Disentangling by Factorising
我们定义和解决了从变量的独立因素生成的数据的解耦表征的无监督学习问题。我们提出了FactorVAE方法,通过鼓励表征的分布因素化且在维度上独立来解耦。我们展示了其通过在解耦和重构质量之间提供一个更好的权衡(trade-off)来实现优于β-VAE的效果。而且我们着重强调了通常使用的解耦度量方法的问题,并引入一种不受这些问题影响的新度量方法。
1. Introduction
学习能够揭示数据语义意思的可解释(interpretable)表示对人工智能具有重要的影响。该表征不仅对标准下行任务,如监督学习和强化学习,还对任务如转移学习和zero-shot学习这种人类胜于机器的学习 (Lake et al., 2016)有用。在深度学习社区中,对于学习数据变量的因素付出了很多的努力,共同将其称作学习一个解耦表征。当对这个术语没有标准的定义时,我们采用了Bengio et al. (2013)中的定义:一个表征即当在一个维度上有一个变化时,对应地将在变量的一个因素上发生了变化,其与其他变量上的变化是无关的。实际上,我们假设数据从一个有着固定数量的独立因素的变量中生成。我们集中处理图像数据,因为其变量中因素的影响更容易可视化
使用生成模型展示了在图像中学习解耦表征的巨大希望。明显地,半监督方法这种需要隐式或显式地了解数据真正的潜在因素的方法在解决解耦问题方面做得很好(Kulkarni et al., 2015; Kingma et al., 2014; Reed et al., 2014; Siddharth et al., 2017; Hinton et al., 2011; Mathieu et al., 2016; Goroshin et al., 2015; Hsu et al., 2017; Denton & Birodkar, 2017)。但是在理想的情况下我们想要以无监督的方式来学习它的原因有如下几点:
- 人类能够无监督地学习变量的因素(Perry et al., 2010)
- 标签是昂贵的,因为获得它们需要一个人在循环中
- 由人类分配的标签可能是不一致的,或者忽略了人类难以识别的因素。
β-VAE(Higgins et al., 2016)是基于变分自编码器(VAE)框架 (Kingma & Welling, 2014; Rezende et al., 2014)的生成模型中用于无监督解耦的一种流行方法。它使用了VAE的修改版本,在目标函数的变分后验和先验之间的KL散度中添加一个巨大的权重(β>1),其被证明是用于解耦的一个有效且稳定的方法。β-VAE的一个缺点就是为了获得更好的解耦效果,重构质量必须放弃(相对于VAE来说)。我们工作的目标就是在解耦和重构之间获得一个更好的权衡,允许在不需要降低重构质量的条件下也能获得更好的解耦效果。在该工作中,我们分析了该权衡的源头并提出了FactorVAE方法,其使用能够鼓励表征的边际分布因子化且本质上不影响重构质量的惩罚来增强了VAE目标函数。该惩罚表示为一个在这个边际分布和它的边际积之间的KL散度,并使用一个遵循GANs的散度最小化观点的判别器网络来优化它(Nowozin et al., 2016; Mohamed & Lakshminarayanan, 2016)。我们的实验结果显示了该方法在同样的重构质量下能够获得比β-VAE更好的解耦效果。我们指出了在Higgins et al., 2016的解耦度量中的缺点,并提出了一个新的度量方法来解决这个缺点。
一种流行的更换β-VAE的方法是InfoGAN (Chen et al., 2016),其是基于用于生成模型的生成对抗框架(Goodfellow et al., 2014)的。InfoGAN通过奖励观察结果和一组潜伏向量之间的相互信息来学习解耦表征。可是至少部分原因是它的训练稳定性问题(Higgins et al., 2016),这里有一些在基于VAE方法和InfoGAN方法之间的经验比较。利用在GAN文献中能帮助稳定训练状态的最新进展,在实验评估阶段我们还包含了InfoWGAN-GP方法,即InfoGAN的一种使用了Wasserstein距离方法(Arjovsky et al., 2017)和梯度惩罚方法的版本 (Gulrajani et al., 2017)。
总之,我们作出了如下贡献:
- 介绍了一种用于解耦的FactorVAE方法,在保持相同的重构质量下能够获得比β-VAE更高的解耦分数
- 我们识别出了在Higgins et al., 2016中的解耦度量的缺点,并提出了一个更具鲁棒性的替换方法
- 我们定量地对用于解耦的FactorVAE、β-VAE和InfoGAN的WGAN-GP方法两两进行比较。
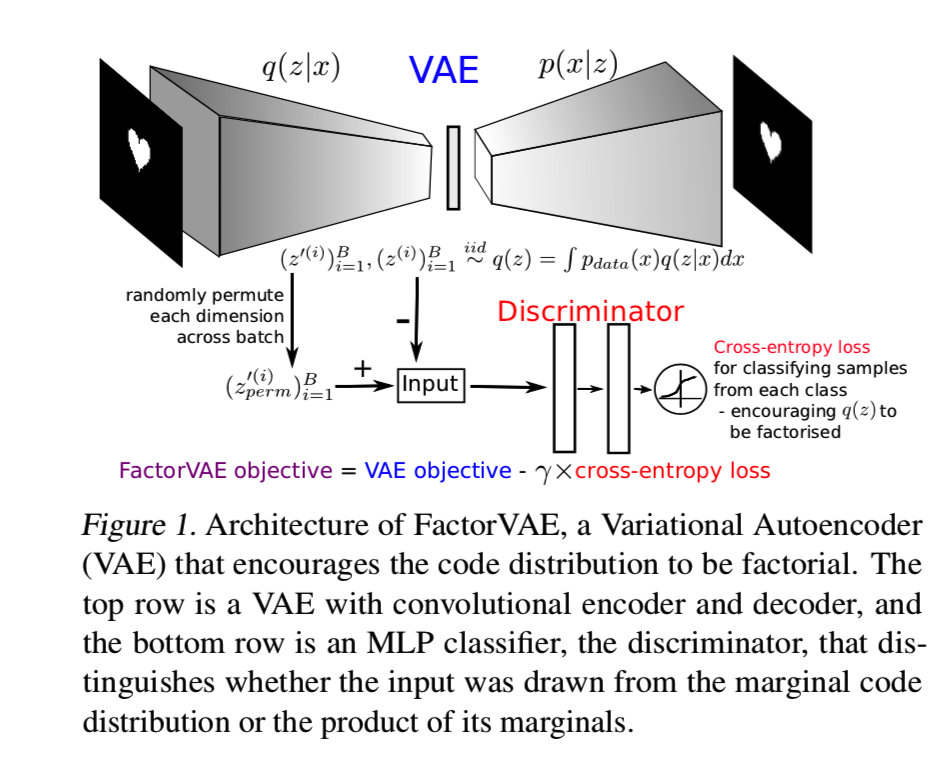
即从q(z)中采样得到的为![]() ,对该采样结果循环d次(d为z的维度数)随机交换维度上的值后生成的样本为
,对该采样结果循环d次(d为z的维度数)随机交换维度上的值后生成的样本为![]() ,希望分别作为判别器的输入,能够把
,希望分别作为判别器的输入,能够把![]() 判别为真,
判别为真,![]() 判别为假
判别为假
2. Trade-off between Disentanglement and Reconstruction in β-VAE
我们通过分析在β-VAE中提出的解耦和重构的平衡问题来启发我们的方法。首先,我们介绍了我们VAE框架的概念和结构。我们假设观察值为通过结合K个潜在因素f=(f1,...,fK)生成的![]() ,比如一张图x(i)需要设置x、y位置、其形状和大小等潜在因素信息才能生成。该观察值使用一个潜在/编码向量
,比如一张图x(i)需要设置x、y位置、其形状和大小等潜在因素信息才能生成。该观察值使用一个潜在/编码向量![]() 的真值来建模,解释为数据的表征。该生成模型使用标准高斯先验p(z)=N(0,I)定义,被内部为一个因素分布;decoder pΘ(x|z)通过一个神经网络实现参数化。对于一个观察值的变量后验为
的真值来建模,解释为数据的表征。该生成模型使用标准高斯先验p(z)=N(0,I)定义,被内部为一个因素分布;decoder pΘ(x|z)通过一个神经网络实现参数化。对于一个观察值的变量后验为![]() ,带着由encoder生成的均值和方差,同时通过一个神经网络实现参数化。变量后验能够被看作是与数据点x相关表征分布。对于整个数据集来说,其表征分布为:
,带着由encoder生成的均值和方差,同时通过一个神经网络实现参数化。变量后验能够被看作是与数据点x相关表征分布。对于整个数据集来说,其表征分布为:

