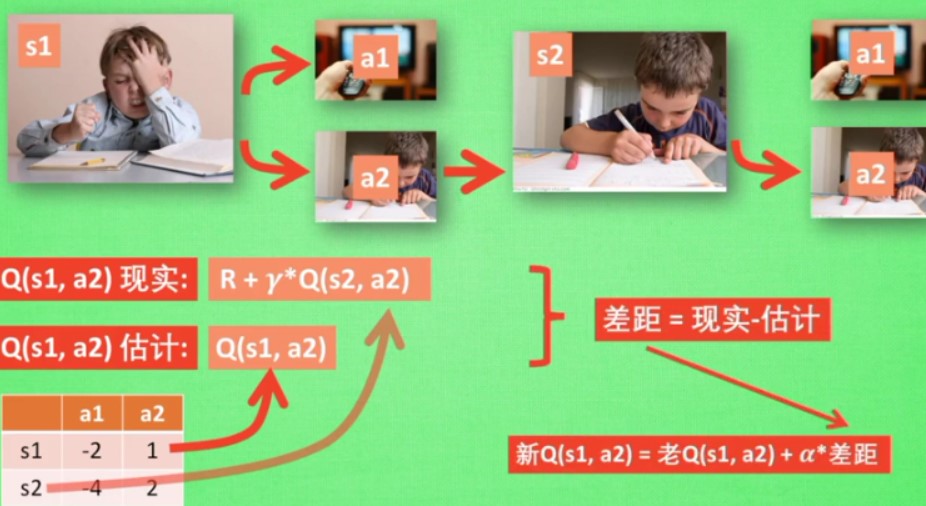
sarsa:说到做到
Q-Learning:说到不一定能够做到
所以Sarsa是 on-policy算法,Q-learning是off-policy算法

sarsa是一个保守的算法
Q-learning是一个相对比较勇敢的算法
4.5 Sarsa λ
λ是指更新的步数间隔
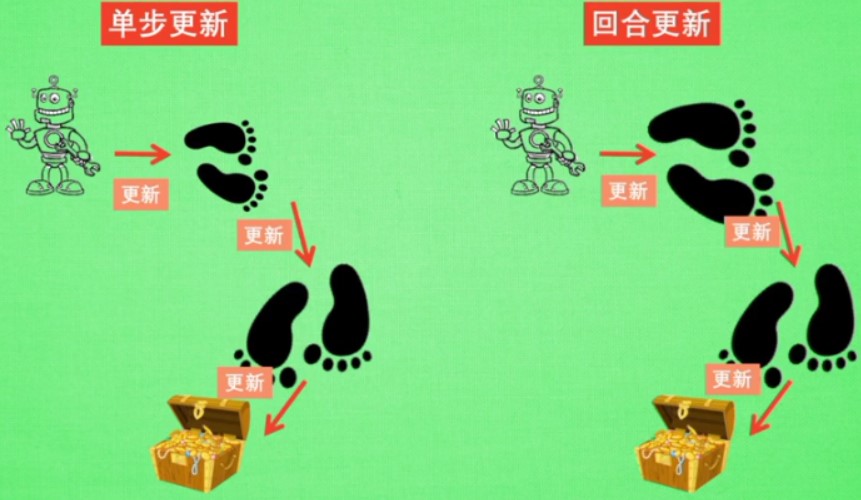
单步更新:只有在得到宝藏的前一步认为是和得到宝藏相关的
回合更新:整个得到宝藏的路径都认为是和得到宝藏相关的,在后续的选择的时候,选择的概率更大,但是在整个回合中,一开始的步可能和得到宝藏的关系不是很大,所以用λ来描述和得到宝藏的距离,离宝藏越近,认为是越重要
λ取0:单步更新
λ取1:回合更新
λ取0~1:更有效率的更新相关步
4.6 DQN
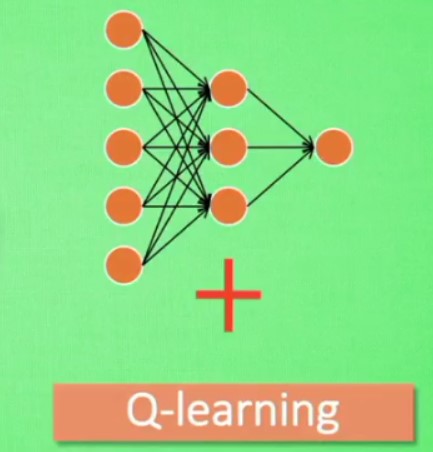
