Hadoop Distributed File System 简称HDFS
一、HDFS设计目标
1、支持海量的数据,硬件错误是常态,因此需要 ,就是备份
,就是备份
,就是备份 2、一次写多次读
3、运行在普通的硬件上面
4、数据块尽量散步到各个节点中
二、HDFS不适合的场景
1、不适合低延迟的数据,对一个大文件整个文件进行读取,即批量读取而非随机读取
2、小文件
3、无法对文件的内容任意修改
三、HDFS架构
1、一个文件被划分成大小固定的多个文件块,分布的存储在集群中的节点中
一个文件一台电脑直接读取需要花费很多时间,但是多个电脑同时读取就可以看出速度啦。
2、同一个文件块在不同的节点中有多个副本

如果说第一个节点处的文件1失效不能工作了,那么hadoop根据你的配置去自动需找其他的副本,这些副本的拷贝是在hadoop的配置文件中进行指定的,副本的个数都是可以配置的。
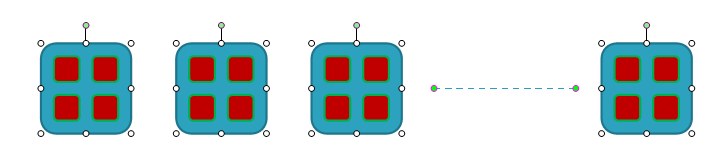
3、一个集中的地方保存文件的分块信息

集中的地方就叫做namenode用于保存分块的信息,namenode只有一个,首先我们必须从namenode获得分块信息,上面就是namenode中分块的信息。

上图是datanode的信息,就是讲文件进行分块存储,然后进行并行读取节点信息,相比传统的方式,一般是将硬盘作为一个节点进行存储,而hadoop则是将分布的主机作为节点进行存储。
4、HDFS体系结构
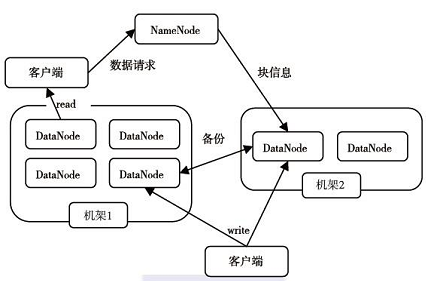
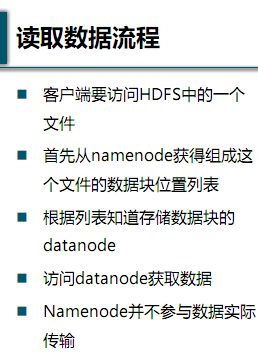
5、NameNode

6、DataNode

四、总结
1、Block:一个文件分块,默认为64M
2、NameNode:保存整个文件的目录信息、文件信息以及文件相应的分块信息,如果namenode支持很多的datanode数据节点信息时,因为读取任意一个文件都需要从namenode中读取信息,那读取namenode就将是文件读取的瓶颈,所以为了避免这个问题的出现,一般将namenode的信息保存到内存中,同时将一些信息持久化到磁盘中,防止读取失败时有备份信息。
3、DataNode:用于存储Blocks
4、HDFS的HA策略:NameNode一旦宕机,整个文件系统将无法工作。如果NameNode中的数据丢失,整个文件系统也就丢失了。所以从hadoop2.x开始,HDFS支持NameNode的active-standy模式,就是同时开启多个namenode当active模式工作时,standy模式会同步active所有的信息,当active不能工作时,standy就会转变为active模式来接管namenode。