其被当作边际后验和或集合后验,pdata表示经验数据分布。一个解耦表征的每个zj都与一个潜在因素fk相关。当我们假设这些因素独立变化时,我们希望有一个因素分布为![]()
β-VAE的目标函数为:
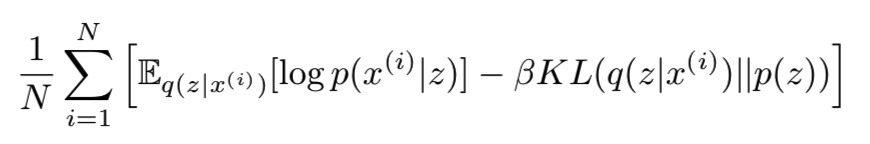
对于 β>=1,其为![]() 的一个变量下界;当β=1时即等价于VAE目标函数。其第一部分叫做负重构损失,第二部分为复杂度的惩罚,起到调节作用。我们可能将进一步打破该KL项(Hoffman & Johnson, 2016; Makhzani & Frey, 2017)为
的一个变量下界;当β=1时即等价于VAE目标函数。其第一部分叫做负重构损失,第二部分为复杂度的惩罚,起到调节作用。我们可能将进一步打破该KL项(Hoffman & Johnson, 2016; Makhzani & Frey, 2017)为![]() 。其中的I(x;z)即x和z在pdata(x)q(z|x)的联合分布下的互信息。详细推导可见附录C:
。其中的I(x;z)即x和z在pdata(x)q(z|x)的联合分布下的互信息。详细推导可见附录C:

