前言
很抱歉 好久没有更新文章了,最近的一篇原创还是在去年十月份,这个号确实荒废了好久,感激那些没有把我取消关注的小伙伴。
有读者朋友经常私信问我: ”你号卖了?“ ”文章咋不更新了?“
不更新主要的原因就是自己太懒了,也不知道要写些什么东西。最近一年还是在零散的学些东西,每次准备提笔写文章都半途而废了,到了最后就干脆不写了。
废话不多说了,还是看文章吧,分享的内容是我自己思考的一些东西,并没有标准答案,希望大家看的时候都能够有自己的见解,有问题可以第一时间联系到我 一起探讨。
跟着我,要么学会,要么学废!
要学废什么?
本文只想唠唠EurekaServer中关于读写锁的一些使用小技巧。
对于我们正常逻辑思维来说,读锁就是在读的时候加锁,写锁就是在写的时候加锁,这似乎没有什么技巧?

好像什么也学不废了?Oh No ~~~ 读写锁只是通俗的叫法,为何限定读锁只能加在读操作,写锁只能加在写操作呢?
细细品下方面那句话,接下来一起看看网飞的程序员是怎么玩的吧。
读写锁回顾
JDK中常说的读写锁是ReentrantReadWriteLock,我们平时工作中使用ReentrantLock会多一些,这两把锁都是师出同门,它们都是实现了AbstractQueuedSynchronizer中的相关逻辑
ReentrantLock将AQS中的state变量“按位切割”切分成了两个部分,高16位表示读锁状态(读锁个数),低16位表示写锁状态(写锁个数)。如下图所示:

大家也可以看下我之前写过的一篇详解AQS的文章:我画了35张图就是为了让你深入 AQS
这里就不再赘述读写锁底层的实现原理了,原理都在上面文章中。我们在这里可以把读写锁理解为和ReentrantLock一样的锁,只是带了读写操作的区分。
读与读之间不互斥,读与写、写与写之间是互斥的,这样做的目的是能够提升读写操作的性能。比如我们的业务是读多写少,那么使用读写锁,大多数情况都是可以并发访问的,不需要通过每次加锁来影响系统性能。
EurekaServer如何玩读写锁的?
前面铺垫了很多,希望大家能够知道读写锁这个东西。读写锁的使用很简单,JDK中都有现成的API供我们调用。往往一些牛叉的框架也都是使用这些JDK底层的API 构建起来的,接着我们就看EurekaServer是如何玩的吧。
PS:对于SpringCloud底层源码感兴趣的可以看我之前写的一套源码解读博客:https://www.cnblogs.com/wang-meng/p/12147889.html (密码:222 不要告诉别人哟o( ̄▽ ̄)d)
EurekaServer为何需要加锁?
我们知道EurekaServer作为一个注册中心,里面是保存EurekaClient注册表信息的,为了能够感知其他注册实例的存在,每个EurekaClient都会定时去注册中心拉取增量的注册表信息,然而这个增量拉取很有门道的,在增量获取的时候必须要加写锁来保证获取的数据准确性,这里先不详细展开,后续会一点点讲解
