之前在 Solr6.5在Centos6上的安装与配置 (一) 一文中介绍了solr6.5的安装。这篇文章主要介绍创建Solr的Core并配置中文IKAnalyzer分词和拼音检索。
一、创建Core:
1、首先在solrhome(solrhome的路径和配置见Solr6.5在Centos6上的安装与配置 (一)中solr的web.xml)中创建mycore目录;
[root@localhost down]# [root@localhost down]# mkdir /down/apache-tomcat-8.5.12/solrhome/mycore [root@localhost down]# cd /down/apache-tomcat-8.5.12/solrhome/mycore
[root@localhost mycore]#
2、复制solr-6.5.0exampleexample-DIHsolrsolr下的所有文件到/down/apache-tomcat-8.5.12/solrhome/mycore目录下:
[root@localhost mycore]# cp -R /down/solr-6.5.0/example/example-DIH/solr/solr/* ./ [root@localhost mycore]# ls conf core.properties [root@localhost mycore]#
3、重新启动tomcat;
[root@localhost down]# /down/apache-tomcat-8.5.12/bin/shutdown.sh [root@localhost down]# /down/apache-tomcat-8.5.12/bin/startup.sh
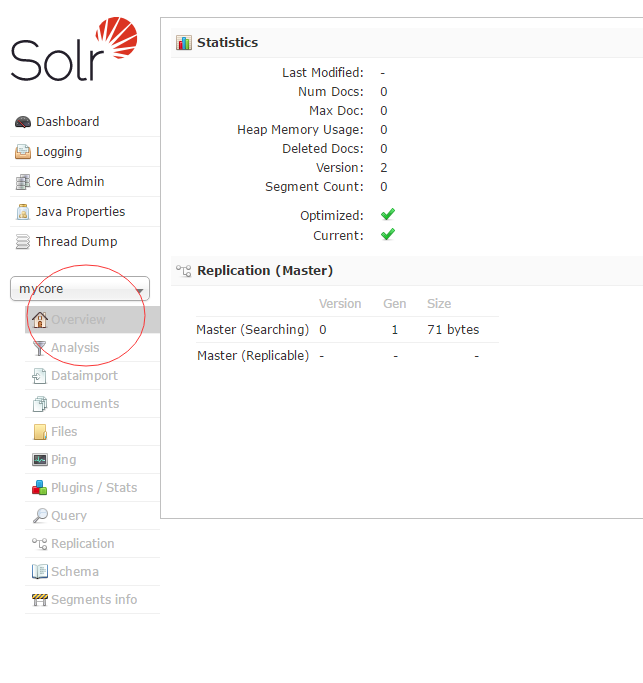
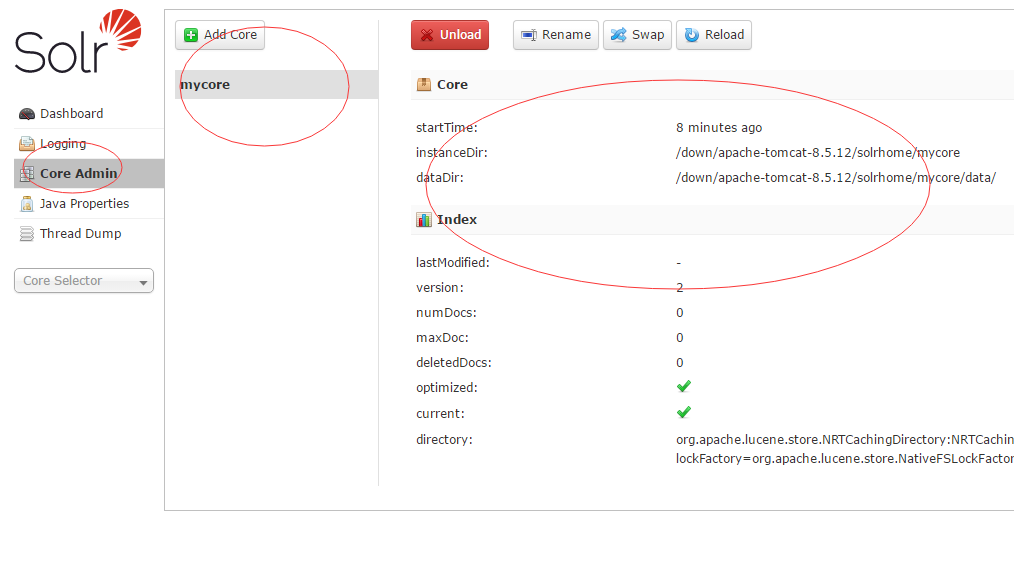
4、此时在浏览器输入http://localhost:8080/solr/index.html即可出现Solr的管理界面,即可看到我们刚才的mycore
二、配置solr自带的中文分词(和IK的区别是不能自己添加词库):
1、配置solr6.5自带中文分词。复制solr-6.5.0/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-6.5.0.jar到apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/目录下。
[root@localhost down]# cp /down/solr-6.5.0/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-6.5.0.jar /down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/
2、为core添加对中文分词的支持。编辑mycore下conf下的managed-schema文件.