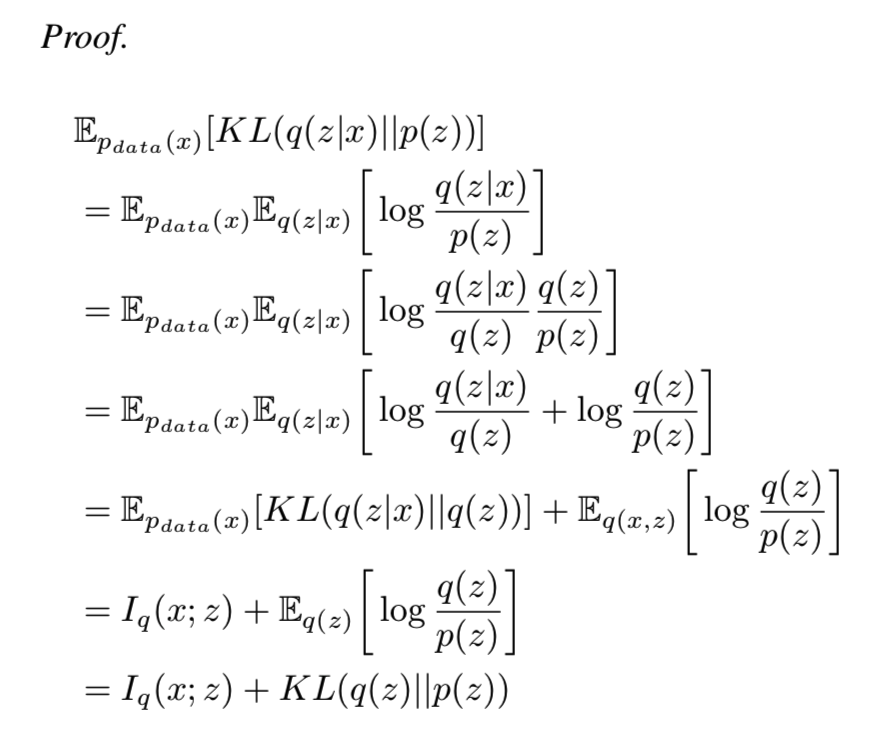
惩罚KL(q(z)||p(z))项会将q(z)推向因子先验p(z),让两个分布近似,鼓励z维度的独立性(因为p(z)是独立的),从而解决解耦问题。从另一方面来说,惩罚I(x;z)将减少存储在z中的关于x的信息数量,设置为高值的β时会导致差的重构效果(Makhzani & Frey, 2017)。因此将β设置为比1大的数时,对这两项的惩罚程度将更强,导致更好的解耦效果,但是会降低重构质量。当重构质量降低得过于严重时,潜在向量中将没有关于观察值的足够信息,使得该潜在向量不可能去恢复真正的因素。因此该方法存在β>1的值,能够给予更好的解耦,但是比VAE产生了更高的重构损失
即β-VAE通过减少![]() 两项的值来实现让q(z)更接近因子先验p(z),保证z每个维度的独立性,但是缺点就是I(x;z)的减少也将减少存储在z中的关于x的信息数量,增大重构损失
两项的值来实现让q(z)更接近因子先验p(z),保证z每个维度的独立性,但是缺点就是I(x;z)的减少也将减少存储在z中的关于x的信息数量,增大重构损失
3. Total Correlation Penalty and FactorVAE
对于解耦来说,比VAE更多地对I(x;z)项进行惩罚(即减少了存储在z中的关于x的信息数量,两者不相关,不利于重构)即不是必须的,也不是其所期望的。比如,InfoGAN通过鼓励I(x;c)值更高来解耦,此时c是潜在变量z中的一个子集。因此我们通过使用能够直接激励编码分布的独立性项来增强目标函数来构造FactorVAE的目标函数,如下所示:

即跟 β-VAE的目标函数相比添加了![]() 项,假设所有因素独立,则:
项,假设所有因素独立,则:![]() ,所以q(z)约等于
,所以q(z)约等于![]() ,后面那一项就是希望能够训练两个分布越来越接近,那就说明x中的因素越来越独立
,后面那一项就是希望能够训练两个分布越来越接近,那就说明x中的因素越来越独立
![]() 称为总相关(Total Correlation, TC, Watanabe, 1960),是一种用于多随机变量的流行的独立性测量方法。在该例子中,当q(z)和
称为总相关(Total Correlation, TC, Watanabe, 1960),是一种用于多随机变量的流行的独立性测量方法。在该例子中,当q(z)和![]() 含有大量组分的混合物时,该项是十分难算的,而且直接的Monte Carlo评估方法需要传递整个数据集给每个q(z)评估。因此我们为了优化该项,使用了一个替换的方法。
含有大量组分的混合物时,该项是十分难算的,而且直接的Monte Carlo评估方法需要传递整个数据集给每个q(z)评估。因此我们为了优化该项,使用了一个替换的方法。
我们从观察开始,我们能通过先随机均匀地选择一个数据点x(i)来高效地从样本q(z)中采样,然后再将x(i)输入q(z|x(i))中采样得到z。然后通过先从q(z)中采样d个样本来生成![]() 分布,然后再从
分布,然后再从![]() 中采样z',然后忽略除某一个维度以外的所有维度,然后就能够对这两个分布进行计算。
中采样z',然后忽略除某一个维度以外的所有维度,然后就能够对这两个分布进行计算。
另一种更高效的替换![]() 采样的方法是从q(z)中采样一个batch,然后在batch中为每个潜在向量的维度进行随机交换,可见算法1:
采样的方法是从q(z)中采样一个batch,然后在batch中为每个潜在向量的维度进行随机交换,可见算法1:
B即为B个batch,d表示潜在向量z的维度大小