我们先看几个常见场景:
-
服务A启动的时候需要向注册中心发送regist请求,注册表会将服务A写入自己的花名册中 -
服务B发送下线请求,告知注册中心 我要下线了,请把我从注册表中请求,此时注册表会把服务B从花名册中抹掉 -
服务C在运行过程中也需要定时拉取注册表的最新数据,然后将数据同步到本地,这样本地就可以通过服务名去发现其他服务了
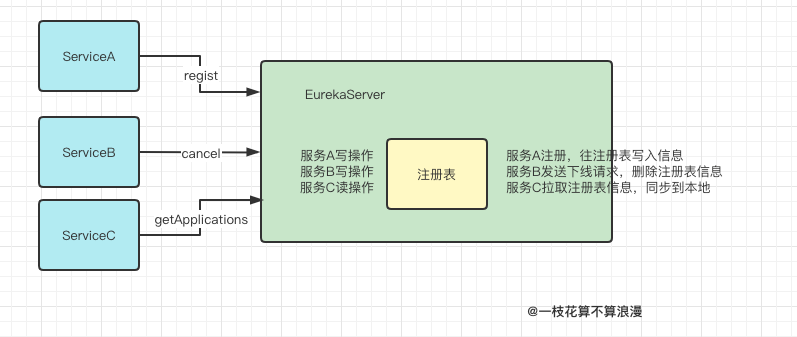
这里加读写锁的玄机就藏在ServiceC获取注册表增量信息里面,我们先看EurekaServer读写锁中的相关代码:
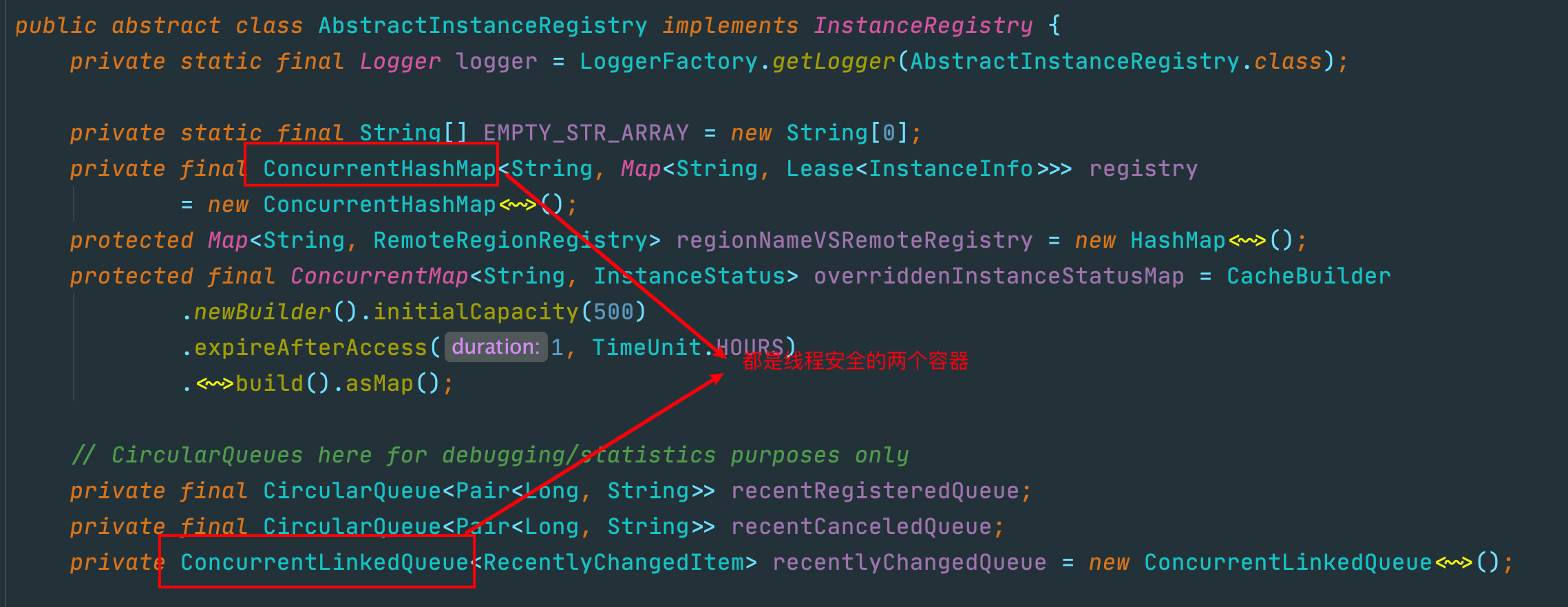
public abstract class AbstractInstanceRegistry implements InstanceRegistry {
private static final Logger logger = LoggerFactory.getLogger(AbstractInstanceRegistry.class);
// registry就是注册表,存储注册信息的集合
private final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry
= new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>();
// 存放最近修改的实例信息
private ConcurrentLinkedQueue<RecentlyChangedItem> recentlyChangedQueue = new ConcurrentLinkedQueue<RecentlyChangedItem>();
// 今天的主角,读写锁
private final ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private final Lock read = readWriteLock.readLock();
private final Lock write = readWriteLock.writeLock();
}
上面有三个关键的地方需要注意:
注册表:
ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry
最近修改的实例信息队列:
ConcurrentLinkedQueue<RecentlyChangedItem> recentlyChangedQueue
读写锁:
ReentranteadWriteLock readWriteLock
EurekaServer读写锁使用场景?
