DF 类似于二维表的数据结果
| mame |
age |
| 狗山石 | 23 |
获取df的列名: df.columns
显示当前值 打印 df.show() show(2) show括号里面传入参数可以显示查看几行 show(2,False) False 是否全部显示 False 不隐藏
获取前10行数据 df.limit(10) 里面传递的一个整形 后面加上show() 可以打印
获取列值key df.select(["key"]) 传入参数写法 df.select([df[x] for x in keys]) 后面加上show() 可以打印
将每一行转化为json 并将行名,命名为wang df.select(to_json(struct([df["key"]])).alias("wang")).show()
把df格式转化列表 db.collect()
计算总数 db.count()
取出 db.take() 里面必须传入参数 除去2个
设置分区个数 db.repartition(5) 设置有5个partition
对 partition进行单独处理 db.foreachPartition(f) f 是一个函数
def f(iterator):
for x in iterator:
print(x) # 读取每个x,即每一条数据
print(x.asDict()) # 把 row的数据转化为 字典类型
news_data_rdd = df.rdd.mapPartitions(f).cache()
news_data_rdd = df.rdd.mapPartitions(lambda iterator: insert_from_memory(iterator, cur_index_name)).cache()
使用 mapPartitions 必须在此启动 news_data_rdd.count() 启动 news_data_rdd
df.select() 操作
from pyspark.sql.functions import to_json, struct,concat
# 将每一行转化为json 并将行名,命名为wang
df.select(to_json(struct([df["key"]])).alias("wang"))
# 将每一行转化为字符串 并将行名,命名为data
df.select(concat(*df.columns).alias('data'))
# 在窗口调试后面加上 show() 可以打印
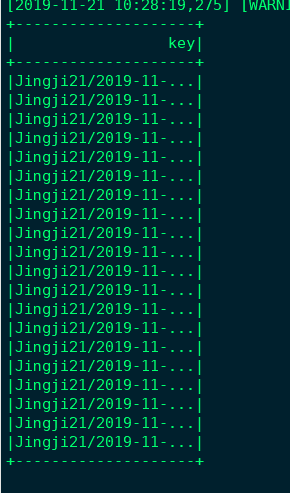
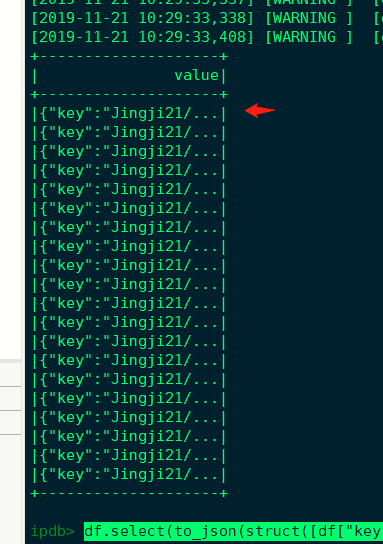
df.select() 操作 # 在窗口调试后面加上 show() 可以打印
df.select(["*"]) # 选择全部数据
df.select(["name"]) # 选择对应列操作
df 的写入操作
df.select(to_json(struct(["key","json"])).alias("value")).write.format("kafka").option("kafka.bootstrap.servers",','.join(["emr2-header-1.ipa.aidigger.com:6667", "emr2-header-2.ipa.
aidigger.com:6667"])).option("topic","text").save()
df.write 写入操作
写入kafka
to_json(struct(["key","json"])).alias("value") 把df转化为json格式
df.select(to_json(struct(["key","json"])).alias("value")).write.format("kafka").option("kafka.bootstrap.servers",','.join(["ip", "ip
"])).option("topic","主题名字").save()
from pyspark.sql.functions import to_json, struct,concat
df.select(concat(*df.columns).alias('data')).show()



收藏的博客