程序中,最常用的数据类型之一就是整型了。 本篇博文记录的就是研究整型过程中的一些心得。
1 PyLongObject
1.1 版本之别
在python2.x中,整型对象还有两种:不太大的整数int(约等于C语言中long)和大整数long。 在python3之后,这两种类型合并为int,但新的int类型的表现和2.x中的long其实更为接近。
在python2.x中,int是一个定长的类型,并且采用了两个不同的内存池分别存放小整数和大整数; 但在python3之后,int变成了变长对象, 且只有小整数还放在一个内存池中,大整数并未采用此技术。(内存池详解见《python源码剖析》2.2)
在开始后面的内容之前再说明一下: 虽然python3中整型的类型名叫做int,可是它在源码中的名字全都是PyLongXXX之类的, 找不到PyIntXXX是一件正常的事情。
本文涉及文件:
- Include/longobject.h
- Include/longintrepr.h
- Objects/longobject.c
1.2 PyLongObject
表示整型对象的数据结构是PyLongType,定义如下:
/* file:Include/longintrepr.h */ struct _longobject { PyObject_VAR_HEAD /* 展开后为PyVarObject ob_base; */ digit ob_digit[1]; }; /* file:Include/longobject.h */ typedef struct _longobject PyLongObject;
python有两套数的表示法(也就是digit这个类型有两种定义), 一个数用30个二进制位来表示,存储在unsigned int中, 另一个用15个二进制位来表示,存储在unsigned short中, 宏PYLONG_BITS_IN_DIGIT决定了使用哪个表示法(该宏定义在Include/pyport.h中或者在configure时设定)。 在后文中,你会发现关于这两套不同表示的一些处理。
在PyLongObject的定义中,采用了一个digit类型的数组来存储数。 对于那些需要多个digit来存储的数,可以通过数组越界的神奇方法(这里真是蛮拼的) 通过ob_digit来访问,因为在分配内存时会根据数的大小在ob_digit后分配一些空余空间正好用来越界(真的蛮拼的= =)。
一个需要多个digit存储的数是以什么样的顺序存储的呢?请看后文详解。
1.3 类型对象
基础篇说过,每一个内置类型都由一个对应的PyTypeObject类型的变量用来保存这个类型相关的各种信息。 在整型中,这个家伙的定义如下:
/* file: Objects/longobject.c */ PyTypeObject PyLong_Type = { PyVarObject_HEAD_INIT(&PyType_Type, 0) "int", /* tp_name */ offsetof(PyLongObject, ob_digit), /* tp_basicsize */ sizeof(digit), /* tp_itemsize */ long_dealloc, /* tp_dealloc */ 0, /* tp_print */ 0, /* tp_getattr */ 0, /* tp_setattr */ 0, /* tp_reserved */ long_to_decimal_string, /* tp_repr */ &long_as_number, /* tp_as_number */ 0, /* tp_as_sequence */ 0, /* tp_as_mapping */ (hashfunc)long_hash, /* tp_hash */ 0, /* tp_call */ long_to_decimal_string, /* tp_str */ PyObject_GenericGetAttr, /* tp_getattro */ 0, /* tp_setattro */ 0, /* tp_as_buffer */ Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE | Py_TPFLAGS_LONG_SUBCLASS, /* tp_flags */ long_doc, /* tp_doc */ 0, /* tp_traverse */ 0, /* tp_clear */ long_richcompare, /* tp_richcompare */ 0, /* tp_weaklistoffset */ 0, /* tp_iter */ 0, /* tp_iternext */ long_methods, /* tp_methods */ 0, /* tp_members */ long_getset, /* tp_getset */ 0, /* tp_base */ 0, /* tp_dict */ 0, /* tp_descr_get */ 0, /* tp_descr_set */ 0, /* tp_dictoffset */ 0, /* tp_init */ 0, /* tp_alloc */ long_new, /* tp_new */ PyObject_Del, /* tp_free */ };
关于类型对象中的各项的意思在此就略过不提了。
2 整型对象的创建
python中存在多个用来创建整型对象的函数,但它们之间的差异并不大, 因此这里只分析一个典型的例子:PyLong_FromLong。
2.1 小整数对象池
由于整数(特别是小整数)在程序中会被用到的次数太多, 因此如果每次使用整数都去分配内存、使用后再释放内存就会使得效率极其低。 为了提高效率,python对于小整数使用了对象池技术。
python会事先划定固定大小的内存空间用来存储小整数对象, 并且这些小整数对象一旦创建会一直持续到python进程结束才被释放。
这个对象池的定义如下:
