死锁的类型
- 不同表之间的相互等待,第一个事务操作A->B, 第二个事务操作B->A - 每个事务都锁定对方下一步将要操作的表
- 同一张表之间的相互等待, 无索引导致的全表扫描,下文中说到的情况 - 每个事务都锁定满足条件的记录,同时继续扫描直到完成一次全表扫描
SQL Server锁机制详解
http://www.cnblogs.com/freeton/articles/3819934.html
http://blog.itpub.net/13651903/viewspace-1091664/
[转]初步了解更新锁(U)与排它锁(X)
转载至:http://blog.csdn.net/zjcxc/article/details/27351779
一直没有认真了解UPDATE操作的锁,最近在MSDN论坛上看到一个问题,询问堆表更新的死锁问题,问题很简单,有类似这样的表及数据:
CREATE TABLE dbo.tb(
c1 int,
c2 char(10),
c3 varchar(10)
);
Go
DECLARE @id int;
SET @id = 0;
WHILE @id <5
BEGIN;
SET @id = @id + 1;
INSERT dbo.tb VALUES( @id, 'b' + RIGHT(10000 + @id, 4), 'c' + RIGHT(100000 + @id, 4) );
END;
在查询一中执行更新操作:
BEGIN TRAN
UPDATE dbo.tb SET c2 = 'xx' WHERE c1 = 2;
WAITFOR DELAY '00:00:30';
UPDATE dbo.tb SET c2 = 'xx' WHERE c1 = 5;
ROLLBACK;
在查询一执行开始后,马上在查询二中执行下面的操作
BEGIN TRAN
UPDATE dbo.tb SET c2 = 'xx' WHERE c1 = 1;
ROLLBACK;
为什么会出现死锁,如果条件改为 c1 = 4 则不会死锁。
开始的时候想得比较简单,死锁的表现是形成循环等待(对于两个查询而言,可以简单地认为就是在相互等待对方锁定资源的释放)。
对于这个例子而言,第一个查询更新两次,会先更新并锁定一条记录,然后等待第二个更新;但第二个查询只会更新一条记录,它要么与第一个查询冲突,无法获得锁,需要等待查询一完成,这个时候它并没有锁定什么;要么能够获得锁,完成更新。似乎不应该会出现死锁,死锁会不会是其他原因导致。
在自己的电脑上简单测试了一下,似乎也确实没有死锁。
但后面通过Profile跟踪更新操作的下锁情况才发现,自己的分析大错特错了。主要原因在于没有正确理解更新操作是如何用锁的。
在联机帮助上“锁模式”中有关于更新的U(更新锁)和X(排它锁)的说明
http://msdn.microsoft.com/zh-cn/library/ms175519(v=sql.105).aspx
不过说得确实挺模糊的,里面还提到了S锁,我一直以为是查询数据过程中用的S锁(也 SELECT 一样),找到满足条件的记录后用U锁,再转换为X锁做更新。
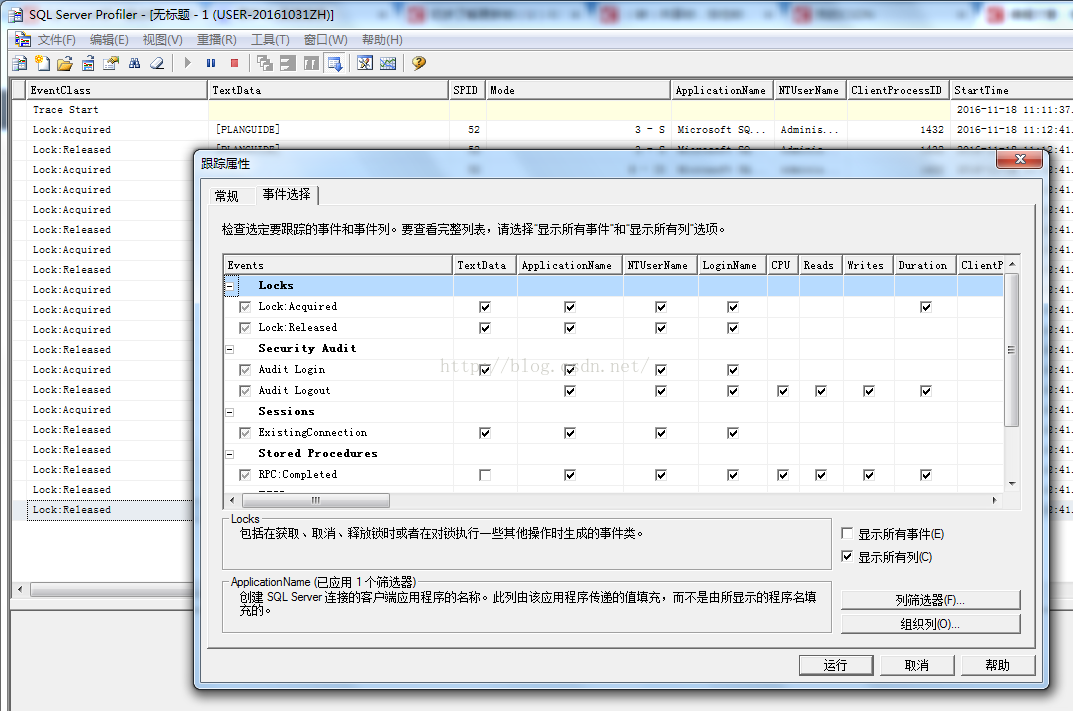
SQL Server Profiler(事件探查器)跟踪的结果让我知道了这是一个错误的理解,在SQL Server Profiler中新建一个跟踪,选择Locks中的Lock:Acquired (加锁),Lock:Acquired(释放锁)解两个事件,在筛选中设置只跟踪测试用的查询窗口对应的spid(可以执行 PRINT @@SPID 获得),然后执行一个更新语句,比如 UPDATE dbo.tb SET c2 = 'xx' WHERE c1 = 3
在Profile中可以看到,对于每条记录都有加 U 锁的操作,对于不满足条件的记录,会马上释放U锁;对于满足条件的记录,最终转换为X锁。如下图所示。

注意一下,在这个跟踪结果里面,并没有出现S锁。
另外学做了一些测试:
- 通过加大记录量做更新测试,会发现数据扫描涉及的记录都有U锁,并不限于更新记录所在的页。这从另一个角度说明了大表中Scan 可怕。
- 当使用索引Scan的时候,也会通过跟踪发现所Scan的索引资源有U锁,如果更新不涉及索引变化,那以只会对应的记录有U转X锁,索引的U锁会释放;如果影响索引,那么索引的U锁会转X锁。
- 删除操作与更新操作类似
- 使用
UPDATE aSET c2 = 'xx' FROM dbo.tb AS a WITH(NOLOCK) WHERE c1 = 3的加锁情况是一样的, 并不会因为NOLOCK的提示而不加 U 或者 X 锁
最后回头研究一下示例中的死锁问题:
- 对于查询一,第一个更新依次扫描表中所有记录,对于每条记录,加 U 锁,判断是否符合更新条件,如果符合,转换为 X 锁;如果不符合条件,释放 U 锁。第一个更新完成的时候,查询一锁定了一条记录(由于事务未完成,所以锁一直保持),然后等待第二个更新
- 对于查询二,依次扫描表中的每条记录(与前面的更新一样),如果它更新的记录在查询一更新的记录前被扫描到,那么这条记录也会变成 X 锁;当继续并进行到查询一的X锁记录的零点,U 与 X 冲突,无法继续,这时候查询二等待查询一释放锁
- 查询一的第二个更新开始执行,依次扫描每条记录,同一个事务内不会有冲突,所以它不会与自己之前锁定的记录有冲突,但进行到查询二锁定的记录的时候,它也无法获得 U 锁,它需要等待查询二释放资源。这个时候就形成了相互等待,符合死锁条件
- 如果查询二需要更新的记录在查询一的第一个更新记录之后,则不会有死锁,因为查询二在扫描到查询一第一个更新的记录时就会因为锁冲突等待了,这个时候它没有对任何记录设置与查询一的操作有冲突的锁。我自己测试的时候没有死锁,就是这种情况。
注意这里面提到的顺序,是数据读取的顺序,不一定与存储顺序一样,磁盘上记录的顺序也不一定与INSERT的记录顺序一样,这也是我用同样条件没有测试出死锁的原因(我的环境中,恰好读出的顺序与INSERT的顺序不一样)
更新时,记录读取的顺序,可以通过Profile跟踪的Lock:Acquired (加锁)事件来看,涉及大量数据时,如果服务器支持,还会有并发读取。这也是分析死锁时要考虑的因素