总结
Visual Studio的Web Performance Test是基于HTTP协议层的,它不依赖于浏览器,通过直接接收,发送HTTP包来和Web服务器交互。Web Performance Test发送和接收的一系列请求和响应之间存在相关性,例如,用户登录后,SID被传递给客户端,下一次请求时,需要把SID发送到服务器。因此,Web Perfomance Test 定义了多种提取规则,帮助从服务器响应中提取信息,用于之后的请求。或者保存起来,作为测试结果的一部分。
Web Performance Test提供多种提取规则,以下表格来自MSDN:
| 提取规则的类型 | 说明 |
| Selected Option | 提取列表或组合框中的选定文本。 |
| Tag Inner Text | 从指定的 HTML 标记中提取内部文本。 |
| Extract Attribute Value | 从指定的 HTML 标记中提取特性的值。 有关以下内容的更多信息使用提取特性值规则的更多信息,请参见演练:向 Web 性能测试添加验证规则和提取规则。 |
| Extract Form Field | 提取响应中指定窗体字段的值。 |
| Extract HTTP Header | 提取 HTTP 标头的值。 |
| Extract Regular Expression | 从与正则表达式相匹配的响应中提取文本。 |
| Extract Text | 从响应中提取文本。 |
| Extract Hidden Fields | 从响应中提取所有的隐藏字段。 |
在 (1)和(2)中,我们讲解了系统默认的一些提取规则,本文将讲解如何建立自定义提取规则,本文的代码可以从这里下载。
继承ExtractionRule
所有的提取规则,包括自定义规则都需要从ExtractionRule继承,该类在Microsoft.VisualStudio.QualityTools.WebTestFramework.dll中实现。
独立的Library
我们最好把自定义规则都放到一个独立的类库中,这样方便多个web performance test 工程引用。 web performance test 工程只要引用了该类库,在右键点击URL,选择Add Extraction Rule中,在打开的Add Extraction Rule窗口中,就可以看到所有的自定义提取规则,和用法系统默认的规则完全相同。
例子
本文继续沿用(2)中的例子,那是一个简单的算术站点:
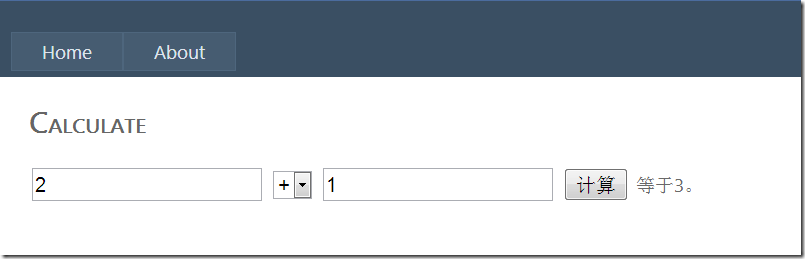
在(2)中,我们发现Extract Regular Express规则不适合把“等于3。”中的数字提取出来,它提取的值将会包括整个文本。那么,本文将定义一个“Custom Extract Regular Express”,实现通过正则表达式提取其中的数字,而不是整个文本。
看代码:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Globalization;
using Microsoft.VisualStudio.TestTools.WebTesting;
using System.ComponentModel;
using System.Text.RegularExpressions;
using System.Web;
namespace CustomExtractionRule
{
[DescriptionAttribute("Extracts the specificed group from mached regex")]
[DisplayNameAttribute("Custom Extract Regular Expression")]
public class CustomExtractRegularExpression : ExtractionRule
{
[DescriptionAttribute("Whether or not to perfom HTML decoding of extracted strings.")]
[DisplayNameAttribute("Html Decode")]
[DefaultValue(true)]
public bool HtmlDecode { get; set; }
[DefaultValue(false)]
[DescriptionAttribute("Ignore case during search for matching text.")]
[DisplayNameAttribute("Ignore Case")]
public bool IgnoreCase { get; set; }
[DefaultValue(0)]
[DescriptionAttribute("Indicates which occurrence of the string to extract. this is a zero-based index.")]
[DisplayNameAttribute("Index")]
public int Index { get; set; }
[DescriptionAttribute("Specify the regular expression to search for.")]
[DisplayNameAttribute("Regular Expression")]
public string RegularExpression { get; set; }
[DefaultValue(true)]
[DescriptionAttribute("If ture, the extraction rule fails if no value is found to extract.")]
[DisplayNameAttribute("Required")]
public bool Required { get; set; }
[DefaultValue(0)]
[DescriptionAttribute("Indicates which group of the string to extract in matched regular expression. this is a zero-based index.")]
[DisplayNameAttribute("Group Index")]
public int GroupIndex { get; set; }
public override void Extract(object sender, ExtractionEventArgs e)
{
String errormessage="";
String result = this.Extract(e.Response.BodyString, ref errormessage);
if (!string.IsNullOrEmpty(result))
{
if (this.HtmlDecode)
{
result = HttpUtility.HtmlDecode(result);
}
e.WebTest.Context[this.ContextParameterName] = result;
}
else
{
e.Success = false;
e.Message = errormessage;
}
}
internal String Extract(string document,ref string errormessage)
{
int startat = 0;
int num2 = 0;
RegexOptions options = RegexOptions.Multiline;
if (this.IgnoreCase)
{
options |= RegexOptions.IgnoreCase;
}
Regex regex = new Regex(this.RegularExpression, options);
Match selectedMatch=null;
while (startat < document.Length)
{
Match match = regex.Match(document, startat);
if (!match.Success)
{
break;
}
int num3 = match.Index + match.Length;
if (num2 == this.Index)
{
selectedMatch = match;
}
startat = num3;
num2++;
}
if (selectedMatch == null)
{
errormessage = "Matched string is not found";
return null;
}
if (selectedMatch.Groups.Count - 1 < this.GroupIndex)
{
errormessage = "Matched group is not found";
return null;
}
return selectedMatch.Groups[GroupIndex].Value;
}
}
}
1) 在CustomExtractRegularExpression 的类和属性上,我们用到了DisplayNameAttribute,DescriptionAttribute,DefaultValue这些Attribute,他们的作用是在VS的Add Extraction Rule窗口上配置提取规则时,定义规则的显示名和描述,以及每个属性的显示名,描述和默认值。
2)提取规则通过重载void Extract(object sender, ExtractionEventArgs e) 方法来实现。如果提取成功,把e.Success 设置为true,并且把提取的参数值保存在e.WebTest.Context[this.ContextParameterName]中;否则e.Success设置为false,并在e.Message中填入失败的消息。
3)Custom Extract Regular Expression规则,相对于Extract Regular Expression规则,我们增加了一个Group Index参数,允许用户从特定的正则表达式匹配中,选中匹配的group,关于正则表达式group,可以参考MSDN。
应用自定义规则
现在,我们把规则添加到web performance test中,我们用Custom Extract Regular Expression来替换在(2)中我们使用的Extract Text规则来提取结果中的数值。属性配置如下:

注意,"Group Index”参数应该设置为1
知平软件致力于移动平台自动化测试技术的研究,我们希望通过向社区贡献知识和开源项目,来促进行业和自身的发展。