用传统的Q表的话,当问题很大的时候,对于存储和搜索来说都不是很好
用NN代替Q表
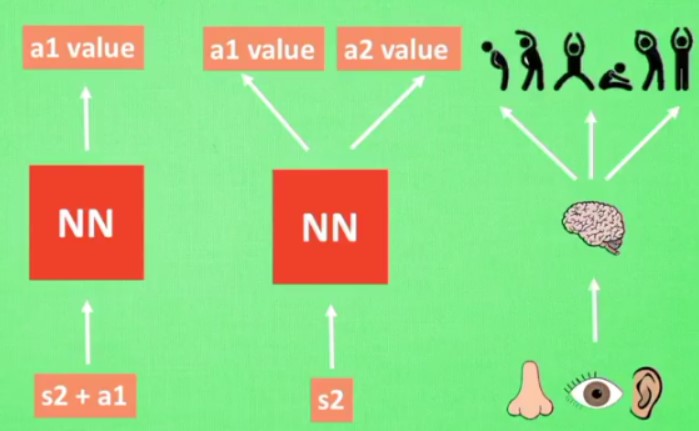
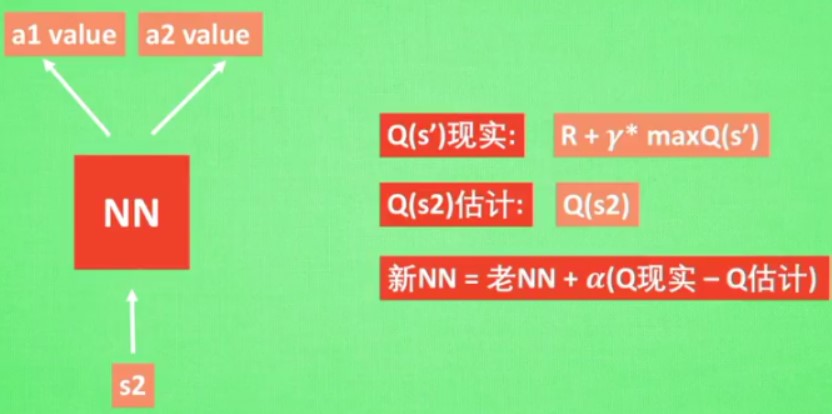
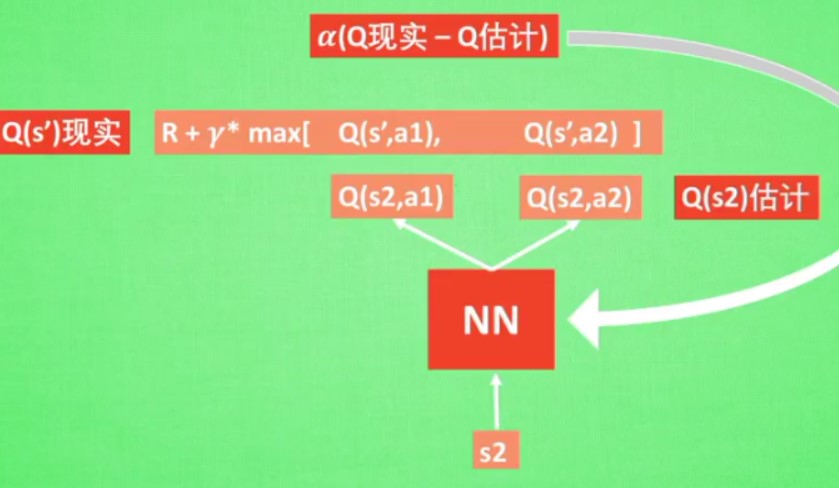
这个是DQN的神经网络的更新方式
但是还有两个技术使得DQN具有强大能力
Experience replay和Fixed-Qtarget
- Experience replay
Q learning是一个离线学习的法
每次可以随机选取一个以往的经历进行学习
可以打乱经历之间的关联性 - Fixed Q- target
也可以打乱经历之间的关联性
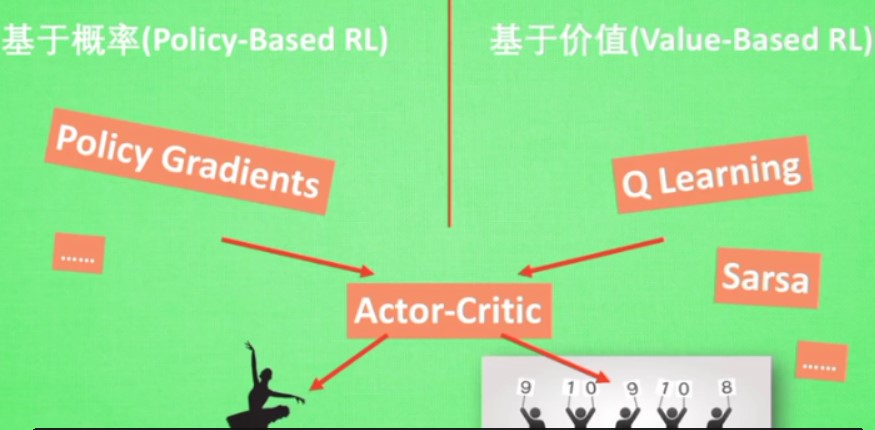
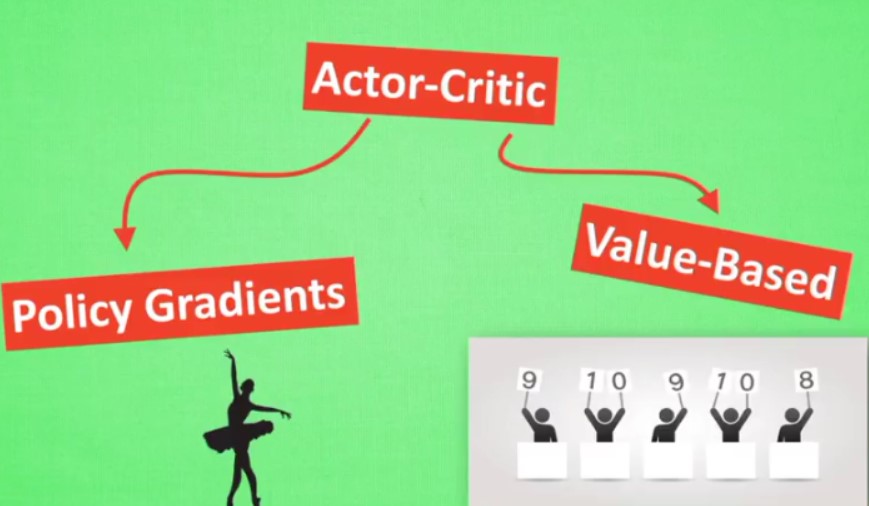