上面交代了大致背景,接下来就看看读写锁在这里是如何使用的。我们先来梳理下读写锁在这里使用的几个场景:

接着也看下代码中readLock和writeLock 的使用链条,这里说明下 evict操作底层走的也是cancel逻辑让服务下线,所以调用链条中并没有显示evict的相关引用
readLock:
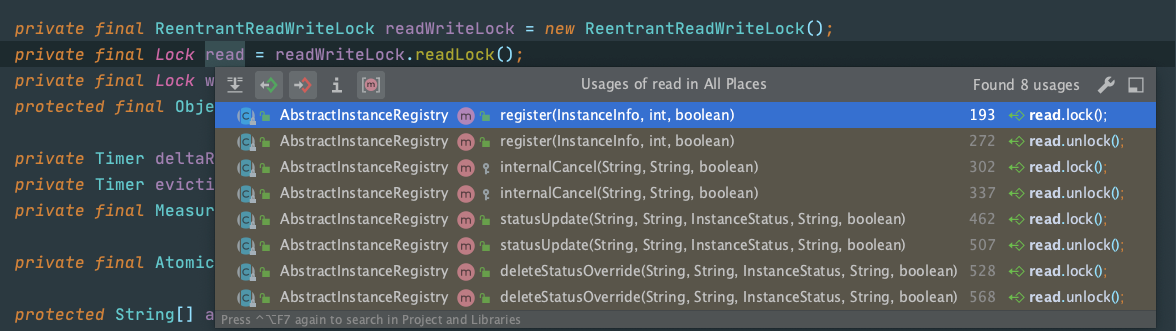
writeLock:

这里再回过头去回味上面的那句话:不要限定读锁只能加在读操作,写锁只能加在写操作,现在应该能明白这句话的含义了吧?
Eureka中确实是这么做的,读操作加写锁,写操作加读锁,一顿反向操作猛如虎

再来一张图完整总结读写锁的详细使用场景:
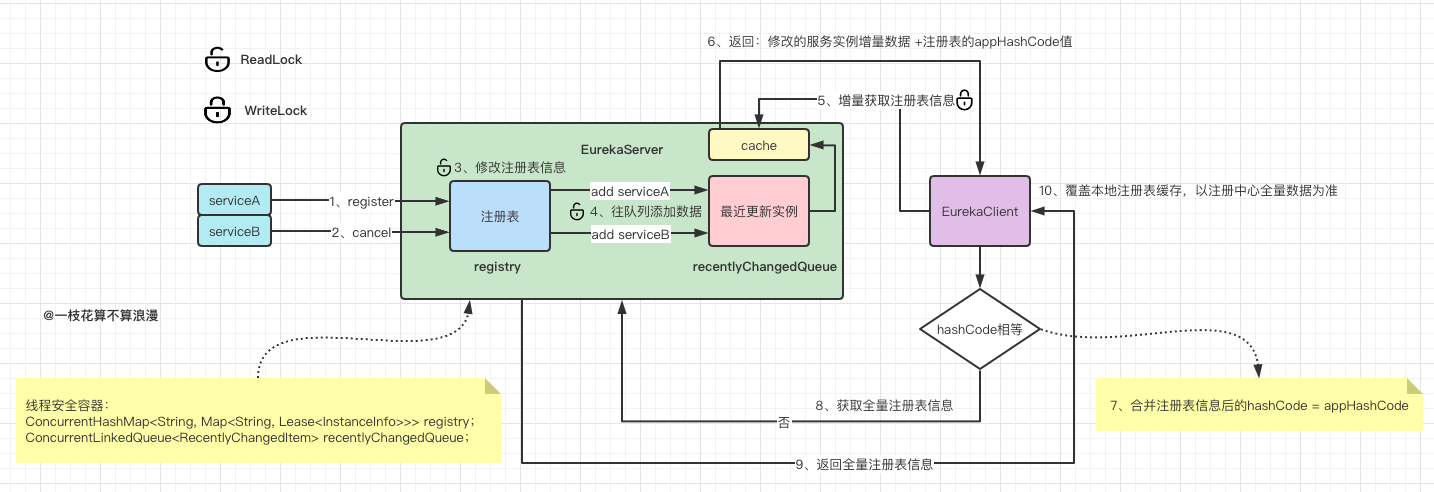
深层次思考
再去深究下上面提到的读写互斥操作,我们这里需要理解清楚`EurekaClient获取注册表信息操作是如何实现的:
(关于注册表获取的原理也可以参考下我之前的博文:https://www.cnblogs.com/wang-meng/p/12118203.html)
-
