所有系统调用都是以原子操作方式执行的。之所以这么说,是指内核保证了某系统调用中的所有步骤会作为独立操作而一次性加以执行,其间不会为其他进程或线程所中断。
原子性是某些操作得以圆满成功的关键所在。特别是它规避了竞争状态。竞争状态是这样一种情形:操作共享资源的两个进程(或线程),其结果取决于一个无法预期的顺序,即这些进程1获得 CPU 使用权的先后相对顺序。
以独占方式创建文件
当同时指定 O_EXCL 与 O_CREAT 作为 open()的标志位时,如果要打开的文件已然存在,则 open()将返回一个错误。这提供了一种机制,保证进程是打开文件的创建者。对文件是否存在的检查和创建文件属于同一原子操作。
这提供了一种机制,保证进程是打开文件的创建者。对文件是否存在的检查和创建文件属于同一原子操作。要理解这一点的重要性,请思考程序清单 5-1 所示代码,该段代码中并未使用 O_EXCL 标志。
fd = open(argv[1], O_WRONLY); /* Open 1: 检查文件是否存在 */ if (fd != -1) { /* 打开成功 */ printf("[PID %ld] File "%s" already exists ", (long) getpid(), argv[1]); close(fd); } else { if (errno != ENOENT) { /* 打开失败 */ errExit("open"); } else { printf("[PID %ld] File "%s" doesn't exist yet ",(long) getpid(), argv[1]); if (argc > 2) { /* 挂起5秒 */ sleep(5); printf("[PID %ld] Done sleeping ", (long) getpid()); } /* 另外一个进程创建了文件 */ fd = open(argv[1], O_WRONLY | O_CREAT, S_IRUSR | S_IWUSR); if (fd == -1) errExit("open"); /* 进程任务自己创建了文件 */ printf("[PID %ld] Created file "%s" exclusively ", (long) getpid(), argv[1]); /* MAY NOT BE TRUE! */ } }
由于第一个进程在检查文件是否存在和创建文件之间发生了中断,造成两个进程都声称自己是文件的创建者。结合 O_CREAT 和 O_EXCL 标志来一次性地调用 open()可以防止这种情况,因为这确保了检查文件和创建文件的步骤属于一个单一的原子(即不可中断的)操作。
向文件尾部追加数据
用以说明原子操作必要性的第二个例子是:多个进程同时向同一个文件尾部添加数据。为了达到这一目的,也许可以考虑在每个写进程中使用如下代码
if(lseek(fd,0,SEEK_END)==-1) errExit("lseek") if(write(fd,buf,len)!=len) errExit("write")
如果第一个进程执行到 lseek()和 write()之间,被执行相同代码的第二个进程所中断,那么这两个进程会在写入数据前,将文件偏移量设为相同位置,而当第一个进程再次获得调度时,会覆盖第二个进程已写入的数据。此时再次出现了竞争状态,因为执行的结果依赖于内核对两个进程的调度顺序。要规避这一问题,需要将文件偏移量的移动与数据写操作纳入同一原子操作。在打开文件时加入 O_APPEND 标志就可以保证这一点。
5.2 文件控制操作:fcntl()
fcntl()系统调用对一个打开的文件描述符执行一系列控制操作
cmd 参数所支持的操作范围很广。fcntl()的第三个参数以省略号来表示,这意味着可以将其设置为不同的类型,或者加以省略。内核会依据 cmd 参数(如果有的话)的值来确定该参数的数据类型。
fcntl()的用途之一是针对一个打开的文件,获取或修改其访问模式和状态标志(这些值是通过指定 open()调用的flag 参数来设置的)。要获取这些设置,应将 fcntl()的 cmd 参数设置为F_GETFL