即从q(z)采样出一批z后,还要随机选择batch中的某个zπ(i)第j维去换掉z(i)的第j维,对于batch中的每个z来说都循环进行该交换d次,最后得到一个新的z(i),得到![]() ,这样得到的新的潜在向量与从
,这样得到的新的潜在向量与从![]() 中采样出来的结果相似
中采样出来的结果相似
这是一种使用在独立测试文献 (Arcones & Gine, 1992)中的标准技巧,只要batch是足够的,这些采样样本的分布将近似于![]()
能够从两个分布中进行采样使得我们能够使用密度比(density-ratio)技巧 (Nguyen et al., 2010; Sugiyama et al., 2012) 来最小化它们的KL散度,该技巧包含了训练一个分类器/判别器来近似KL项中出现的密度比。假设我们有一个判别器D(在该例子中是一个MLP),其输出一个输入是来自q(z)而不是![]() 的概率D(z)的估计,因此我们有:
的概率D(z)的估计,因此我们有:
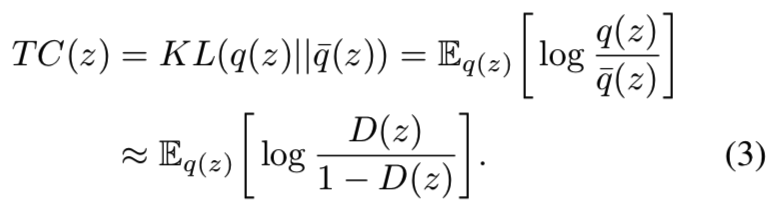
我们共同训练判别器和VAE。在实际中,VAE的参数将使用在等式(2)中的目标函数更新,使用上面基于判别器的来自等式(3)的近似代替等式(2)中的TC项。判别器被训练来对来自q(z)和![]() 的样本进行分类,因此为了估计TC需要学习去近似密度比。算法2为FactorVAE的伪代码:
的样本进行分类,因此为了估计TC需要学习去近似密度比。算法2为FactorVAE的伪代码:

- 即从q(z)随机选择m个批量观察值
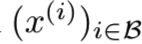 ,即得到batch Β
,即得到batch Β - 从这m个观察值encoder获得样本

- 然后计算该目标函数对数似然估计,得到encoder的参数Θ,更新其参数
- 然后再从q(z)中随机选择m个批量观察值
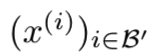 ,即得到batch B'
,即得到batch B' - 输入encoder获得潜在向量样本
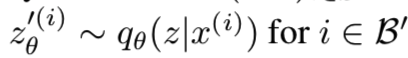
- 对batch B'中的所有z'使用上面的替换算法替换后得到新的潜在向量

- 然后将这两次随机选取得到的潜在向量值一一输入判别器,希望其能够将
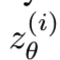 判定为真,即为1;将
判定为真,即为1;将 判定为假,即为0
判定为假,即为0 - 然后计算判别器的交叉熵损失梯度来更新判别器的参数Ψ
- 循环重复上面的步骤直至收敛
着重强调低的TC值是必需的,但是对于一个有意义的解耦来说还不够。比如,当q(z|x)=p(z),TC=0,但是z没有携带任何关于数据的信息。因此有低的TC值仅在我们能在潜在向量中保存信息时有意义,所以控制重构损失是很重要的。
在GAN文献中,散度最小化通常是在数据空间上的两个分布之间完成的,这通常是非常高维的数据(如图像)。因为这两种分布往往有不相交的支持,使得训练不稳定,特别是当判别器较强时。因此使用技巧如instance noise (Sønderby et al., 2016) 去弱化判别器或者使用一个critic,就像Wasserstein GANs (Arjovsky et al., 2017)中一样去替代判别器是十分必要的。在该论文中,我们最小化潜在空间的两个分布间的散度(如 (Mescheder et al., 2017)里一样),通常潜在空间相对于数据空间是更低的维度,且两个分布有重叠的支持。我们观察到对于足够的大batch size来说训练是稳定的(如batch size=64在维度d=6时表现得很好),这样就允许我们使用一个强的判别器
4. A New Metric for Disentanglement
我们使用在该论文中解耦的定义是在表征中一维的改变完全对应于变量中一个因素的改变,这显然是一个简单化定义。它不允许因素之间的关联或它们之上的层次结构。因此该定义看起来更适合去合成带有独立因素的向量的数据而不是更真实的数据集。可是如我们将要在下面展示的一样,鲁棒的解耦问题在这样简单的设定下是不能被完全解决的。其中的一个阻碍就是没有用于测量解耦的可靠的定量度量标准。
一个流行的测量解耦的方法是通过检查潜在遍历:在遍历一次(即调节该维度的值的大小,如从-2慢慢调到2)潜在空间的一个维度时,可视化重构的变化,下面的图3就是做了这样的操作。虽然潜在遍历可以作为一个有用的指示器来判断模型何时无法解耦,但是这种方法的定性使得它不适合可靠地比较算法。这样做需要在训练期间检查多个参考图像、随机种子和点上的大量潜在遍历。让一个人在循环中评估遍历也是非常耗时和具有主观性的。不幸的是,对于没有可用的真实变量因子的数据集,目前这是评估解耦的唯一可行选项。
Higgins et al. (2016) 提出了一种有监督的度量方法,它试图在给定数据集的真实因素时量化解耦。该度量即如下训练中的线性分类器的错误率。
- 选择一个因素k,比如设置大小为3;
- 生成带有该固定因素的数据x,其他的因素如颜色、位置等信息就随机变化;
- 输入encoder获得它们的表征(定义为q(z|x)的均值);
- 取这些表征两两之差的绝对值
- 然后,这些统计量每对之间的均值和为分类器提供一个训练输入,固定因子指标k为相应的训练输出
即最后结果最小的维度即对应于该因素k,说明该因素由该维度控制
可见图2的上半部分:

所以如果表征能够完美地解耦,我们能够看见在该与变量固定因素相关的训练输入的维度上的值为0,分类器将学会映射该0值的索引到该因素的索引。
可是该度量有几个缺点:
- 首先,它可能对线性分类器优化的超参数敏感,例如优化器及其超参数、权重初始化和训练迭代次数的选择
- 其次,使用线性分类器并不那么直观——我们可以得到每个因子对应于维度的线性组合而不是单个维度的表示。
- 最后,也是最重要的一点,这个度量有一个失效模式:k个因素中即使只有K - 1个被解耦,它也能给出100%的准确度;为了预测剩余的因子,分类器只需学习检测与K - 1个因子对应的所有值何时为非零。
该情况的例子如图3所示:

为了解决该弱点,我们提出一个新的解耦度量方法。
- 选择一个因素k;
- 生成带有该固定因素的数据,其他的因素就随机变化;
- 获得它们的表征;
- 通过使用整个数据(或足够大的随机子集)的经验标准差将每个维度标准化;
- 得到这些归一表征的每个维度的经验方差
- 然后有着最低方差的维度的索引和和目标索引k为分类器提供了一个训练输入/输出示例
即有着最低方差的维度对应于因素k,说明该因素由该维度控制
详情可见上面图2的下半部分
因此如果表征能完美地解耦,与固定因素相关的维度中的经验方差将为0。我们对表征进行标准化,使argmin对于每个维度中的表征的重新缩放是不变的。当输入和输出坐落在一个离散空间中时,最优分类器为多数投票分类器(详见附录B),度量为分类器错误率。
得到的分类器是训练数据的确定性函数,因此不需要优化超参数。我们还认为,这个度量在概念上比前一个度量更简单、更自然。最重要的是,它避免了早期度量的失效模式,因为分类器需要看到给定因素的潜在维数的最小方差才能正确分类。
我们认为开发一个不使用真正因子的可靠的无监督解耦度量方法是未来研究的一个重要方向,因为无监督解耦对于我们无法获得真实因子的场景非常有用。考虑到这一点,我们相信拥有一个可靠的监督度量仍然是有价值的,因为它可以作为评估无监督度量方法的黄金标准。
5. Related Work
最近有几项研究使用判别器来优化散度,以鼓励潜在编码的独立性。对抗自编码器(AAE, Makhzani et al., 2015)移除了VAE目标函数中的I(x;z)项,通过密度比技巧最大化负重构损失-KL(q(z) || p(z))的值,展示了在半监督分类和无监督聚类中的应用。这意味着AAE目标不是对数边际似然的下界。虽然优化一个下界并不是完全必要的,但它确实确保我们有一个有效的生成模型;拥有一个具有解耦潜在向量的生成模型的好处是,它是一个单一的模型,可以用于各种任务,例如基于模型的RL规划、视觉概念学习和半监督学习等。在PixelGAN自编码器中(Makhzani & Frey, 2017),同样的目标也被用来研究潜在编码与解码器之间的信息分解。作者指出,在编码器的输入中添加噪声是至关重要的,这意味着限制编码中包含的关于输入的信息是至关重要的,而I(x;z)项不应该从VAE目标中删除。Brakel & Bengio (2017)也使用一个判别器对编码的分布与其边值乘积之间的Jensen-Shannon散度进行惩罚。然而,他们使用的是带有确定性编码器和解码器的GAN损失,且只在独立成分分析源分离的背景下探索他们的技术。
早期在无监督解耦中的研究包含(Schmid-huber, 1992) 企图通过惩罚给定其他潜在维度的可预测性去解耦在一个自动编码器中的编码,以及 (Desjardins et al., 2012) 使用玻尔兹曼机的一个变体来解耦数据中两个变量的关系。最近 Achille & Soatto (2018)在监督学习的背景下,使用了一个惩罚TC项的损失函数。他们表明,他们的方法可以扩展到VAE环境,但没有进行任何有关解耦的实验来支持该理论。在同期的研究中,Kumar et al. (2018) 在VAEs中使用矩匹配来惩罚潜在维度之间的协方差,但不限制平均或更高的矩。我们在附录F中提供了这些相关方法的目标,并展示了包括AAE在内的解耦性能的实验结果。
已经有很多工作使用可预测性的概念来量化解耦,最多的是从潜在编码z中预测真实因素f=(f1,...,fK)的值。日期再推回Yang & Amari (1997),其在线性ICA环境中学习从表征到因子的线性映射,并量化此映射与排列矩阵的距离。最近的Eastwood & Williams (2018)研究通过训练Lasso回归器将z映射到f,并使用训练后的权值对解耦进行量化,将这一思想扩展到解耦。与其他基于回归的方法一样,该方法引入了超参数,如优化器和Lasso惩罚系数。Higgins et al. (2016)的度量方法和我们提出的度量方法都从带有一个固定fk但其他f-k对随机变化的图像的z中预测因素k。Schmidhuber (1992) 量化z的不同维度之间的可预测性,使用一个训练有素的预测器从z - j预测zj
不变性和等方差性在文献(Goodfellow et al., 2009; Kivinen & Williams, 2011; Lenc & Vedaldi, 2015)中经常被认为是表征的理想性质。如果在数据的有害因素(与任务无关)发生更改时,某个表征没有发生更改,则该表征对于特定任务来说是不变的。当改变变量的因子时,等方差性表示以稳定和可预测的方式变化。在本文所使用的意义上,解耦表征是等变的,因为改变一个变量因子将以可预测的方式改变解耦表征的某一维。给定一个任务,通过忽略编码该任务的有害因素的维度,可以很容易地从解耦表征中获得一个不变的表征(Cohen & Welling, 2014)。
基于本文的初步版本,(Chen et al., 2018)最近提出了一种基于小批量的方法来替代我们基于密度比技巧的方法来估计总相关性,并引入了一种信息理论解耦度量方法。
6. Experiments
在下面的数据集中比较FactorVAE和β-VAE:
i)已知生成因素的数据集,即定义好下面的因素就能够生成相同的图像:
- 2D Shapes(Matthey et al., 2017):737280个带着真实因素[值的数量]:形状shape[3]、大小scale[6]、方向orientation[40]、x位置x-position[32]和y位置y-position[32]的2D形状的二进制的64*64大小的图像
- 3D Shapes(Burgess & Kim, 2018):480000张带着真实因素:形状shape[4]、大小scale[8]、方向orientation[15]、背景颜色floor clour[10]和目标颜色object colour[10]的大小为64*64*3的3D形状的RGB图
ii)未知生成因素的数据集:
- 3D Faces (Paysan et al., 2009):239840张大小为64*64的3D Faces灰度图
- 3D Chairs(Aubry et al., 2014):86366张大小为64*64*3的椅子CAD模型的RGB图
- CelebA(裁剪版)(Liu et al., 2015):202599张大小为64*64*3的名人头像的RGB图
该实验的细节如encoder/decoder的结构和超参数设置可见附录A。解耦度量方法的细节以及根据其超参数的敏感性分析在附录B中给出。
从图4中可见FactorVAE比VAEs(β=1)得到更好的解耦分数,同时牺牲的重构损失更少,着重强调了添加总相关性惩罚到VAE目标中的解耦效果:

给定相同的重构损失,FactorVAE最好的解耦分数明显比β-VAE要好。
在图5中能够更清晰地看出FactorVAE(γ=40)的最好平均解耦分数大约是0.82,明显地比β-VAE(β=4)的要高,其大约为0.73,两者的重构损失大概都是45:

在图6中我们可以看见两个模型都有找到x位置、y位置和大小的能力,但是不能解耦方向和形状,尤其是 β-VAE。对于这个数据集,没有一个方法能够鲁棒地捕获形状,即该变量的离散因素

作为一个完整性检查,我们还评估了我们的度量与Higgins et al. (2016)的度量之间的相关性。Pearson(线性相关系数):0.404,Kendall(排序相同的配对比例):0.310,Spearman(排名线性相关):0.444,p值均为0.000。因此,正如预期的那样,这两个度量方法显示出相当高的正相关。
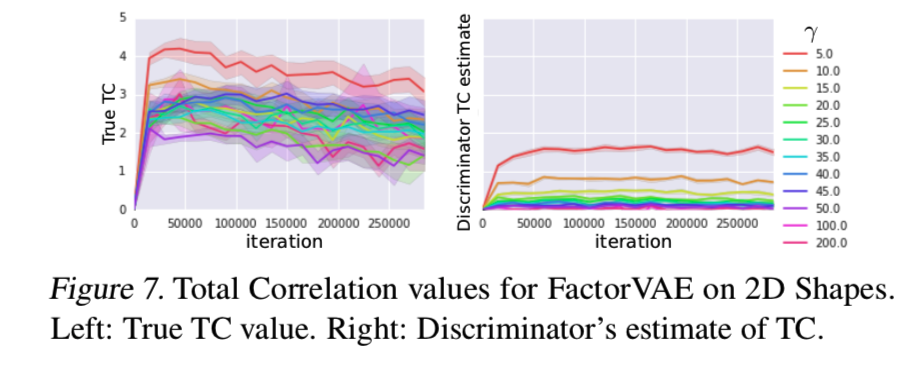
我们还研究了如何判别器对总相关性(TC)的估计行为和γ对真正的TC的影响。从图7中可以看出,判别器总是低估了真实TC,这一点也在 (Rosca et al., 2018)研究中得到了证实。然而真正的TC减少在训练中,以及更高的γ将导致TC的降低,因此使用判别器获得的梯度能够充分鼓励编码分布的独立性:
然后我们评估了InfoWGAN-GP,它是Info-GAN的副本,使用了Wasserstein距离和梯度惩罚。有关概述,请参见附录G。Info-GAN的一个优点是,其目标的蒙特卡罗估计相对于其参数是可微的,即使对于离散编码c也是如此,这使得基于梯度的优化非常简单。相比之下,基于VAE的梯度优化方法依赖于reprameterisation技巧,需要z是一个可重参数的连续随机变量,替代方法需要梯度估计的各种方差减少技术 (Mnih & Rezende, 2016; Maddison et al., 2017)。
因此,我们可能期望Info(W)GAN(-GP)在某些因素是离散的情况下显示出更好的解耦性。因此,我们使用了4个连续潜在向量(每个连续因子对应一个)和3个类别的一个分类潜在向量(每个形状一个)。我们微调λ,Info(W)GAN(-GP)中互信息项的权重∈{0.0, 0.1, 0.2,……,1.0},噪声变量数目∈{5,10,20,40,80,160},以及生成器的学习率∈{10−3,10−4}、判别器的学习率∈{10−4,10−5}。
但是从图8我们可以看见解耦分数是低的:

从图9的潜在向量遍历可以看出,模型只学习到了大小因子,并试图将位置信息放入离散编码中,这也是解耦分数较低的原因之一。然而,使用5个连续编码和没有分类编码的方法并没有提高解耦分数。早期停止的Info-GAN(训练不稳定发生前-见附录H)也给出了类似的结果。一些潜在遍历给出空白重构的事实表明,该模型不能很好地推广到p(z)域的所有部分:

InfoWGAN-GP在这个数据集上表现不佳的一个原因可能是InfoGAN对生成器和判别器结构很敏感,这是我们没有进行广泛微调的一点。我们使用类似结构的基于VAE的方法对2D Shapes数据集进行一个公平的比较,但也试着使用更大的结构,得到的是类似的结果(参见附录H)。如果结构搜索确实是重要的,这将是InfoGAN相对于FactorVAE和β-VAE的一个弱点,其都选择了更鲁棒的结构。在附录H中,我们检验了是否可以使用InfoWGAN-GP复制Chen et al.(2016)等人对MNIST的研究结果,验证了与InfoGAN相比,它使训练更加稳定,并结合InfoGAN和InfoWGAN-GP的进一步实证研究给出了实施细节。
我们现在显示三维形状数据的结果,这是一个更复杂的带有额外特性,如阴影和背景(天空)的三维场景的数据集。我们对β-VAE和FactorVAE训练1m次迭代。图10再次显示FactorVAE实现了更好的解耦,与VAE相比重构误差几乎没有增加。此外,对于平均解耦分数来说,FactorVAE和β-VAE相似,但是FactorVAE的重建误差较低:3515(γ= 36)和3570(β= 24):

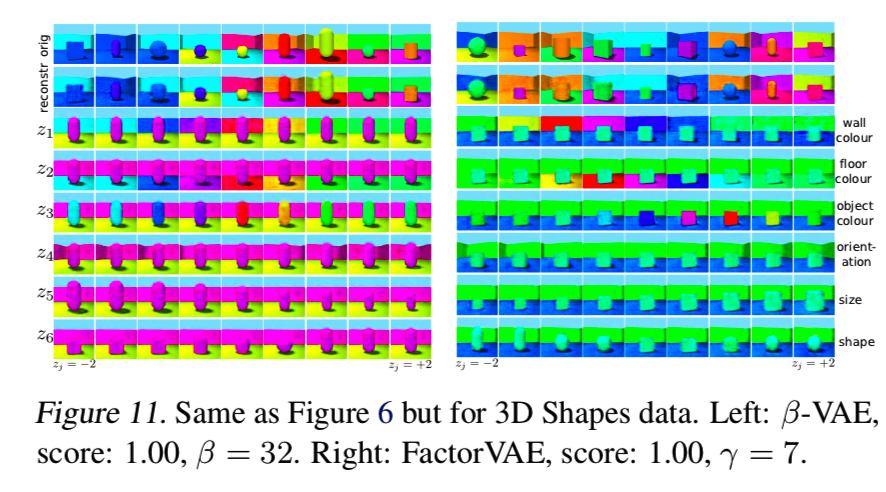
图11中的潜在遍历表明,这两个模型都能够在最佳情况下捕获变化的因素。然而,通过观察许多随机种子的潜在遍历,可以明显看出,这两个模型都难以理清形状和尺度的因素:
为了证明FactorVAE对于二维和三维形状也给出了一个有效的生成模型,我们在附录E中给出了对整个数据集的对数边际似然评估,以及生成模型的样本。
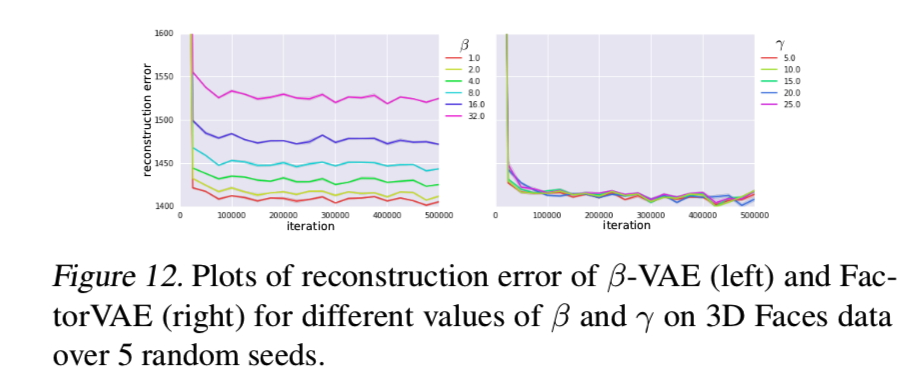
我们也显示了β-VAE和FactorVAE在带有未知的生成因素的实验数据集上的结果,即3D chairs,3D Faces,CelebA。注意,检查潜在遍历是这里唯一可能的评估方法。我们可以看到在图12(图38和39在附录I) 中:
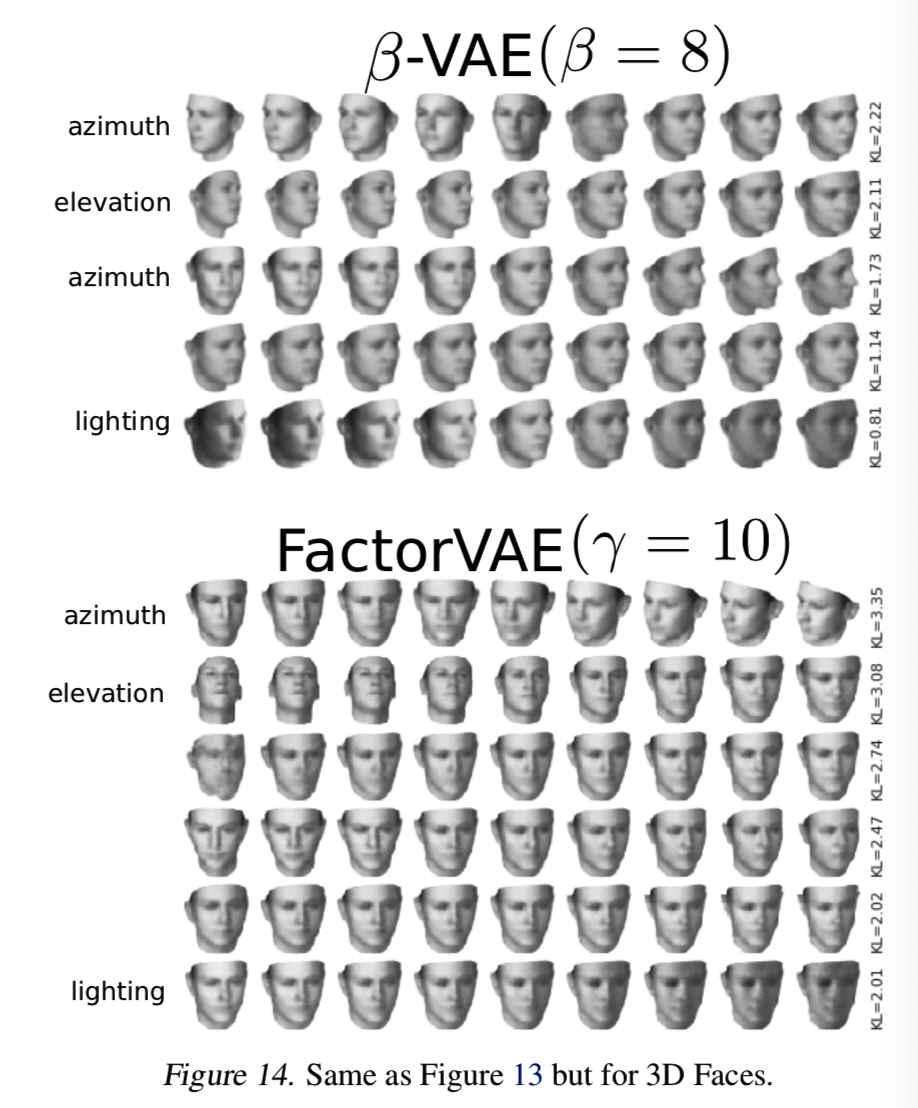
FactorVAE与β-VAE相比,重建误差更小,并能学习变量的合理因素,如图13、14和15所示的数据的潜在遍历:


不幸的是,正如第4节所解释的,潜在遍历对我们的方法的健壮性几乎没有什么帮助。
7. Conclusion and Discussion
我们介绍了FactorVAE方法,即一种用于解耦的新方法,能够比β-VAE在2D Shapes和3D Shapes数据集有着相同的重建质量时达到更好的解耦分数。此外,我们还确定了Higgins et al. (2016)常用的解耦度量方法的缺点,提出了一种概念更简单、不含超参数且避免了超参数失效模式的替代度量方法。最后,我们对基于VAE的方法和InfoGAN的一个更稳定的变体InfoWGAN-GP方法的解耦进行了实验评估,并确定了其相对于基于VAE方法的缺点。
我们的方法的一个限制是,低的总相关是必要的,但不足以解耦变量的独立因素。例如,如果除一个潜在维度外的所有维度都折叠到之前的维度,则TC将为0,但表示不会被解耦。我们的解耦度量方法还要求我们能够生成包含一个固定因子的样本,这可能并不总是可能的,例如,当我们的训练集不能覆盖所有可能的因子组合时。该指标也不适用于具有非独立变异因素的数据。
在未来的工作中,我们希望使用离散的潜在变量来建模离散变量的因素,并研究如何使用离散和连续的潜在变量来可靠地捕获离散和连续因素的组合。