EurekaClient获取全量注册表信息实现方式:
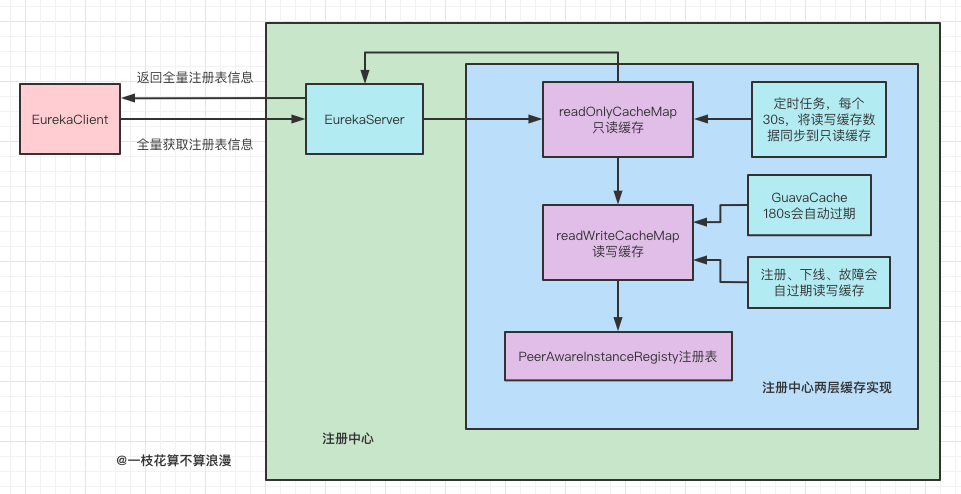
这里是EurekaClient第一次全量获取注册表的实现原理,从注册中心拉取到注册表后,EurekaClient会将注册表信息保存在本地的list中。
这里也要提下EurekaServer中的两层缓存机制,我们每次从注册中心拉取注册表时都是直接走的缓存,缓存使用的是谷歌提供的GuavaCahe
-
EurekaClient获取增量注册表实现方式: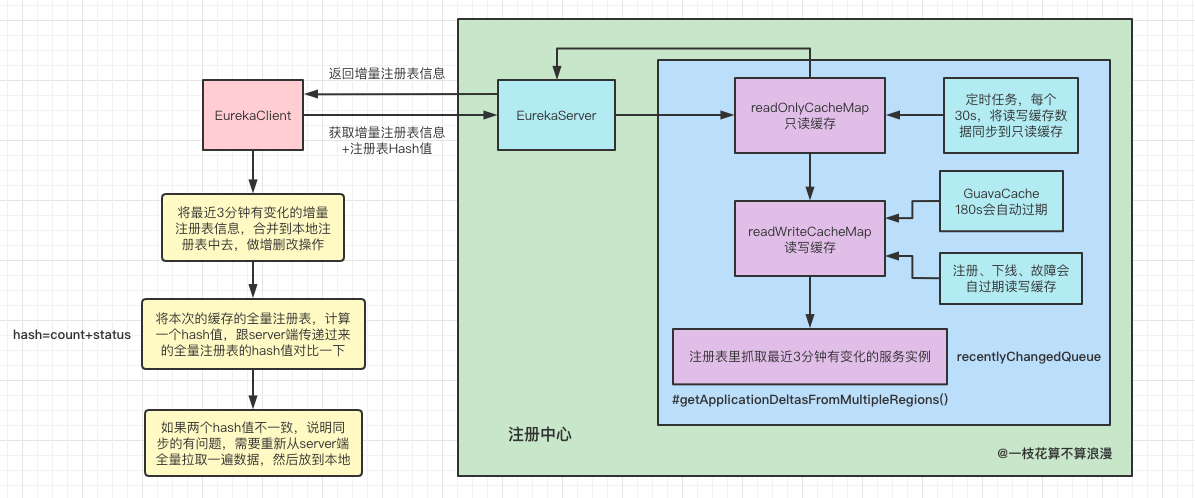
EurekaClient每隔30s去注册中心拉取注册表增量信息,拿回来后和本地缓存的注册信息进行比对,一顿增删改查操作后覆盖缓存中的注册信息数据。下面是增量获取注册表信息的代码示例,这里会从recentlyChangedQueue中获取存在变化的实例信息,最后还会设置一个appHashCode值:
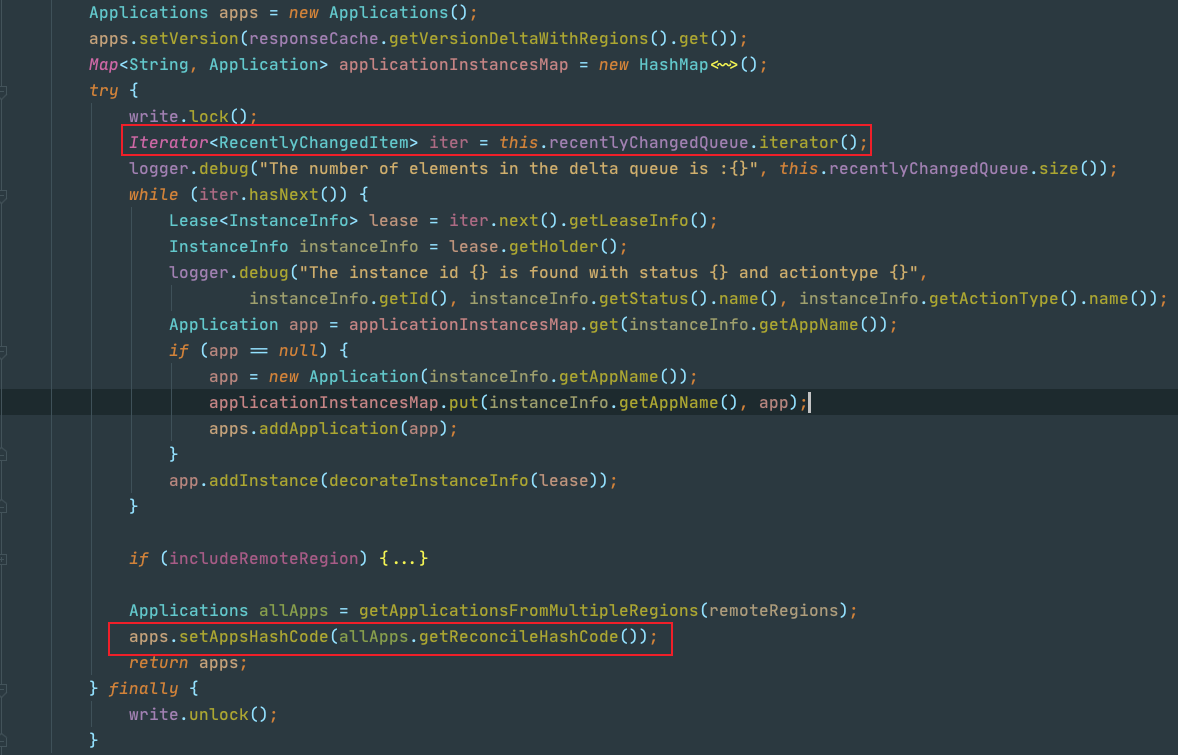
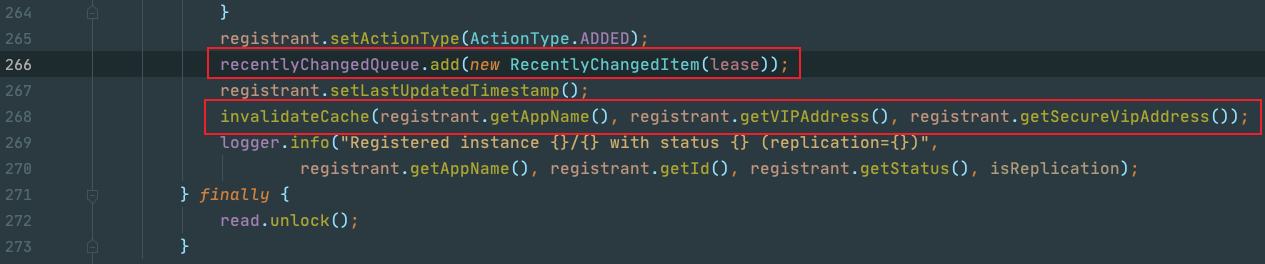