4.8 Actor critic
结合了以值为基础和以动作为基础的算法
actor的前身是以动作为基础的 policy gradien t,回合更新,学习效率不高
critic的前身是value-based,单步更新
actor和critic都可以用神经网络进行描述
用actor来进行指手画脚,用critic告诉actor那些动作好哪些动作差,可以进行单步更新
但是,actor critic每次都在连续环境中进行更新,而且每次更新前后都存在相关性,导致神经网络只能片面的看待问题,甚至学不到东西
DeepMind对其进行修改,加入DQN:解决在连续动作中预测学不到东西的问题

4.9 DDPG
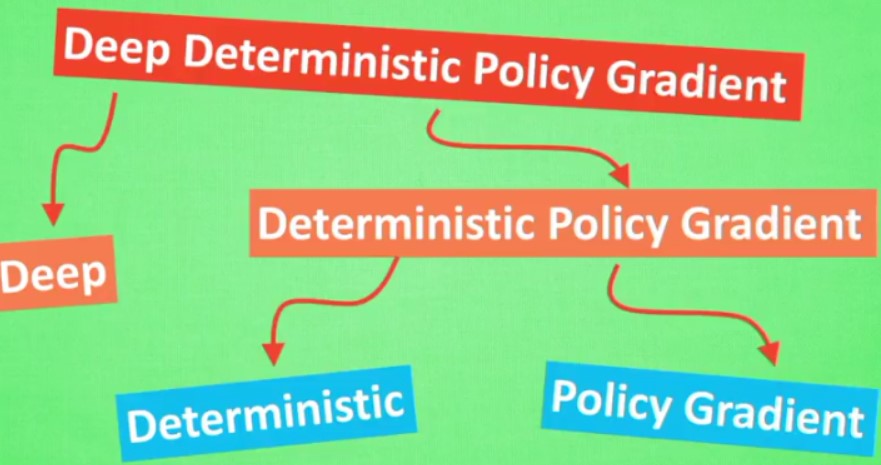
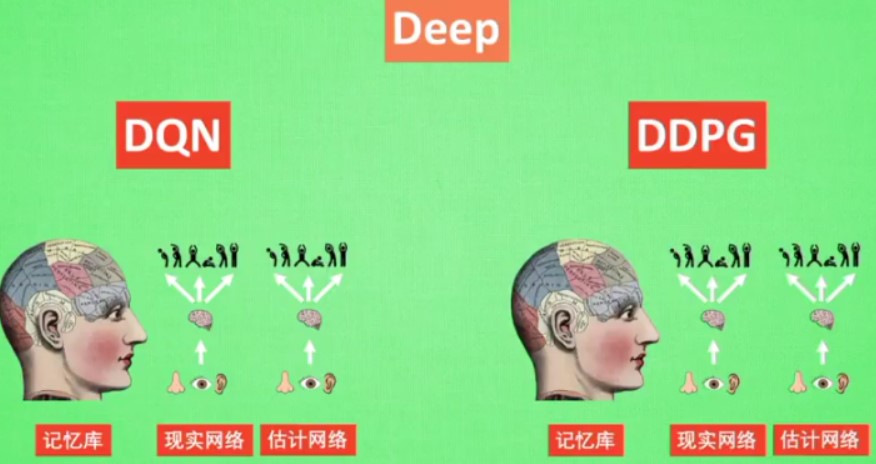
- Deep:走向更深的层次
使用一个记忆库和两个结构相同但是参数更新频率不同的网络可以更加有效的学习