/* file:Objects/longobject.c */ static PyLongObject small_ints[NSMALLNEGINTS + NSMALLPOSINTS];
NSMALLNEGINTS和NSMALLPOSINTS规定了小整数的范围, 任意小整数x都满足 -NSMALLNEGINTS ≤ x < NSMALLPOSINTS。
在python解释器启动时,会调用_PyLong_Init()函数进行初始化, 初始化后small_ints数组内的对象都会被初始化,之后使用只需要直接引用即可。
在创建整型对象时,会执行小整数检查:
/* file:Objects/longobject.c */ static PyObject * get_small_int(sdigit ival) { PyObject *v; assert(-NSMALLNEGINTS <= ival && ival < NSMALLPOSINTS); v = (PyObject *)&small_ints[ival + NSMALLNEGINTS]; Py_INCREF(v); /* 该对象引用数增加 */ #ifdef COUNT_ALLOCS if (ival >= 0) quick_int_allocs++; else quick_neg_int_allocs++; #endif return v; } #define CHECK_SMALL_INT(ival) do if (-NSMALLNEGINTS <= ival && ival < NSMALLPOSINTS) { return get_small_int((sdigit)ival); } while(0)
CHECK_SMALL_INT宏都在各种创建整数对象的函数内被使用, 因此不要奇怪出现了return。 若需要创建的数在小整数范围内, 就会调用get_small_int函数从对象池中寻找并返回对应的对象。
2.2 其他整数
相比于小整数,其他整数的创建就麻烦的多了。这里以PyLong_FromLong为例:
1 /* file:Objects/longobject.c */ 2 /* Create a new int object from a C long int */ 3 4 PyObject * 5 PyLong_FromLong(long ival) 6 { 7 PyLongObject *v; 8 unsigned long abs_ival; 9 unsigned long t; /* unsigned so >> doesn't propagate sign bit */ 10 int ndigits = 0; 11 int sign = 1; 12 13 CHECK_SMALL_INT(ival); 14 15 if (ival < 0) { 16 /* negate: can't write this as abs_ival = -ival since that 17 invokes undefined behaviour when ival is LONG_MIN */ 18 abs_ival = 0U-(unsigned long)ival; 19 sign = -1; 20 } 21 else { 22 abs_ival = (unsigned long)ival; 23 } 24 25 /* Fast path for single-digit ints */ 26 if (!(abs_ival >> PyLong_SHIFT)) { 27 v = _PyLong_New(1); 28 if (v) { 29 Py_SIZE(v) = sign; 30 v->ob_digit[0] = Py_SAFE_DOWNCAST( 31 abs_ival, unsigned long, digit); 32 } 33 return (PyObject*)v; 34 } 35 36 #if PyLong_SHIFT==15 37 /* 2 digits */ 38 if (!(abs_ival >> 2*PyLong_SHIFT)) { 39 v = _PyLong_New(2); 40 if (v) { 41 Py_SIZE(v) = 2*sign; 42 v->ob_digit[0] = Py_SAFE_DOWNCAST( 43 abs_ival & PyLong_MASK, unsigned long, digit); 44 v->ob_digit[1] = Py_SAFE_DOWNCAST( 45 abs_ival >> PyLong_SHIFT, unsigned long, digit); 46 } 47 return (PyObject*)v; 48 } 49 #endif 50 51 /* Larger numbers: loop to determine number of digits */ 52 t = abs_ival; 53 while (t) { 54 ++ndigits; 55 t >>= PyLong_SHIFT; 56 } 57 v = _PyLong_New(ndigits); 58 if (v != NULL) { 59 digit *p = v->ob_digit; 60 Py_SIZE(v) = ndigits*sign; 61 t = abs_ival; 62 while (t) { 63 *p++ = Py_SAFE_DOWNCAST( 64 t & PyLong_MASK, unsigned long, digit); 65 t >>= PyLong_SHIFT; 66 } 67 } 68 return (PyObject *)v; 69 } 70 71 PyLongObject * 72 _PyLong_New(Py_ssize_t size) 73 { 74 PyLongObject *result; 75 /* Number of bytes needed is: offsetof(PyLongObject, ob_digit) + 76 