int flags,accessMode; flags=fcntl(fd,F_GETFL); if(flags==-1) errExit("fcntl"); /*在上述代码之后,可以以如下代码测试文件是否以同步写方式打开*/ if(flags & O_SYNC) printf("write sync ")
判定文件的访问模式有一点复杂,这是因为 O_RDONLY(0)、 O_WRONLY(1)和 O_RDWR(2)这 3 个常量并不与打开文件状态标志中的单个比特位对应。因此,要判定访问模式,需使用掩码 O_ACCMODE 与 flag 相与,将结果与 3 个常量进行比对,示例代码如下:
accessMode=flags & O_ACCMODE;
if(accessMode==O_WRONLY||accessMode=O_RDWR)
printf("file is writeable")
可以使用 fcntl()的 F_SETFL 命令来修改打开文件的某些状态标志。允许更改的标志有O_APPEND、 O_NONBLOCK、 O_NOATIME、 O_ASYNC 和 O_DIRECT。系统将忽略对其他标志的修改操作。
使用 fcntl()修改文件状态标志,尤其适用于如下场景。 1.文件不是由调用程序打开的,所以程序也无法使用 open()调用来控制文件的状态标志(例如,文件是 3 个标准输入输出描述符中的一员,这些描述符在程序启动之前就被打开)。 2.文件描述符的获取是通过 open()之外的系统调用。比如 pipe()调用,该调用创建一个管道,并返回两个文件描述符分别对应管道的两端。再比如 socket()调用,该调用创建一个套接字并返回指向该套接字的文件描述符。 为了修改打开文件的状态标志,可以使用 fcntl()的 F_GETFL 命令来获取当前标志的副本,然后修改需要变更的比特位,最后再次调用 fcntl()函数的 F_SETFL 命令来更新此状态标志。 因此,为了添加 O_APPEND 标志,可以编写如下代码:
int flags; flags=fcntl(fd,F_GETFL); if(flags==-1) errExit("fcntl"); flags |=O_APPEND; if(fcntl(fd,F_GETFL,flags)==-1) errExit("fcntl");
5.4 文件描述符和打开文件的关系
文件描述符和打开的文件之间似乎呈现出一一对应的关系。然而,实际并非如此。多个文件描述符指向同一打开文件,这既有可能,也属必要。这些文件描述符可在相同或不同的进程中打开。要理解具体情况如何,需要查看由内核维护的 3 个数据结构。
进程级的文件描述符表。
针对每个进程,内核为其维护打开文件的描述符表。该表的每一条目都记录了单个文件描述符的相关信息,如下所示。 1.控制文件描述符操作的一组标志。目前,此类标志仅定义了一个,即 close-on-exec 标志 2.对打开文件句柄的引用。
系统级的打开文件表。
内核对所有打开的文件维护有一个系统级的描述表格,也称之为打开文件表,并将表中各条目称为打开文件句柄。一个打开文件句柄存储了与一个打开文件相关的全部信息,如下所示。 1.当前文件偏移量 2.打开文件时所使用的状态标志(即open()的 flags 参数)。 3.文件访问模式(如调用 open()时所设置的只读模式、只写模式或读写模式)。 4.与信号驱动 I/O 相关的设置 5.对该文件 i-node 对象的引用。
系统级文件系统的 i-node 表
每个文件系统都会为驻留其上的所有文件建立一个 i-node 表。这里只是列出每个文件的 i-node 信息,具体如下。 1.文件类型(例如,常规文件、套接字或 FIFO)和访问权限。 2.一个指针,指向该文件所持有的锁的列表。 3.文件的各种属性,包括文件大小以及与不同类型操作相关的时间戳
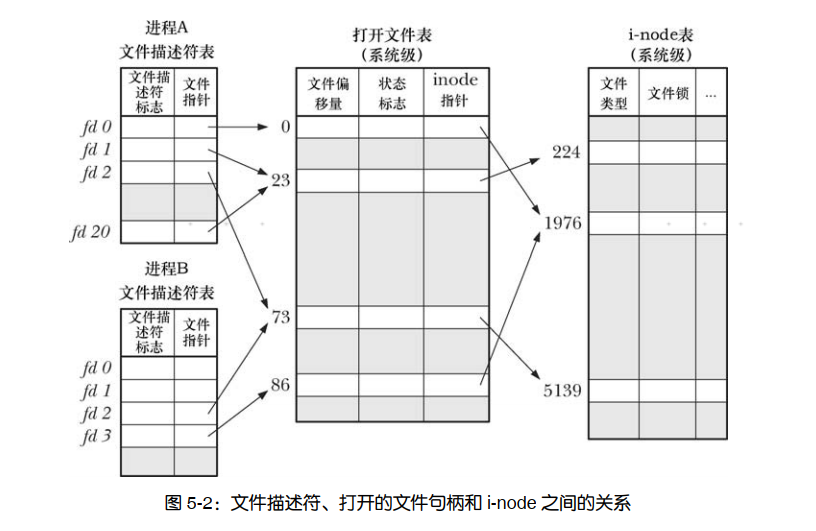