即使是获取增量注册表数据,也会从注册中心的缓存中获取,当EurekaClient对注册表进行register/cancel... 等操作时,会先去更新注册表中的数据,然后将改变的实例信息存放到一个队列中:recentlyChangedQueue ,这个队列只会存储最近三分钟有变化的节点信息,最后去清除EurekaServer中的readWriteCacheMap缓存信息
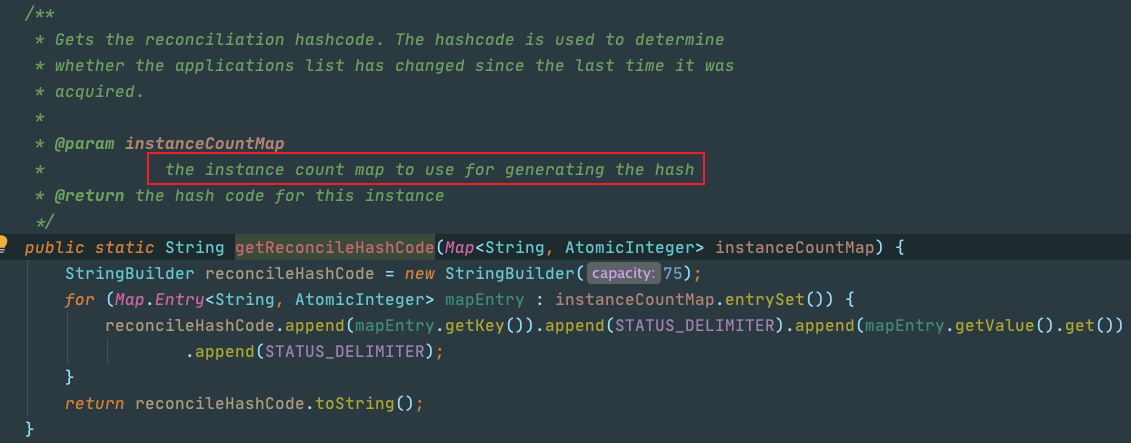
这里有一个重要的点需要注意:EurekaClient拉取的注册表增量信息 时还包含一个注册表全量信息的hash值,也就是上面代码中提到的appHashCode, 这个hash可以看做是所有注册实例数量的status分组后构成的:hash=count+status
为什么需要有这个hash校验的操作?这里是为了保证EurekaClient在获取增量更新后的数据和注册中心的注册表数据保持一致时做的一个校验。我们可以想象一下,EurekaClient 在获取到增量数据后一顿增删改查,按理说最终修改后的数据应该和注册表保持一致,但是由于某些原因并没有保持一致,那么后续再去做增量获取就毫无意义了!