sizeof(digit)*size. Previous incarnations of this code used 77 sizeof(PyVarObject) instead of the offsetof, but this risks being 78 incorrect in the presence of padding between the PyVarObject header 79 and the digits. */ 80 if (size > (Py_ssize_t)MAX_LONG_DIGITS) { 81 PyErr_SetString(PyExc_OverflowError, 82 "too many digits in integer"); 83 return NULL; 84 } 85 result = PyObject_MALLOC(offsetof(PyLongObject, ob_digit) + 86 size*sizeof(digit)); 87 if (!result) { 88 PyErr_NoMemory(); 89 return NULL; 90 } 91 return (PyLongObject*)PyObject_INIT_VAR(result, &PyLong_Type, size); 92 }
调用该函数后,先用CHECK_SMALL_INT来检查小整数,这个在前面已经分析过了。
若不是小整数,首先需要求出ival的绝对值(15~23行)。 对于负数,需要注意它求绝对值的方法:用0减而不是直接取反。 这是由于最小的long取反后会导致溢出。以64位long为例, 最小的long是-2^63,最大是2^63 - 1,取反后溢出可能发生神奇的事情。
在代码的第25~33行,是针对一个digit能存储的情况做的优化。 调用_PyLong_New分配内存后,设置v的大小和ob_digit值并返回即可。 用来设置值的Py_SAFE_DOWNCAST是一个宏,它的定义在非DEBUG模式下如下:
#define Py_SAFE_DOWNCAST(VALUE, WIDE, NARROW) (NARROW)(VALUE) /* 其实就是直接进行类型转换进行截断。 * 在DEBUG模式下会有更复杂的表现 */
在36~49行,是针对15位digit、两个digit存储的情况做的优化。 在设置值时,
ob_digit[0]中存放的是后15的值(PyLong_MASK的值是0x7FFF,与abs_ival做按位与得到后15位), ob_digit[1]中存放的自然是前15位了。这里就可以解答上面提出的一个问题了,多个digit保存的情况下,到底是以怎样的顺序存放的呢? 答案就是,对于b位的digit,
ob_digit[n]中存放的是从低位起从零计数的第(n-1)*b到第n*b-1位。在51~68行,是对于其他情况的一个普遍处理方法,这里就不详细分析了。
需要注意的是,size会决定一个数的正负(因为ob_digit存储的都是绝对值后的结果)负数的话是digit数的相反数,0的话是0,正数是digit数。
最后,再分析一下_PyLong_new这个函数。 这个函数中最关键的是计算该对象的大小。这里采用了如下计算方式:
对象大小 = ob_digit偏移量 + size*sizeof(digit)
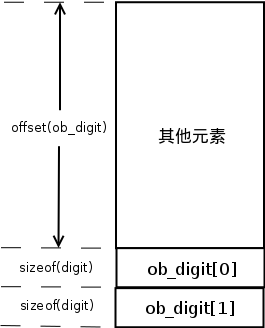
再看看offsetof这个宏:
# define offsetof(type, member) ((size_t)(&((type *)0)->member))
以0为基地址取member的地址再转换成size_t类型就是其偏移。
3 其他操作分析
最后,再看一个典型的操作来看看python是如何处理整型数据的。 这些操作在PyLong_Type的tp_as_number成员中可以看到。
3.1 加法
加法定义如下:
/* file:Objects/longobject.c */ long_add(PyLongObject *a, PyLongObject *b) { PyLongObject *z; CHECK_BINOP(a, b); if (ABS(Py_SIZE(a)) <= 1 && ABS(Py_SIZE(b)) <= 1) { PyObject *result = PyLong_FromLong(MEDIUM_VALUE(a) + MEDIUM_VALUE(b)); return result; } if (Py_SIZE(a) < 0) { if (Py_SIZE(b) < 0) { z = x_add(a, b); if (z != NULL && Py_SIZE(z) != 0) Py_SIZE(z) = -(Py_SIZE(z)); } else z = x_sub(b, a); } else { if (Py_SIZE(b) < 0) z = x_sub(a, b); else z = x_add(a, b); } return (PyObject *)z; }
python中的整型是不可变对象,因此每一次运算都会产生新的整型对象。 看到这里我们会自然的产生疑问,如果在python里重复计算两个非小整数相加, 会不会一直产生新的对象呢?还是会引用到原先的对象呢? 从目前分析过的代码中,我们可以猜测是会产生新的对象;后文会给出验证方法。
在上面的函数中,主要工作就是对size进行判断并调用对应的函数; 因此更核心的功能在x_add和x_sub中。这里只分析x_add:
1 /* file:Objects/longobject.c */ 2 static PyLongObject * 3 x_add(PyLongObject *a, PyLongObject *b) 4 { 5 Py_ssize_t size_a = ABS(Py_SIZE(a)), size_b = ABS(Py_SIZE(b)); 6 PyLongObject *z; 7 Py_ssize_t i; 8 digit carry = 0; 9 10 /* Ensure a is the larger of the two: */ 11 if (size_a < size_b) { 12 { PyLongObject *temp = a; a = b; b = temp; } 13 { Py_ssize_t size_temp = size_a; 14 size_a = size_b; 15 size_b = size_temp; } 16 } 17 z = _PyLong_New(size_a+1); 18 if (z == NULL) 19 return NULL; 20 for (i = 0; i < size_b; ++i) { 21 carry += a->ob_digit[i] + b->ob_digit[i]; 22 z->ob_digit[i] = carry & PyLong_MASK; 23 carry >>= PyLong_SHIFT; 24 } 25 for (; i < size_a; ++i) { 26 carry += a->ob_digit[i]; 27 z->ob_digit[i] = carry & PyLong_MASK; 28 carry >>= PyLong_SHIFT; 29 } 30 z->ob_digit[i] = carry; 31 return long_normalize(z); 32 }
首先,确保a是size较大的一个(10~15行)。
之后,为新的对象分配size_a+1的空间。
然后,对于ob_digit中每一个元素分别相加,所得结果与PyLong_MASK按位与再存入新对象对应ob_digit中, 之后carry右移。这样可以保证超出的部分不会丢失。 进行完所有加法后,把carry放在新对象的对高ob_digit中以防丢失运算中溢出的结果。 最后调用long_normalize消除前导零(防止size暴涨狂吃内存)。
4 Hack it
这里我们主要打print的主意。 在python2.x中,print语句调用的是类型中的tp_print成员对应的函数; 可是python3之后删除了print语句,print成了内建函数,这样就变的稍微麻烦了一点。
查官网手册可知,print函数会调用str函数,str函数对应类型中的tp_str。 因此,我们需要更改一下tp_str的内容。
改动之前,发现tp_repr和tp_str的内容一样。 由于tp_repr在python编译中起到了很重要的作用,因此最好把它和tp_str分开。
把tp_str对应的函数long_to_decimal_string复制粘贴并改个名字(比如my_long_to_decimal_string), 再把该函数内调用的long_to_decimal_string_internal复制粘贴改名字,再把PyLong_Type对应的tp_str改了, 就可以放心的下手啦。
PyTypeObject PyLong_Type = { /* ... */ long_to_decimal_string, /* tp_repr */ /* ... */ my_long_to_decimal_string, /* tp_str */ /* ... */ }
之后就是修改代码了。在long_to_decimal_string_internal中,进行输出的部分是其中的WRITE_DIGITS宏, 这个宏会写入内容到之后打印的字符串内,而我们需要做的就是修改这个宏。除此之外,还需要修改以下和字符串长度相关的部分。
1 /* file:Objects/longobject.c */ 2 long_to_decimal_string_internal(PyObject *aa, 3 PyObject **p_output, 4 _PyUnicodeWriter *writer) 5 { 6 PyLongObject *scratch, *a; 7 PyObject *str; 8 Py_ssize_t size, strlen, size_a, i, j; 9 digit *pout, *pin, rem, tenpow; 10 int negative; 11 enum PyUnicode_Kind kind; 12 13 a = (PyLongObject *)aa; 14 if (a == NULL || !PyLong_Check(a)) { 15 PyErr_BadInternalCall(); 16 return -1; 17 } 18 size_a = ABS(Py_SIZE(a)); 19 negative = Py_SIZE(a) < 0; 20 21 /* quick and dirty upper bound for the number of digits 22 required to express a in base _PyLong_DECIMAL_BASE: 23 24 #digits = 1 + floor(log2(a) / log2(_PyLong_DECIMAL_BASE)) 25 26 But log2(a) < size_a * PyLong_SHIFT, and 27 log2(_PyLong_DECIMAL_BASE) = log2(10) * _PyLong_DECIMAL_SHIFT 28 > 3 * _PyLong_DECIMAL_SHIFT 29 */ 30 if (size_a > PY_SSIZE_T_MAX / PyLong_SHIFT) { 31 PyErr_SetString(PyExc_OverflowError, 32 "int too large to format"); 33 return -1; 34 } 35 /* the expression size_a * PyLong_SHIFT is now safe from overflow */ 36 size = 1 + size_a * PyLong_SHIFT / (3 * _PyLong_DECIMAL_SHIFT); 37 scratch = _PyLong_New(size); 