在进程 A 中,文件描述符 1 和 20 都指向同一个打开的文件句柄(23)。这可能是通过调用 dup()、 dup2()或 fcntl()而形成的
进程A 的文件描述符2 和进程B 的文件描述符2 都指向同一个打开的文件句柄(73)。这种情形可能在调用 fork()后出现(即进程 A 与进程 B 是父子关系),或者当某进程通过UNIX 域套接字将一个打开的文件描述符传递给另一进程时,也会发生。
此外,进程 A 的描述符 0 和进程 B 的描述符 3 分别指向不同的打开文件句柄,但这些句柄均指向 i-node 表中的相同条目(1976),换言之,指向同一文件。发生这种情况是因为每个进程各自对同一文件发起了 open()调用。同一个进程两次打开同一文件,也会发生类似情况。
上述讨论揭示出如下要点。
1.两个不同的文件描述符,若指向同一打开文件句柄,将共享同一文件偏移量。因此,如果通过其中一个文件描述符来修改文件偏移量,那么从另一文件描述符中也会观察到这一变化。无论这两个文件描述符分属于不同进程,还是同属于一个进程,情况都是如此。
2.要获取和修改打开的文件标志,如O_APPEND、O_NONBLOCK 和 O_ASYNC,可执行 fcntl()的 F_GETFL 和F_SETFL 操作,其对作用域的约束与上一条颇为类似。 相形之下,文件描述符标志( close-on-exec 标志)为进程和文件描述符所私有。对这一标志的修改将不会影响同一进程或不同进程中的其他文件描述符
5.5 复制文件描述符
Bourne shell 的 I/O 重定向语法 2>&1,意在通知 shell 把标准错误(文件描述符 2)重定向到标准输出(文件描述符 1)。因此,下列命令将把(因为 shell 按从左至右的顺序处理 I/O 重定向语句)标准输出和标准错误写入 result.log 文件:
./myscript >result.log 2>&1
shell 通过复制文件描述符2实现了标准错误的重定向操作,因此文件描述符 2 与文件描述符 1 指向同一个打开文件句柄。可以通过调用 dup()和 dup2()来实现此功能
要满足 shell 的这一要求,仅仅简单地打开 results.log 文件两次是远远不够的(第一次在描述符 1 上打开,第二次在描述符 2 上打开)。首先两个文件描述符不能共享相同的文件偏移量指针,因此有可能导致相互覆盖彼此的输出。再者打开的文件不一定就是磁盘文件。 dup()调用复制一个打开的文件描述符 oldfd,并返回一个新描述符,二者都指向同一打开的文件句柄。系统会保证新描述符一定是编号值最低的未用文件描述符
dup2()系统调用会为 oldfd 参数所指定的文件描述符创建副本,其编号由 newfd 参数指定。如果由 newfd 参数所指定编号的文件描述符之前已经打开,那么 dup2()会首先将其关闭。(dup2()调用会默然忽略 newfd 关闭期间出现的任何错误。故此,编码时更为安全的做法是:在调用dup2()之前,若 newfd 已经打开,则应显式调用 close()将其关闭。 )
fcntl()的 F_DUPFD 操作是复制文件描述符的另一接口,更具灵活性。该调用为 oldfd 创建一个副本,且将使用大于等于 startfd 的最小未用值作为描述符编号。 该调用还能保证新描述符( newfd)编号落在特定的区间范围内。总是能将 dup()和 dup2()调用改写为对 close()和 fcntl()的调用,虽然前者更为简洁。 文件描述符的正、副本之间共享同一打开文件句柄所含的文件偏移量和状态标志。然而,新文件描述符有其自己的一套文件描述符标志,且其 close-on-exec 标志( FD_CLOEXEC)总是处于关闭状态。下面将要介绍的接口,可以直接控制新文件描述符的close-on-exec 标志。 dup3()系统调用完成的工作与 dup2()相同,只是新增了一个附加参数 flag,这是一个可以修改系统调用行为的位掩码。