所以这里如果判断hash不一致,就会立即再去注册中心获取全量数据来覆盖本地的脏数据。那么既然要获取这个hash值,此时的注册表就不能再有"写入"的操作了,例如register/cancel等,他们会改变注册表中实例的数量以及状态,所以这里就形成了一个互斥的操作:
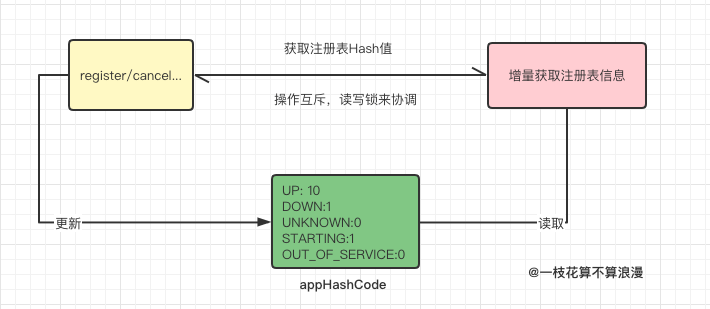
这里也就是为何注册表和最近更新实例队列都是现成安全的,还要加读写锁的原因了,这里是需要有一个互斥的操作。
再来回头思考
上面已经解释了EurekaServer中读写锁互换使用的场景了,这里大家肯定还会有其他疑惑,那么我们回过头再来思考以下几个问题:
- 站在作者的角度
EurekaServer为何这样设计读写锁的使用? - 站在读者的角度
EurekaServer增量获取注册表信息的性能如何? - 注册表
registry本身就是Map结构内存存取, 为何还要再使用缓存? - 为何
renew操作不加任何读写锁?这个明明是更新注册表的续约时间
1、EurekaServer中读写锁设计的思考
看完上面的操作读者可能和我有同样的困惑,作者为何要这样设计?
首先,我们来梳理下业务场景:这是一个典型的读多写少的场景(EurekaClient 默认每30s拉一次注册表增量信息):
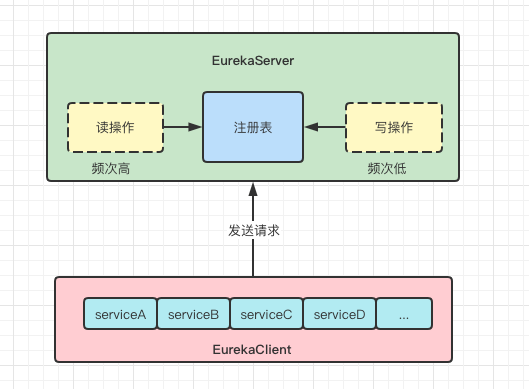
注册中心的"读操作":
读的时候必须要加全局锁防止新数据的写入更新,因为读的时候需要获取注册表的hash值,这里必须要加互斥锁
注册中心的"写操作":
注册中心的register/cancel/evict...等操作都是可以同步执行的,依托于ConcurrentLinkedQueue/ConcurrentHashMap并发容器的实现,这类更新最近更新队列或者修改注册表的操作都是线程安全的
反过来,如果上述一些操作的读写锁互换,等于说是在这两个并发容器上又加了一层写锁的逻辑,多一层互斥的性能损耗,性能返回会更差
2、EurekaServer 增量获取注册表信息的性能如何?