[root@localhost conf]# cd /down/apache-tomcat-8.5.12/solrhome/mycore/conf [root@localhost conf]# vi managed-schema
在文件的</schema>前添加
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> </fieldType>
重启tomcat,后在浏览器输入http://localhost:8080/solr/index.html#/mycore/analysis
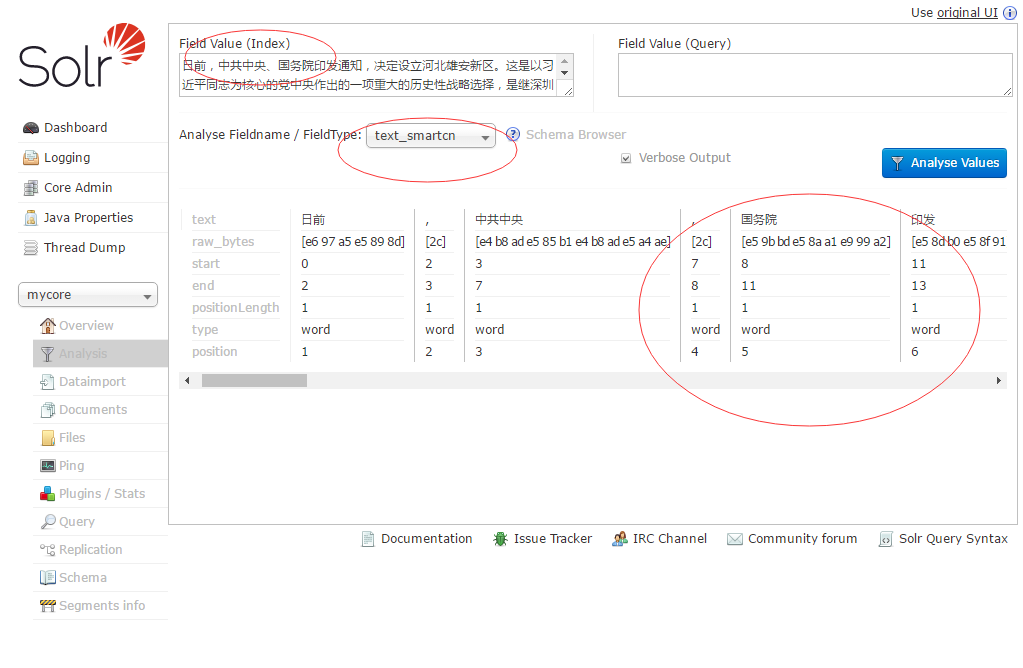
在Field Value (Index)文本框输入一些中文,然后Analyse Fieldname / FieldType:选择text_smartcn查看中文分词的效果。
如图:
三、配置IKAnalyzer的中文分词:
1、首先下载IKAnalyzer 这是最新的支持solr6.5.