38 if (scratch == NULL) 39 return -1; 40 41 /* convert array of base _PyLong_BASE digits in pin to an array of 42 base _PyLong_DECIMAL_BASE digits in pout, following Knuth (TAOCP, 43 Volume 2 (3rd edn), section 4.4, Method 1b). */ 44 pin = a->ob_digit; 45 pout = scratch->ob_digit; 46 size = 0; 47 for (i = size_a; --i >= 0; ) { 48 digit hi = pin[i]; 49 for (j = 0; j < size; j++) { 50 twodigits z = (twodigits)pout[j] << PyLong_SHIFT | hi; 51 hi = (digit)(z / _PyLong_DECIMAL_BASE); 52 pout[j] = (digit)(z - (twodigits)hi * 53 _PyLong_DECIMAL_BASE); 54 } 55 while (hi) { 56 pout[size++] = hi % _PyLong_DECIMAL_BASE; 57 hi /= _PyLong_DECIMAL_BASE; 58 } 59 /* check for keyboard interrupt */ 60 SIGCHECK({ 61 Py_DECREF(scratch); 62 return -1; 63 }); 64 } 65 /* pout should have at least one digit, so that the case when a = 0 66 works correctly */ 67 if (size == 0) 68 pout[size++] = 0; 69 70 /* calculate exact length of output string, and allocate */ 71 strlen = negative + 1 + (size - 1) * _PyLong_DECIMAL_SHIFT; 72 tenpow = 10; 73 rem = pout[size-1]; 74 while (rem >= tenpow) { 75 tenpow *= 10; 76 strlen++; 77 } 78 if (writer) { 79 if (_PyUnicodeWriter_Prepare(writer, strlen, '9') == -1) { 80 Py_DECREF(scratch); 81 return -1; 82 } 83 kind = writer->kind; 84 str = NULL; 85 } 86 else { 87 str = PyUnicode_New(strlen, '9'); 88 if (str == NULL) { 89 Py_DECREF(scratch); 90 return -1; 91 } 92 kind = PyUnicode_KIND(str); 93 } 94 95 #define WRITE_DIGITS(TYPE) 96 do { 97 if (writer) 98 p = (TYPE*)PyUnicode_DATA(writer->buffer) + writer->pos + strlen; 99 else 100 p = (TYPE*)PyUnicode_DATA(str) + strlen; 101 102 /* pout[0] through pout[size-2] contribute exactly 103 _PyLong_DECIMAL_SHIFT digits each */ 104 for (i=0; i < size - 1; i++) { 105 rem = pout[i]; 106 for (j = 0; j < _PyLong_DECIMAL_SHIFT; j++) { 107 *--p = '0' + rem % 10; 108 rem /= 10; 109 } 110 } 111 /* pout[size-1]: always produce at least one decimal digit */ 112 rem = pout[i]; 113 do { 114 *--p = '0' + rem % 10; 115 rem /= 10; 116 } while (rem != 0); 117 118 /* and sign */ 119 if (negative) 120 *--p = '-'; 121 122 /* check we've counted correctly */ 123 if (writer) 124 assert(p == ((TYPE*)PyUnicode_DATA(writer->buffer) + writer->pos)); 125 else 126 assert(p == (TYPE*)PyUnicode_DATA(str)); 127 } while (0) 128 129 /* fill the string right-to-left */ 130 if (kind == PyUnicode_1BYTE_KIND) { 131 Py_UCS1 *p; 132 WRITE_DIGITS(Py_UCS1); 133 } 134 else if (kind == PyUnicode_2BYTE_KIND) { 135 Py_UCS2 *p; 136 WRITE_DIGITS(Py_UCS2); 137 } 138 else { 139 Py_UCS4 *p; 140 assert (kind == PyUnicode_4BYTE_KIND); 141 WRITE_DIGITS(Py_UCS4); 142 } 143 #undef WRITE_DIGITS 144 145 Py_DECREF(scratch); 146 if (writer) { 147 writer->pos += strlen; 148 } 149 else { 150 assert(_PyUnicode_CheckConsistency(str, 1)); 151 *p_output = (PyObject *)str; 152 } 153 return 0; 154 }