我们可以看下EurekaClient获取注册表的流程操作:
虽然我们每次增量拉取注册表都是加的写锁,但是这里借助了缓存技术,每次增量获取数据并不一定都会执行加锁操作,配合缓存的时候可以减少写锁的使用频率
其他的对于最近更新队列recentlyChangedQueue或者注册表registry的写入更新操作都是线程安全的,他们不需要通过读写锁来保证
3、注册表registry本身就是Map结构 为何还要再使用一层缓存?
其实答案已经在上面了,如果我们不借助于缓存,那么每次的增量获取操作都会针对于registry或者recentlyChangedQueue`去操作,每次都会加写锁,性能相对于直接读缓存会下降很多,所以这里借助了缓存来解决每次都需要加锁的问题
由此我们是否也可以想到另一个常用的框架 Spring是如何解决循环依赖问题的?答案也是使用多级缓存,到了这里有没有一种豁然开朗的感觉~
我们再继续深入思考一下,看下ResponseCacheImpl的代码实现:
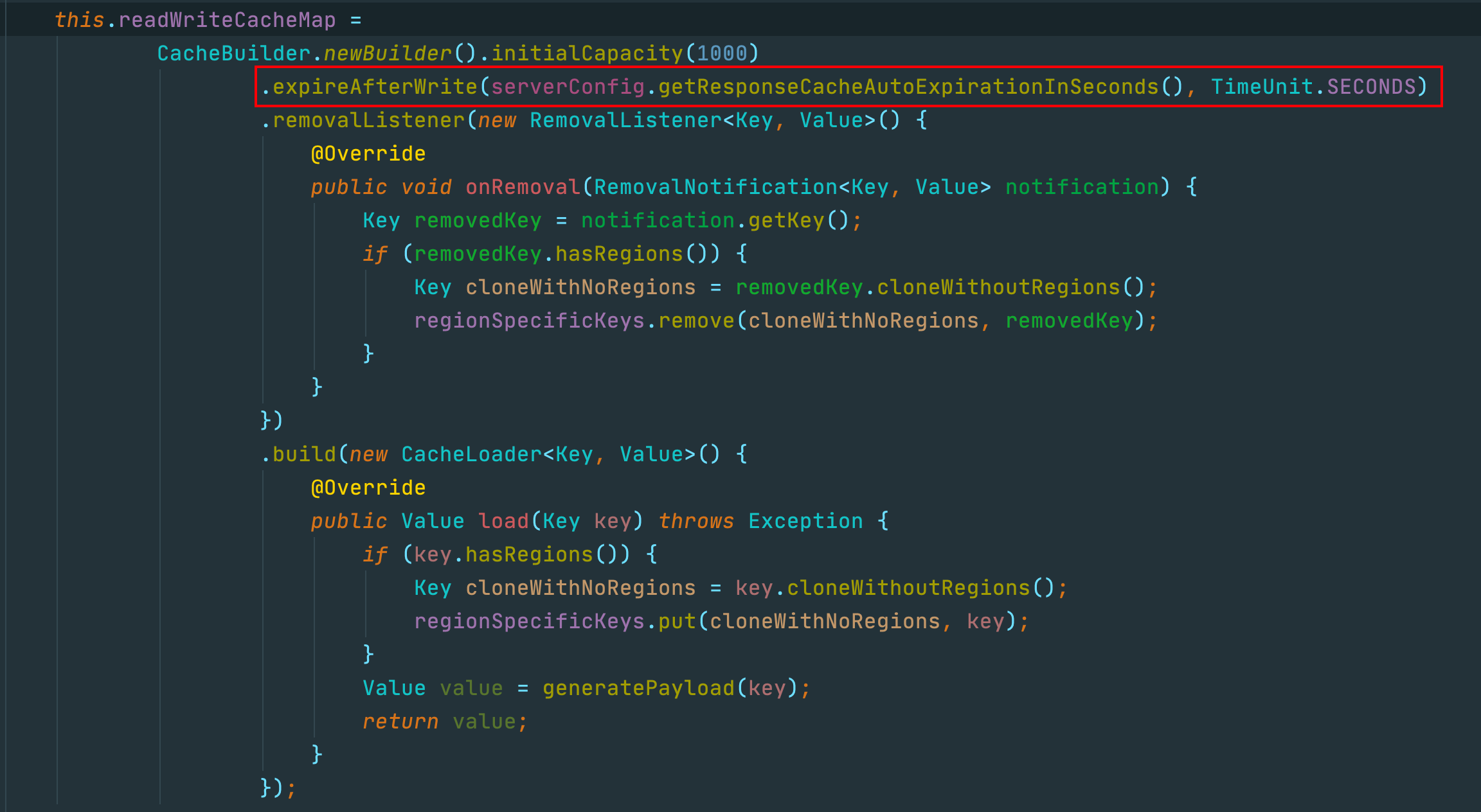
我们举例一种场景,这里使用的是expireAfterWrite,当我们的缓存过期后,同时有1w个客户端来拉取注册表增量信息,都会走到加写锁的逻辑,此时注册中心的吞吐量会降低很多吗?