目前, dup3()只支持一个标志 O_CLOEXEC,这将促使内核为新文件描述符设置 close-on-exec 标志,设计该标志的缘由,类似于 4.3.1 节对 open()调用中 O_CLOEXEC 标志的描述。 dup3()系统调用始见于 Linux 2.6.27,为 Linux 所特有。Linux 从 2.6.24 开始支持 fcntl()用于复制文件描述符的附加命令: F_DUPFD_CLOEXEC。该标志不仅实现了与 F_DUPFD 相同的功能, 还为新文件描述符设置 close-on-exec 标志。 同样,此命令之所以得以一显身手,其原因也类似于 open()调用中的 O_CLOEXEC 标志。 SUSv3 并未论及 F_DUPFD_CLOEXEC 标志,但 SUSv4 对其作了规范
5.6 在文件特定偏移处的IO
系统调用 pread()和 pwrite()完成与 read()和 write()相类似的工作,只是前两者会在 offset 参数所指定的位置进行文件 I/O 操作,而非始于文件的当前偏移量处,且它们不会改变文件的当前偏移量
对 pread()和 pwrite()而言, fd 所指代的文件必须是可定位的。 多线程应用为这些系统调用提供了用武之地。 进程下辖的所有线程将共享同一文件描述符表。这也意味着每个已打开文件的文件偏移量为所有线程所共享。当调用pread()或 pwrite()时,多个线程可同时对同一文件描述符执行 I/O 操作,且不会因其他线程修改文件偏移量而受到影响。如果还试图使用 lseek()和read()(或 write())来代替 pread()(或pwrite()),那么将引发竞争状态,这类似于 5.1 节讨论 O_APPEND 标志时的描述(当多个进程的文件描述符指向相同的打开文件句柄时,使用 pread()和 pwrite()系统调用同样能够避免进 程间出现竞争状态)
5.7 分散输入和集中输出
readv()和 writev()系统调用分别实现了分散输入和集中输出的功能。
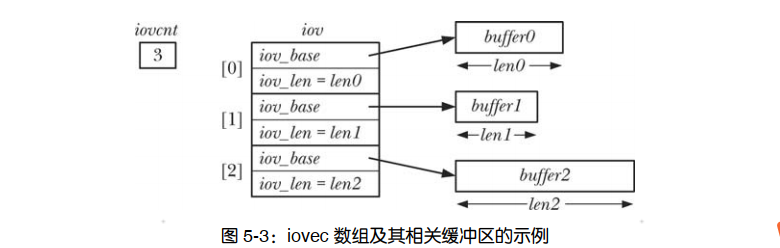
这些系统调用并非只对单个缓冲区进行读写操作,而是一次即可传输多个缓冲区的数据。数组 iov 定义了一组用来传输数据的缓冲区。整型数 iovcnt 则指定了 iov 的成员个数。 iov 中的每个成员都是如下形式的数据结构。
struct iovec {
void *iov_base;
size_t iov_len;
};
分散输入
readv()系统调用实现了分散输入的功能:从文件描述符 fd 所指代的文件中读取一片连续的字节,然后将其散置(“分散放置”)于 iov 指定的缓冲区中。这一散置动作从 iov[0]开始,依次填满每个缓冲区。 原子性是 readv()的重要属性。换言之,从调用进程的角度来看,当调用 readv()时,内核在 fd 所指代的文件与用户内存之间一次性地完成了数据转移。这意味着,假设即使有另一进程(或线程)与其共享同一文件偏移量,且在调用 readv()的同时企图修改文件偏移量, readv()所读取的数据仍将是连续的。 调用 readv()成功将返回读取的字节数,若文件结束将返回 0。调用者必须对返回值进行检查,以验证读取的字节数是否满足要求。若数据不足以填充所有缓冲区,则只会占用部分缓冲区,其中最后一个缓冲区可能只存有部分数据。
/** t_readv.c * 演示分散输入,从文件中读数据并分散到三个不同的缓冲区 * 如果输入文件没有特别准备好,这个例子是无法执行的 */ #include <sys/stat.h> #include <sys/uio.h> #include <fcntl.h> #include "tlpi_hdr.h" #define STR_SIZE 100 int main(int argc, char *argv[]) { int fd; struct iovec iov[3]; struct stat myStruct; /* 缓冲1 */ int x; /* 缓冲2 */ char str[STR_SIZE]; /* 缓冲3 */ ssize_t numRead, totRequired; if (argc != 2 || strcmp(argv[1], "--help") == 0) usageErr("%s file ", argv[0]); fd = open(argv[1], O_RDONLY); if (fd == -1) errExit("open"); totRequired = 0; iov[0].iov_base = &myStruct; iov[0].iov_len = sizeof(struct stat); totRequired += iov[0].iov_len; iov[1].iov_base = &x; iov[1].iov_len = sizeof(x); totRequired += iov[1].iov_len; iov[2].iov_base = str; iov[2].iov_len = STR_SIZE; totRequired += iov[2].iov_len; numRead = readv(fd, iov, 3); if (numRead == -1) errExit("readv"); /* 调用者必须对返回值进行检查,以验证读取的字节数是否满足要求 */ if (numRead < totRequired) printf("Read fewer bytes than requested "); printf("total bytes requested: %ld; bytes read: %ld ", (long) totRequired, (long) numRead); exit(EXIT_SUCCESS); }
集中输出
writev()系统调用实现了集中输出:将 iov 所指定的所有缓冲区中的数据拼接(“集中”)起来,然后以连续的字节序列写入文件描述符 fd 指代的文件中。对缓冲区中数据的“集中”始于iov[0]所指定的缓冲区,并按数组顺序展开。
像 readv()调用一样, writev()调用也属于原子操作,即所有数据将一次性地从用户内存传输到 fd 指代的文件中。因此,在向普通文件写入数据时, writev()调用会把所有的请求数据连续写入文件,而不会在其他进程(或线程)写操作的影响下分散地写入文件。
如同 write()调用, writev()调用也可能存在部分写的问题。因此,必须检查 writev()调用的返回值,以确定写入的字节数是否与要求相符。 readv()调用和 writev()调用的主要优势在于便捷。如下两种方案,任选其一都可替代对writev()的调用。
1.编码时, 首先分配一个大缓冲区, 随即再从进程地址空间的其他位置将数据复制过来,最后调用 write()输出其中的所有数据。
2.发起一系列 write()调用,逐一输出每个缓冲区中的数据。 尽管方案一在语义上等同于 writev()调用,但需要在用户空间内分配缓冲区,进行数据复制,很不方便。 方案二在语义上就不同于单次的 writev()调用,因为发起多次 write()调用将无法保证原子性。更何况,执行一次 writev()调用比执行多次 write()调用开销要小。
在指定的文件偏移量处执行分散输入/集中输出
Linux 2.6.30 版本新增了两个系统调用: preadv()、 pwritev(),将分散输入/集中输出和于指定文件偏移量处的 I/O 二者集于一身。它们并非标准的系统调用,但获得了现代 BSD 的支持
preadv()和 pwritev()系统调用所执行的任务与 readv()和 writev()相同,但执行 I/O 的位置将由 offset 参数指定 对于那些既想从分散-集中 I/O 中受益,又不愿受制于当前文件偏移量的应用程序(比如多线程的应用)而言,这些系统调用恰好可以派上用场
5.8 截断文件:truncate()和ftruncate()
truncate()和 ftruncate()系统调用将文件大小设置为 length 参数指定的值
若文件当前长度大于参数 length,调用将丢弃超出部分,若小于参数 length,调用将在文件尾部添加一系列空字节或是一个文件空洞。 两个系统调用之间的差别在于如何指定操作文件。