上面的代码中,strlen这个变量表示了字符串的长度。
为了验证打印的对象是否是同一个,我们用一个静态变量保存上一次要打印的结果。 若是同一个对象,则打印出YES并换行;若不是同一个对象也打印NO并换行。 这样的改法最多会增加4个长度,因此给strlen+4。
在WRITE_DIGITS宏内会倒序排列要输出的内容,因此我们也得倒着加要打印的东西。 在121行后面加入下列代码:
*--p = ' '; if(pre == aa) { *--p = 'S'; *--p = 'E'; *--p = 'Y'; } else { *--p = ' '; *--p = 'O'; *--p = 'N'; }
编译python并运行,测试一下print函数:
>>> print(1) NO 1 >>> print(1) YES 1 >>> print(400 + 300) NO 700 >>> print(400 + 300) NO 700 >>> print(700) NO 700 >>> print(700) YES 700 >>> a = 600 + 900 >>> b = 600 + 900 >>> print(a) NO 1500
>>> print(a) YES 1500
>>> print(b)
NO
1500
>>> print(600 + 900)
NO
1500
运行结果确实如猜想那样,每次加都会产生值一样的全新对象。
最后放上更改后的long_to_decimal_string系列函数:
1 static int 2 my_long_to_decimal_string_internal(PyObject *aa, 3 PyObject **p_output, 4 _PyUnicodeWriter *writer) 5 { 6 PyLongObject *scratch, *a; 7 PyObject *str; 8 Py_ssize_t size, strlen, size_a, i, j, tmp; 9 digit *pout, *pin, rem, tenpow; 10 int negative; 11 enum PyUnicode_Kind kind; 12 static PyObject *pre = NULL; 13 14 a = (PyLongObject *)aa; 15 if (a == NULL || !PyLong_Check(a)) { 16 PyErr_BadInternalCall(); 17 return -1; 18 } 19 size_a = ABS(Py_SIZE(a)); 20 negative = Py_SIZE(a) < 0; 21 22 /* quick and dirty upper bound for the number of digits 23 required to express a in base _PyLong_DECIMAL_BASE: 24 25 #digits = 1 + floor(log2(a) / log2(_PyLong_DECIMAL_BASE)) 26 27 But log2(a) < size_a * PyLong_SHIFT, and 28 log2(_PyLong_DECIMAL_BASE) = log2(10) * _PyLong_DECIMAL_SHIFT 29 > 3 * _PyLong_DECIMAL_SHIFT 30 */ 31 if (size_a > PY_SSIZE_T_MAX / PyLong_SHIFT) { 32 PyErr_SetString(PyExc_OverflowError, 33 "int too large to format"); 34 return -1; 35 } 36 /* the expression size_a * PyLong_SHIFT is now safe from overflow */ 37 size = 1 + size_a * PyLong_SHIFT / (3 * _PyLong_DECIMAL_SHIFT); 38 scratch = _PyLong_New(size); 39 if (scratch == NULL) 40 return -1; 41 42 /* convert array of base _PyLong_BASE digits in pin to an array of 43 base _PyLong_DECIMAL_BASE digits in pout, following Knuth (TAOCP, 44 Volume 2 (3rd edn), section 4.4, Method 1b). */ 45 pin = a->ob_digit; 46 pout = scratch->ob_digit; 47 size = 0; 48 for (i = size_a; --i >= 0; ) { 49 digit hi = pin[i]; 50 for (j = 0; j < size; j++) { 51 twodigits z = (twodigits)pout[j] << PyLong_SHIFT | hi; 52 hi = (digit)(z / _PyLong_DECIMAL_BASE); 53 pout[j] = (digit)(z - (twodigits)hi * 54 _PyLong_DECIMAL_BASE); 55 } 56 while (hi) { 57 pout[size++] = hi % _PyLong_DECIMAL_BASE; 