解压后会有四个文件。
[root@localhost ikanalyzer-solr5]# ls ext.dic IKAnalyzer.cfg.xml solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar stopword.dic
ext.dic为扩展字典,stopword.dic为停止词字典,IKAnalyzer.cfg.xml为配置文件,solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar为分词jar包。
2、将文件夹下的IKAnalyzer.cfg.xml , ext.dic和stopword.dic 三个文件 复制到/webapps/solr/WEB-INF/classes 目录下,并修改IKAnalyzer.cfg.xml
[root@localhost ikanalyzer-solr5]# cp ext.dic IKAnalyzer.cfg.xml stopword.dic /down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/classes/
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">ext.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">stopword.dic;</entry> </properties>
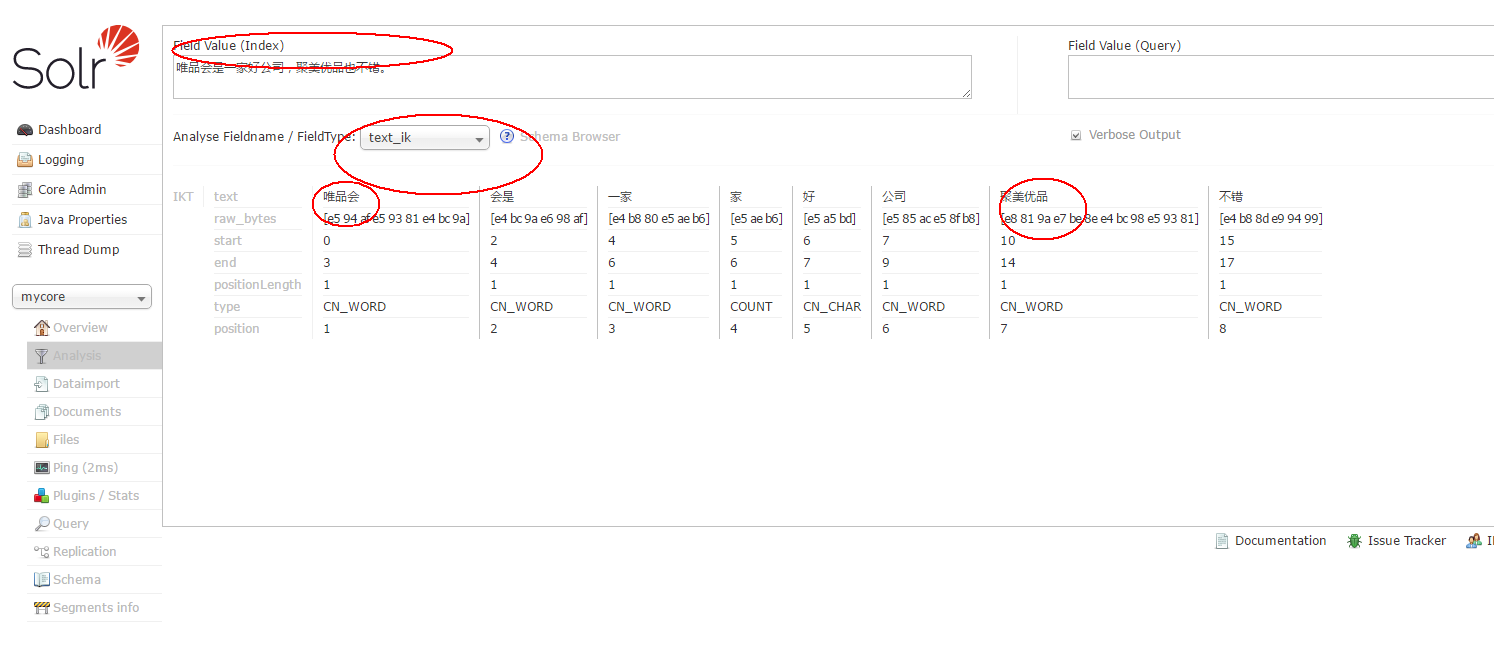
3、在ext.dic 里增加自己的扩展词典,例如,唯品会 聚美优品
4、复制solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar到/down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/目录下。
[root@localhost down]# cp /down/ikanalyzer-solr5/solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar /down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/
5、在 solrhomemycoreconfmanaged-schema 文件</schema>前增加如下配置