和DQN类似,但是DDPG更加复杂一点
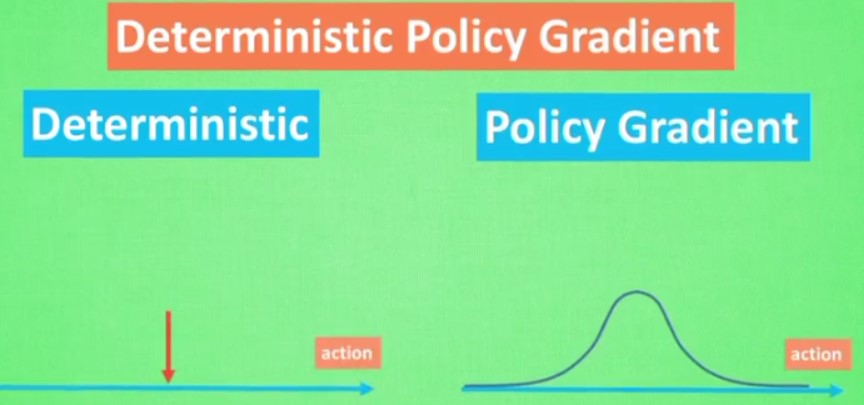
- Deterministic Policy Gradient
policy Gradient是给出多个动作每个的概率,随机选择
但是determistic则选择一个确定的值
DDPG有actor和critic,这两个部分又进一步的各自细分为两个神经网络
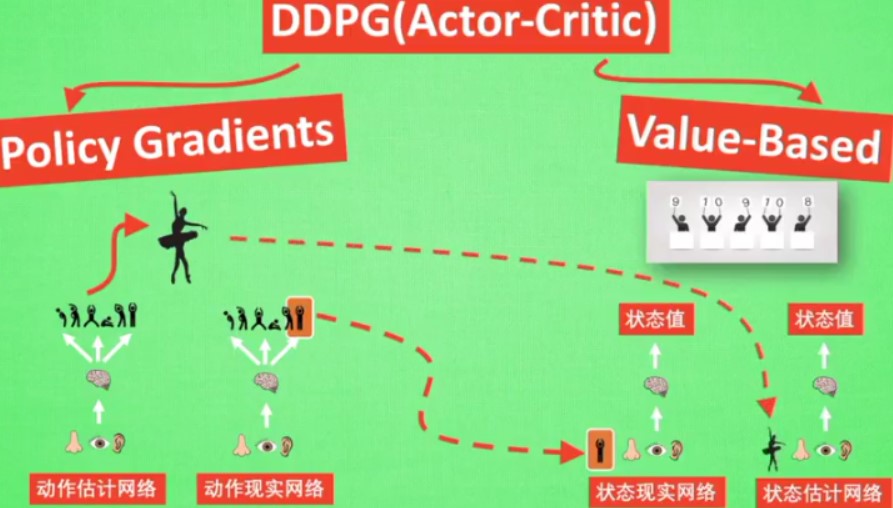
动作现实网络:更新价值网络系统
动作估计网络:输出实时的动作,供actor进行实行
状态现实网络:输出状态值,输入-根据从动作现实网络中得到的动作,根据当前状态观测值加以分析,
状态估计网络:输出状态值,输入-根据actor实际施加的动作
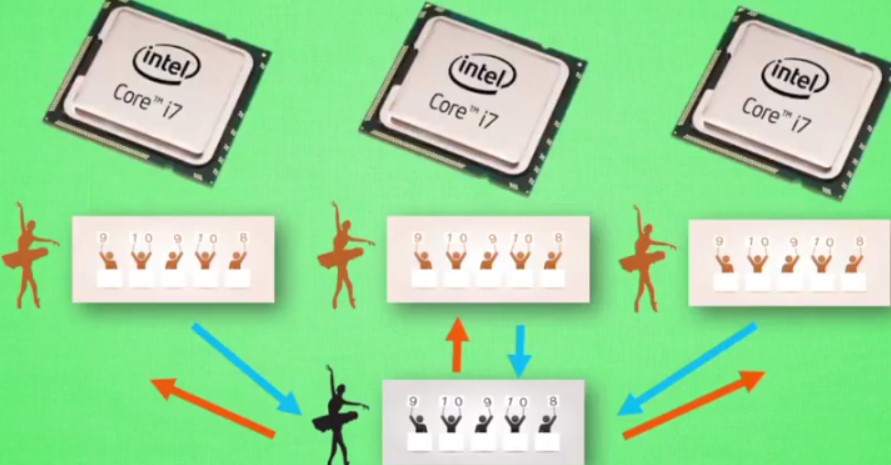
4.10 A3C
多个agent同时进行学习——平行世界