truncate()以路径名字符串来指定文件,并要求可访问该文件,且对文件拥有写权限。若文件名为符号链接,那么调用将对其进行解引用。而调用 ftruncate()之前,需以可写方式打开操作文件,获取其文件描述符以指代该文件,该系统调用不会修改文件偏移量。 若 ftruncate()的 length 参数值超出文件的当前大小, SUSv3 允许两种行为:要么扩展该文件(如 Linux),要么返回错误。而符合 XSI 标准的系统则必须采取前一种行为。相同的情况,对于 truncate()系统调用, SUSv3 则要求总是能扩展文件。
truncate()无需先以 open() 来获取文件描述符, 却可修改文件内容,在系统调用中可谓独树一帜
5.9 非阻塞IO
在打开文件时指定 O_NONBLOCK 标志,目的有二。 1.若 open()调用未能立即打开文件,则返回错误,而非陷入阻塞。有一种情况属于例外,调用 open()操作 FIFO 可能会陷入阻塞, 调用 open()成功后,后续的 I/O 操作也是非阻塞的。
2.若 I/O 系统调用未能立即完成,则可能只传输部分数据或者系统调用失败,并返回 EAGAIN 或EWOULDBLOCK 错误。具体返回何种错误将依赖于系统调用。
管道、 FIFO、 套接字、 设备(比如终端、 伪终端) 都支持非阻塞模式。(因为无法通过 open()来获取管道和套接字的文件描述符,所以要启用非阻塞标志,就必须使用 5.3 节所述 fcntl()的F_SETFL 命令。 ) 由于内核缓冲区保证了普通文件 I/O 不会陷入阻塞,故而打开普通文件时一般会忽略 O_NONBLOCK 标志。 然而, 当使用强制文件锁时 O_NONBLOCK标志对普通文件也是起作用的。
5.10 大文件IO
通常将存放文件偏移量的数据类型 off_t 实现为一个有符号的长整型。 (之所以采用有符号数据类型,是要以-1 来表示错误情况。 )在 32 位体系架构中(比如 x86-32),这将文件大小(即 2GB)的限制之下。 然而,磁盘驱动器的容量早已超出这一限制,因此 32 位 UNIX 实现有处理超过 2GB 大小文件的需求,这也在情理之中。由于问题较为普遍, UNIX 厂商联盟在大型文件峰会上就此进行了协商,并针对必需的大文件访问功能,形成了对 SUSv2 规范的扩展。 始于内核版本 2.4, 32 位 Linux 系统开始提供对 LFS 的支持(glibc 版本必须为 2.2 或更高)。另一个前提是,相应的文件系统也必须支持大文件操作。大多数“原生” Linux 文件系统提供了 LFS 支持,但一些“非原生”文件系统则未提供该功能
应用程序可使用如下两种方式之一以获得 LFS 功能。 1.使用支持大文件操作的备选 API。该 API 由 LFS 设计,意在作为 SUS 规范的“过渡型扩展”。因此,尽管大部分系统都支持这一 API,但这对于符合 SUSv2 或 SUSv3 规范的系统其实并非必须。这一方法现已过时。 2.在编译应用程序时,将宏_FILE_OFFSET_BITS 的值定义为 64。这一方法更为可取,因为符合 SUS 规范的应用程序无需修改任何源码即可获得 LFS 功能。
过渡型 LFS API
要使用过渡型的 LFS API,必须在编译程序时定义_LARGEFILE64_SOURCE 功能测试宏,该定义可以通过命令行指定,也可以定义于源文件中包含所有头文件之前的位置。该 API 所属函数具有处理 64 位文件大小和文件偏移量的能力。这些函数与其 32 位版本命名相同,只是尾部缀以 64 以示区别。其中包括: fopen64()、 open64()、lseek64()、 truncate64()、 stat64()、mmap64()和 setrlimit64()。 要访问大文件,可以使用这些函数的 64 位版本。例如,打开大文件的编码示例如下:
要获取 LFS 功能,推荐的作法是:在编译程序时,将宏_FILE_OFFSET_BITS 的值定义为 64。做法之一是利用 C 语言编译器的命令行选项: 另外一种方法,是在 C 语言的源文件中,在包含所有头文件之前添加如下宏定义: 所有相关的 32 位函数和数据类型将自动转换为 64 位版本。因而,例如,实际会将 open()转换为 open64(),数据类型 off_t 的长度也将转而定义为 64 位。换言之,无需对源码进行任何修改,只要对已有程序进行重新编译,就能够实现大文件操作。 显然,使用宏_FILE_OFFSET_BITS 要比采用过渡型的 LFS API 更为简单,但这也要求应用程序的代码编写必须规范(例如,声明用于放置文件偏移量的变量,应正确地使用 off_t,而不能使用“原生”的 C 语言整型)。
5.11 /etc/fd目录
对于每个进程,内核都提供有一个特殊的虚拟目录/dev/fd。该目录中包含“ /dev/fd/n”形式的文件名,其中 n 是与进程中的打开文件描述符相对应的编号。因此,例如, /dev/fd/0 就对应于进程的标准输入。 打开/dev/fd 目录中的一个文件等同于复制相应的文件描述符。
fd=open("dev/fd/1",O_WRONLY);
/* 等价于 */
fd=dup(1);
在为 open()调用设置 flag 参数时,需要注意将其设置为与原描述符相同的访问模式。这一场景下,在 flag 标志的设置中引入其他标志,诸如 O_CREAT,是毫无意义的。
程序中很少会使用/dev/fd 目录中的文件。其主要用途在 shell 中。许多用户级 shell 命令将文件名作为参数,有时需要将命令输出至管道,并将某个参数替换为标准输入或标准输出。出于这一目的,有些命令(例如, diff、 ed、 tar 和 comm)提供了一个解决方法,使用“ -”符号作为命令的参数之一,用以表示标准输入或输出。所以,要比较 ls 命令输出的文件名列表与之前生成的文件名列表,命令就可以写成:
ls | diff - oldfilelist
这种方法有不少问题。首先,该方法要求每个程序都对“ -”符号做专门处理,但是许多程序并未实现这样的功能,这些命令只能处理文件,不支持将标准输入或输出作为参数。其次,有些程序还将单个“ -”符解释为表征命令行选项结束的分隔符。 使用/dev/fd 目录,上述问题将迎刃而解,可以把标准输入、标准输出和标准错误作为文件名参数传递给任何需要它们的程序。所以,可以将前一个 shell 命令改写成如下形式:
ls | diff /dev/fd/0 oldfilelist
#或
ls | diff /dev/stdin oldfilelist
方便起见,系统还提供了 3 个符号链接: /dev/stdin、 /dev/stdout 和/dev/stderr,分别链接到/dev/fd/0、 /dev/fd/1 和/dev/fd/2。
5.12 创建临时文件
有些程序需要创建一些临时文件, 仅供其在运行期间使用, 程序终止后即行删除。 例如,很多编译器程序会在编译过程中创建临时文件。 GNU C 语言函数库为此而提供了一系列库函数。
本节将介绍其中的两个函数: mkstemp()和 tmpfile()。基于调用者提供的模板, mkstemp()函数生成一个唯一文件名并打开该文件,返回一个可用于 I/O 调用的文件描述符。
模板参数采用路径名形式,其中最后 6 个字符必须为 XXXXXX。这 6 个字符将被替换,以保证文件名的唯一性,且修改后的字符串将通过 template 参数传回。 因为会对传入的 template参数进行修改,所以必须将其指定为字符数组,而非字符串常量。
文件拥有者对 mkstemp()函数建立的文件拥有读写权限(其他用户则没有任何操作权限),且打开文件时使用了 O_EXCL 标志,以保证调用者以独占方式访问文件。 通常,打开临时文件不久,程序就会使用 unlink 系统调用将其删除。
tmpfile()函数会创建一个名称唯一的临时文件,并以读写方式将其打开。 (打开该文件时使用了 O_EXCL 标志,以防一个可能性极小的冲突,即另一个进程已经创建了一个同名文件。)