58 hi /= _PyLong_DECIMAL_BASE; 59 } 60 /* check for keyboard interrupt */ 61 SIGCHECK({ 62 Py_DECREF(scratch); 63 return -1; 64 }); 65 } 66 /* pout should have at least one digit, so that the case when a = 0 67 works correctly */ 68 if (size == 0) 69 pout[size++] = 0; 70 71 /* calculate exact length of output string, and allocate */ 72 strlen = negative + 1 + (size - 1) * _PyLong_DECIMAL_SHIFT + 4; 73 tenpow = 10; 74 rem = pout[size-1]; 75 while (rem >= tenpow) { 76 tenpow *= 10; 77 strlen++; 78 } 79 if (writer) { 80 if (_PyUnicodeWriter_Prepare(writer, strlen, '9') == -1) { 81 Py_DECREF(scratch); 82 return -1; 83 } 84 kind = writer->kind; 85 str = NULL; 86 } 87 else { 88 str = PyUnicode_New(strlen, '9'); 89 if (str == NULL) { 90 Py_DECREF(scratch); 91 return -1; 92 } 93 kind = PyUnicode_KIND(str); 94 } 95 tmp = Py_SIZE(a); 96 97 #define WRITE_DIGITS(TYPE) 98 do { 99 if (writer) 100 p = (TYPE*)PyUnicode_DATA(writer->buffer) + writer->pos + strlen; 101 else 102 p = (TYPE*)PyUnicode_DATA(str) + strlen; 103 104 /* pout[0] through pout[size-2] contribute exactly 105 _PyLong_DECIMAL_SHIFT digits each */ 106 for (i=0; i < size - 1; i++) { 107 rem = pout[i]; 108 for (j = 0; j < _PyLong_DECIMAL_SHIFT; j++) { 109 *--p = '0' + rem % 10; 110 rem /= 10; 111 } 112 } 113 /* pout[size-1]: always produce at least one decimal digit */ 114 rem = pout[i]; 115 do { 116 *--p = '0' + rem % 10; 117 rem /= 10; 118 } while (rem != 0); 119 120 /* and sign */ 121 if (negative) 122 *--p = '-'; 123 *--p = ' '; 124 if(pre == aa) 125 { 126 *--p = 'S'; 127 *--p = 'E'; 128 *--p = 'Y'; 129 } 130 else 131 { 132 *--p = ' '; 133 *--p = 'O'; 134 *--p = 'N'; 135 } 136 137 /* check we've counted correctly */ 138 if (writer) 139 assert(p == ((TYPE*)PyUnicode_DATA(writer->buffer) + writer->pos)); 140 else 141 assert(p == (TYPE*)PyUnicode_DATA(str)); 142 } while (0) 143 144 /* fill the string right-to-left */ 145 if (kind == PyUnicode_1BYTE_KIND) { 146 Py_UCS1 *p; 147 WRITE_DIGITS(Py_UCS1); 148 } 149 else if (kind == PyUnicode_2BYTE_KIND) { 150 Py_UCS2 *p; 151 WRITE_DIGITS(Py_UCS2); 152 } 153 else { 154 Py_UCS4 *p; 155 assert (kind == PyUnicode_4BYTE_KIND); 156 WRITE_DIGITS(Py_UCS4); 157 } 158 #undef WRITE_DIGITS 159 160 Py_DECREF(scratch); 161 if (writer) { 162 writer->pos += strlen; 163 } 164 else { 165 assert(_PyUnicode_CheckConsistency(str, 1)); 166 *p_output = (PyObject *)str; 167 } 168 pre = aa; 169 return 0; 170 } 171 172 static PyObject * 173 my_long_to_decimal_string(PyObject *aa) 174 { 175 PyObject *v; 176 if (my_long_to_decimal_string_internal(aa, &v, NULL) == -1) 177 return NULL; 178 return v; 179 }