将actor复制多个,各自放在一个单独世界进行学习,并且可以将学习的结果回传给父本
然后从父本中得到其他actor学习的经验
使用A3C可以将这个副本各自放在不同的核中进行学习
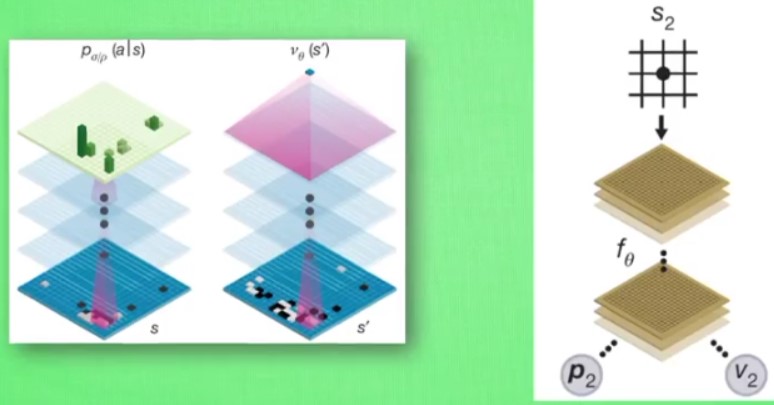
4.11 AlphaGo Zero
- AlphaGo
用树形结构尝试很多的策略,每个分支的都是一种情况
但是围棋的策略太多,目前无法完全计算——利用MCTS
MCTS:探索和
用的深度搜索
用了两个神经网络,一个基于当前状态给出下一个动作,另一个用来评估当前状态是否有利
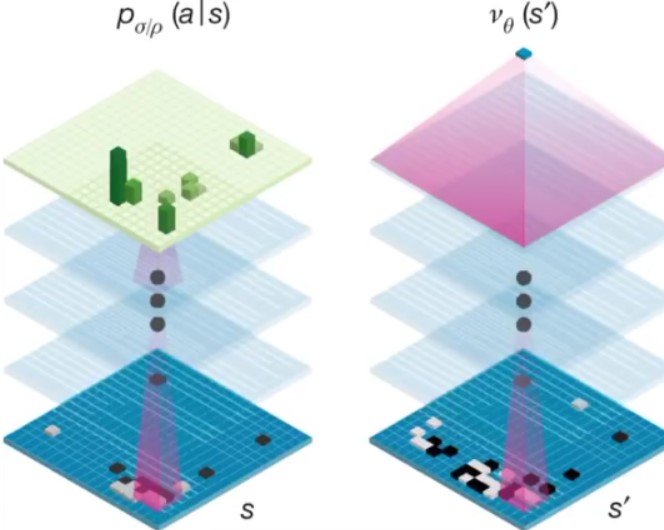
神经网络+搜索树:提供好的下棋行为,然后将这些行为作为训练数据反过来训练神经网络,用强化学习的思想提高其能力

- AlphaGo Zero
不需要学习人类棋谱,无师自通
打破人类下棋的思维
用的是一个神经网络系统,更好的利用资源