<!-- 我添加的IK分词 --> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/> </analyzer> </fieldType>
注意: 记得将stopword.dic,ext.dic的编码方式为UTF-8 无BOM的编码方式。
重启tomcat查看分词效果。
四、配置拼音检索:
1、前期准备,需要用到pinyin4j-2.5.0.jar、pinyinAnalyzer.jar这两个jar包,下载地址。
2、将pinyin4j-2.5.0.jar、pinyinAnalyzer.jar这两个jar包复制到/down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/目录下。
[root@localhost down]# cp pinyin4j-2.5.0.jar pinyinAnalyzer4.3.1.jar /down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/
3、在 solrhomemycoreconfmanaged-schema 文件</schema>前增加如下配置:
<fieldType name="text_pinyin" class="solr.TextField" positionIncrementGap="0"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/> <filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" /> <filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" /> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/> <filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" /> <filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" /> </analyzer> </fieldType>
重启tomcat查看拼音检索效果。
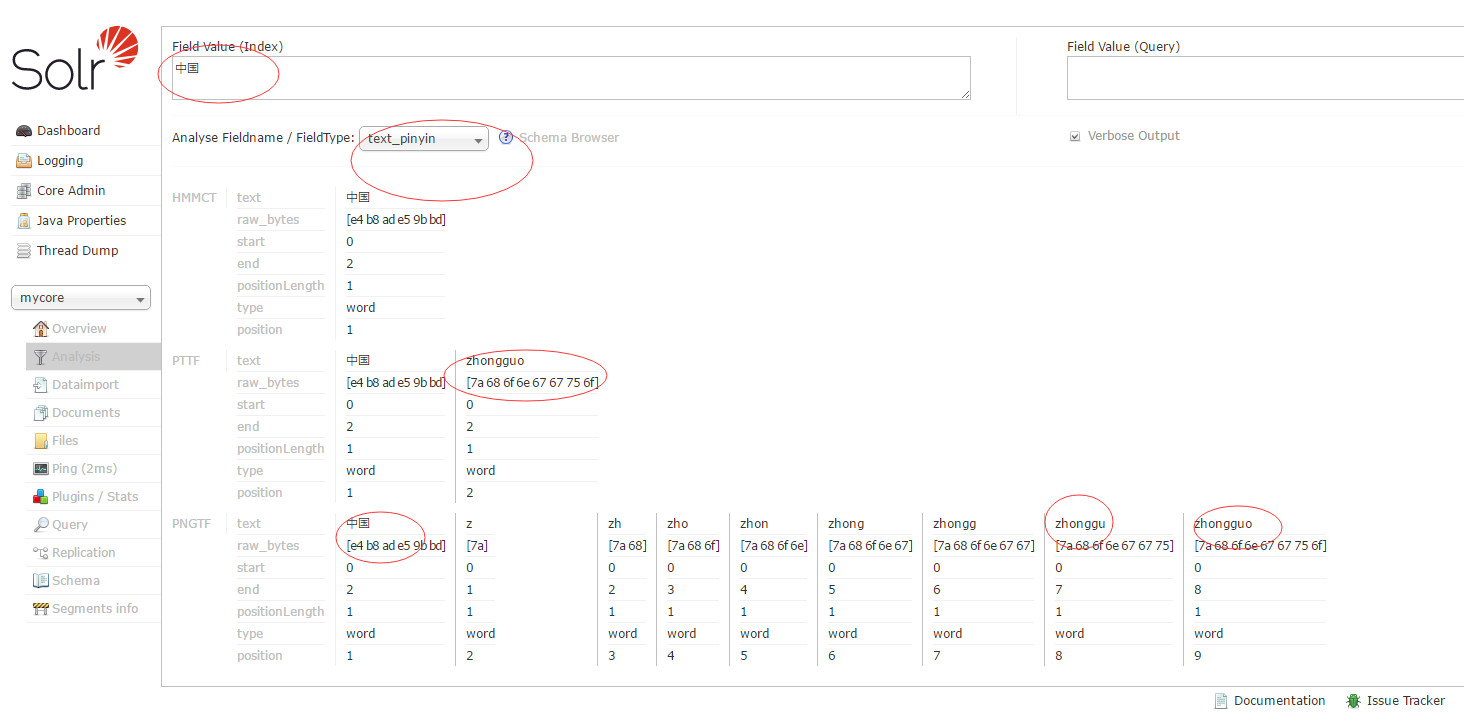
这里用的是solr自带的中文分词加上pinyin4j来实现的。
相关文件的下载地址:
所有要用到的文件:solr6.5ik-pinyin.zip