这里如果使用refreshAfterWrites会不会更好一些?因为refreshAfterWrite是后台异步刷新,其他线程访问旧值,只会有一个线程在执行刷新,不会出现多个线程刷新同一个Key的缓存
当然这些可能也是多虑的,我并没有去实际测试这种场景,我猜测在请求量很大的情况下,增量获取注册信息加写锁内部的逻辑也会执行很快,因为都是一些内存的操作。至于使用expireAfterWrite 则是能够节省很多内存空间,也许作者在心里也有过这种利弊抉择 …(⊙_⊙;)…
4、为何renew 续约不需要加锁?
renew不加锁的原因很简单,续约操作是不会向最近更新队列中添加元素的,不会影响增量更新数据的拉取
这里也可以回顾下renew的作用,renew默认每30秒都会像注册中心发送一次心跳操作,注册中心收到心跳请求后会从注册表中拿出这个实例信息,然后更新该实例最后心跳的时间,这个心跳时间是注册中心用来做故障剔除的,如果一个实例在指定周期内没有发送心跳请求,则会被认为出现了故障 从注册中心摘除掉
但是renew操作对于实例的lastUpdateTimeBug的更新是有Bug的,我在之前的文章中也有提到过,看下源码注释:
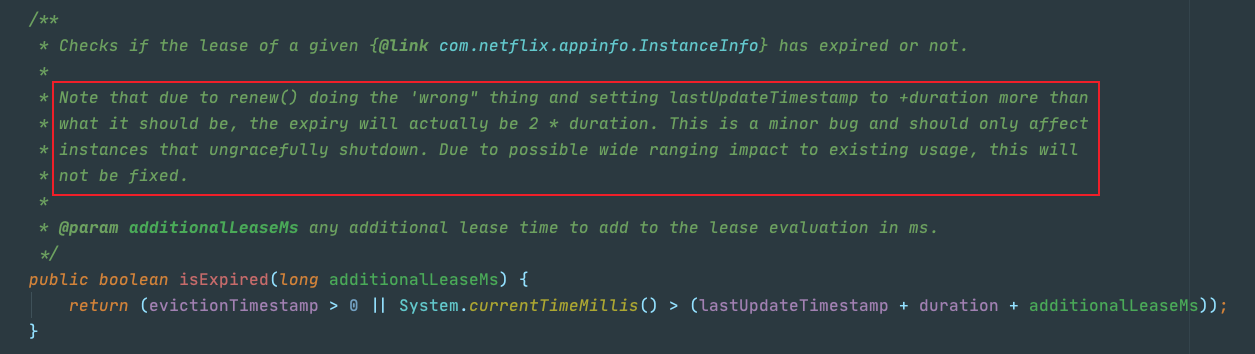
这里是注册中心故障感知时的一段代码,作者也在注释中说了:"renew()操作是有问题的,这里多加了一个duration的时间,但是我们又不会去修复这个问题,这里仅仅是影响故障被感知的时间而已,而我的系统就是最终一致的,所以我也不会去修复" (PS:每每看到这里我都会忍不住吐槽,他不知道我们为了提升故障的感知效率 做了很多努力 这或许也就是网上很多人说Eureka代码写的烂的原因吧??)
写在最后
最近在帮助公司面试一些候选人,我也会问一些 SpringCloud相关的问题,但经常一些候选人的回答:
"这些框架都过时了,我们使用了最新的xxx框架"、"你问的这些东西我只需要会用 我不需要知道原理"...
诸如此类的回答很多,我平时是一个比较喜欢刨根问底的人,坚信一切问题在源码面前都毫无秘密,学东西要知道其然也要知道其所以然。万丈高楼平地起,框架也只不过是辅助我们工作的一种工具,里面的实现还都是依赖于最底层的技术。
借用我老师的一句话:技术不分新旧,技术仅仅是一个载体,通过分析他们的源码去教给你的是架构设计、思想原理、方案机制、内核机制,以及分析源码的方法、技巧和能力。
PS:特别鸣谢及参考
以上是我阅读源码时的一些思考,写出来的内容可能会存在错误,有写的不对的地方还请大家跟我说明,希望能够和大家一同提高成长,欢迎加我微信交流:W510782645
参考以下博文,感谢原作者内容分享: