补充知识:图像质量评价指标之 PSNR 和 SSIM(https://zhuanlan.zhihu.com/p/50757421)
https://www.github.com/richzhang/PerceptualSimilarity
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
Abstract
虽然对人类来说,快速评估两幅图像之间的感知相似性几乎毫不费力,但其潜在的过程被认为是相当复杂的。尽管如此,目前最广泛使用的感知指标,如PSNR和SSIM,都是简单、浅显的函数,无法解释人类感知的许多细微差别。最近,深度学习社区发现,在ImageNet分类上训练的VGG网络的特征作为图像合成的训练损失非常有用。但是这些所谓的“感知损失(perceptual loss)”有多感知呢?他们成功的关键因素是什么?为了回答这些问题,我们引入了一个新的人类感知相似度判断数据集。我们系统地评估不同架构和任务的深层特性,并将它们与经典的度量进行比较。我们发现深度特征在数据集上的表现比之前的所有指标都要好。更令人惊讶的是,这个结果并不局限于imagenet训练过的VGG特性,而是适用于不同的深层架构和监督级别(监督、自监督甚至非监督)。我们的结果表明,感知相似性是一种涌现的特性,在深度视觉表征中共享。
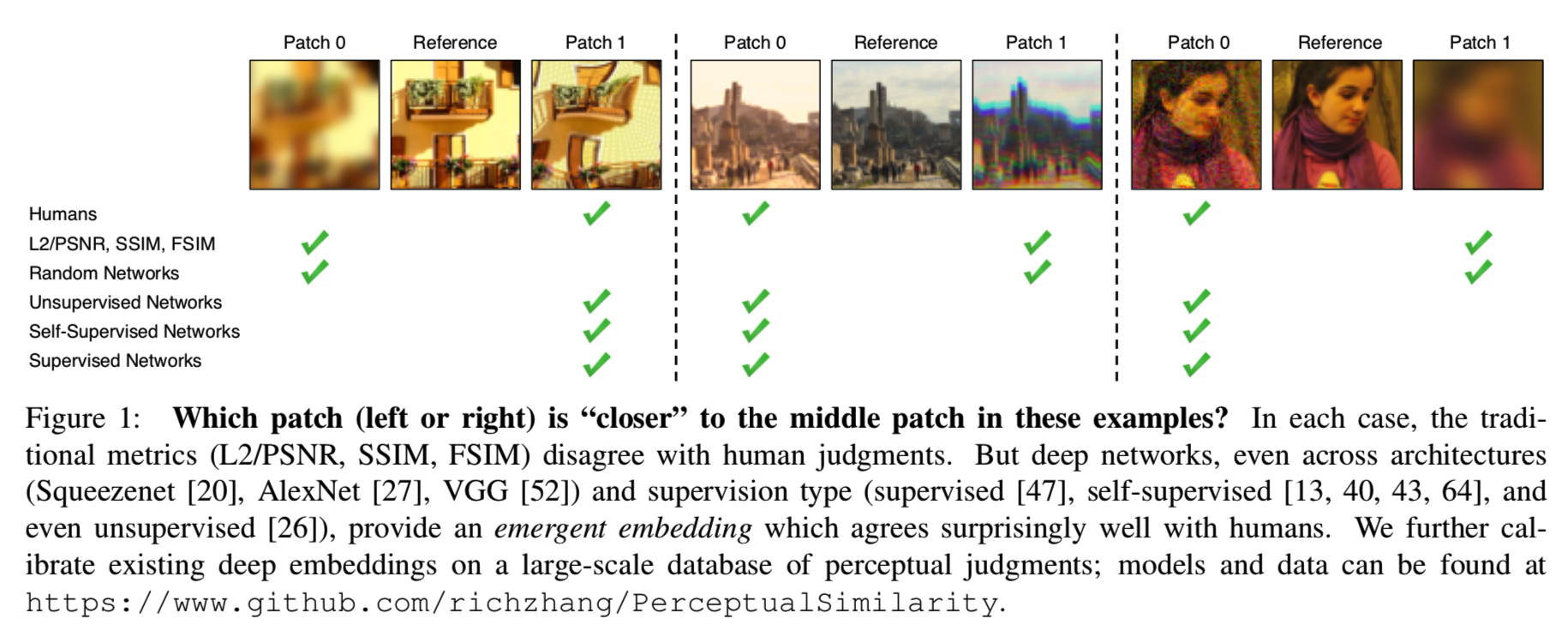
1. Motivation
比较数据项的能力可能是所有计算基础上最基本的操作。在计算机科学的许多领域中,它并不构成太大的困难:人们可以使用Hamming距离来比较二进制模式,编辑距离来比较文本文件,使用欧几里德距离来比较向量,等等。计算机视觉所面临的独特挑战是,即使是比较视觉模式这一看似简单的任务仍然是一个悬而未决的问题。视觉模式不仅是非常高维的和高度相关的,而且,视觉相似性的概念往往是主观的,旨在模仿人类的视觉感知。例如,在图像压缩中,目标是让人眼无法区分被压缩的图像与原始图像,而不考虑它们的像素表示可能非常不同这一事实。
经典的逐像素测量,如l2欧氏距离,通常用于回归问题,或相关的峰值信噪比(PSNR),对于评估像图像这样的结构化输出是不够的,因为它们假定像素独立性。一个著名的例子是模糊导致大的感知但小的l2变化。
我们真正想要的是一种“感知距离”,它可以衡量两幅图像在某种程度上有多相似,同时符合人类的判断。这个问题一直是一个长期的目标,也有许多感知驱动的距离指标被提出,如SSIM[58]、MSSIM[60]、FSIM[62]和HDR-VDP[34]。
然而,构建一个感知度量是一项挑战,因为人类对相似度的判断(1)依赖于高阶图像结构[58],(2)依赖于上下文[19,36,35],(3)可能实际上并不构成距离度量[56]。(2)的关键是有许多不同的“相似感”,我们可以同时记住:一个红色的圆更像一个红色的正方形还是一个蓝色的圆?直接将一个函数拟合到人类判断上可能是棘手的,因为判断(比较两幅图像之间的相似性)依赖于上下文和成对的性质。事实上,我们在本文中展示了这种方法不能推广的负面结果,即使是在包含许多类型的大规模数据集上训练时也是如此。
相反,有没有一种方法可以让我们在不经过直接训练的情况下学习感知相似性的概念?计算机视觉领域已经发现,深度卷积网络的内部激活,尽管是在高级图像分类任务上训练的,但作为更广泛的任务的表征空间,通常是非常有用的。例如,来自于VGG架构[52]的特性已经被用于诸如神经风格转移[17]、图像超分辨率[23]和条件图像合成等任务[14,8]。这些方法将VGG特征空间中的距离作为图像回归问题的“感知损失”来度量[23,14]。
但是这些“感知损失”在多大程度上与人类的视觉感知相对应呢?它们与传统的感知图像评估指标相比如何?网络架构重要吗?它是否必须在ImageNet分类任务上进行训练,或者其他任务也可以正常工作?这些网络需要接受训练吗?
在这篇论文中,我们在一个新的大规模的人类判断数据库上评估这些问题,并得出了几个惊人的结论。我们发现,为高级分类任务而训练的网络的内部激活,即使是跨网络架构[20,28,52],而且没有进一步的校准,确实符合人类感知判断。事实上,它们比常用的度量标准(如SSIM和FSIM)要好得多[58,62],后者不是为处理空间歧义是一个因素[49]的情况而设计的。此外,性能最好的自监督网络,包括BiGANs[13]、cross-channel prediction [64]和puzzle solving[40],即使没有人工标记训练数据的好处的情况下,在这个任务中也表现得很好。即使是使用stacked k-means[26]的简单的无监督网络初始化,也大大超过了经典的度量标准!这说明了这是一个跨网络,甚至跨架构和训练信号共享的emergent属性。然而,重要的是,拥有一些训练信号是至关重要的——一个随机初始化的网络会获得更低的性能。
我们的研究是基于一个新收集的感知相似数据集,该数据集使用大量的扭曲和真实的算法输出。它既包含传统的失真,如对比度和饱和度调整、噪声模式、滤波和空间扭曲操作,也包含基于CNN的算法输出,如自编码、去噪和着色,其由各种架构和损失产生。我们的数据集比以前的[45]数据集更加丰富和多样化。我们还收集了对超分辨率、帧插值和图像去模糊等任务的真实算法输出的判断,这是特别重要的,因为这些是感知度量的真实使用案例。我们表明,我们的数据可以用来“校准”现有的网络,通过学习一个简单的线性层次的激活,以更好地匹配低层次的人类判断。
我们的结果与这个假设是一致的,即感知相似性并不是一个单独的特殊功能,而是一种预测世界重要结构的视觉表征的结果。在语义预测任务中有效的表征同时也是欧氏距离对感知相似度判断具有高度预测性的表征。
我们的贡献如下:
- 我们引入了一个包含大小为484k的人类判断的大规模、高度变化的感知相似数据集。我们的数据集不仅包括参数化失真,还包括真实的算法输出。我们也在不同的感知测试中收集判断,即明显的差异(JND)。
- 我们展示了深层特征,在有监督、自我监督和无监督的目标上进行了类似的训练,对低层次感知相似度的建模效果惊人地好,优于以前广泛使用的指标。
- 我们证明了网络架构本身并不能说明性能:未经训练的网络可以获得更低的性能。
- 通过我们的数据,我们可以通过“校准”预先训练好的网络的特征响应来提高性能。
Prior work on datasets.为了评价现有的相似性度量,提出了一些数据集。一些最受欢迎的是LIVE[51],TID2008 [46], CSIQ[29],和TID2013[45]数据集。这些数据集被用作全参考图像质量评估(FR-IQA)数据集,并作为事实上的基线用于开发和评估相似度指标。一个相关的工作是无参考图像质量评估(NR-IQA),如AVA[38]和LIVE In the Wild[18]。这些数据集自己调查单个图像的“质量”,没有参考图像。我们收集了一个新的数据集来补充这些:它包含了大量的扭曲,包括一些来自更新的、深度网络的输出,以及几何扭曲。我们的数据集中于感知相似度,而不是质量评估。此外,在自然环境下,它是通过不同的实验设计在小块上而不是完整的图像上收集的(更多细节见Sec 2)。
Prior work on deep networks and human judgments. 最近,DNNs的进展已经推动了在视觉相似度和图像质量评估方面的应用研究。Kim和Lee[25]使用CNN通过对低水平差异的训练来预测视觉相似性。Talebi和Milanfar的并发工作[54,55]是在NR-IQA背景下为图像美学训练了一个深度网络。Gao等人[16]和Amirshahi等人[3]提出了一些技术,包括利用带有额外的多尺度后处理的深层网络(分别是VGG和AlexNet)的内部激活。在这项工作中,我们在一个新的、大规模的、高度变化的数据集上跨不同架构、训练信号进行了更深入的研究。
最近,Berardino等人[6]在感知相似度上对网络进行训练,重要的是,评估了深度网络在一项单独任务上进行预测的能力——预测最明显和最不明显的扭曲方向。同样,我们不仅评估参数化失真的图像块的相似性,还测试对真实算法的泛化,以及对单独感知任务的泛化——只是用于显著差异。
2. Berkeley-Adobe Perceptual Patch Similarity (BAPPS) Dataset
为了评估不同感知指标的性能,我们使用两种方法收集了大规模高度不同的感知判断数据集。我们的主要数据收集采用了两种不同的可选择的forced choice (2AFC)测试,即两种扭曲中哪一种更类似于参考。第二个实验验证了这一点,在这个实验中,我们执行了一个显著差异(JND)测试,该测试询问两个patches——一个参考和一个扭曲——是相同还是不同。这些判断被收集在一个广阔的扭曲和真实的算法输出空间。
2.1. Distortions
我们创建了一组由在输入patches上执行的常见操作组成的“传统”扭曲方法,如表2(左)所示。通常,我们使用光度失真、随机噪声、模糊、空间移位和破坏以及压缩工件。我们在图2中展示了我们传统扭曲的定性例子。
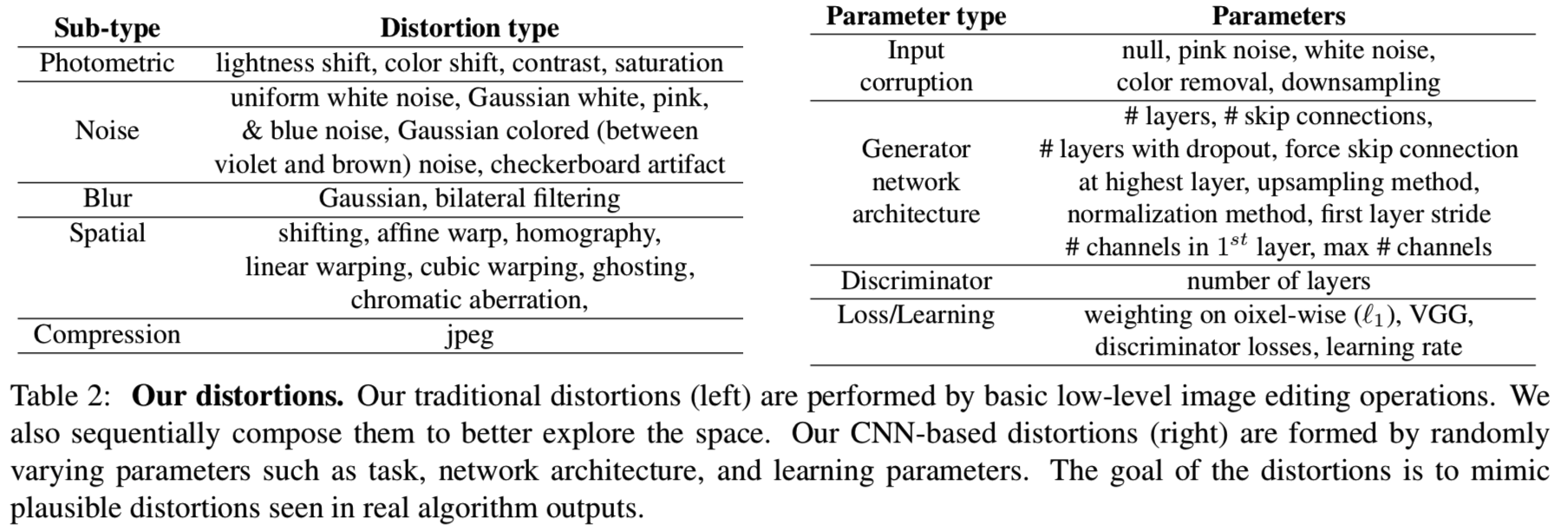
每个扰动的严重程度都是可参数化的——例如,对于高斯模糊,核宽决定了对输入图像的破坏程度。我们还按顺序组合成对的扭曲方法,以增加可能的扭曲的整体空间。总共,我们有20个扭曲方法以及308个序列组合成的扭曲方法

CNN-based distortions. 为了更接近地模拟基于深度学习的方法所产生的伪影空间,我们创建了一组由神经网络创建的扭曲方法。我们通过探索各种任务、架构和损失来模拟可能的算法输出,如表2(右)所示。这些任务包括自动编码、去噪、着色和超分辨率。所有这些任务都可以通过对输入应用适当的损坏来实现。我们总共生成了96个“去噪自动编码器”,并使用这些作为基于CNN的扭曲函数。我们在1.3M ImageNet数据集[47]上训练每个网络1个epoch。每个网络的目标不是解决任务本身,而是探索影响基于深度学习方法输出的常见问题。
Distorted image patches from real algorithms. 对一种图像评估算法的真正检验是对真实问题和真实算法的检验。我们利用这些输出来收集感性判断。真实算法上的数据更为有限,因为每个应用程序都有自己独特的属性。例如,不同的着色方法不会表现出很大的结构变化,但容易出现色漏、色变等效果。另一方面,超分辨率将不会有颜色模糊,但可能看到从算法到算法的更大的结构变化。
Superresolution. 我们对2017年NTIRE workshop[2]的结果进行评估。我们使用来自workshop的3条track- 使用x2,x3,x4的上采样率,使用“unknown”下采样来创建输入图像。每条track都有大约20个算法提交。我们还评估了几种其他的方法,包括bicubic上采样方法和四种性能最好的深度超分辨率方法[24,59,31,48]。一种常见的表示超分辨率结果的定性方法是放大到特定的patch并比较他们的差异。因此,我们从Div2K[2]数据集(ground truth高分辨率图像)的图像的随机位置中随机采样64×64大小的triplets数据,同时伴随着两个算法输出。
Frame interpolation.在Davis Middleburry数据集[50]上,我们对来自不同帧插值算法的patch进行采样,包括三种不同的基于流的插值[33]、基于cnn的插值[39]和基于相位的插值[37]。由于帧插值产生的伪影可能在不同的尺度下发生,因此我们在采样一个patch triplet之前对图像进行随机缩放。
Video deblurring.我们从视频去模糊数据集[53]中采样,以及从Photoshop Shake Reduction, Weighted Fourier Aggregation[11]和三种不同的深度视频去模糊方法[53]中输出的去模糊结果。
Colorization.我们在着色任务中对来自ImageNet数据集[47]的图像使用随机比例采样patch。算法来自pix2pix [22], Larsson等人[30],以及Zhang等人[63]方法的变体。
2.2. Psychophysical Similarity Measurements
2AFC similarity judgments.我们随机选择一个图像patch x并应用两种扭曲方法来产生patch x0,x1。然后我们询问一个人哪张图更接近原始patch x,并记录下回答 h∈{0,1}。平均而言,人们在每次判断上花了大约3秒。设![]() 表示我们的patch triplets数据集(x, x0, x1, h)。
表示我们的patch triplets数据集(x, x0, x1, h)。
(这个方法其实就是将原图中一个patch进行不同种类的变换(这里有常规算法的变换和基于CNN的变换),然后让人来判断变换后的结果中哪一个更为接近原来的patch)
我们的数据集和以前的数据集的比较如表1所示。

以前的数据集中于对少数图像和失真类型收集大量的人类判断。例如,最大的数据集TID2013[45]对3000个扭曲图(来自25个输入图像,24种扭曲类型,每个在5个级别采样,25*24*5=3000)有500k的判断。我们提供了一个补充的数据集,相反的是其专注于大量的扭曲类型。另外,我们对大量的64×64 patch进行判断,而不是对少量的图像进行判断。有三个原因。首先,全图像的空间非常大,这使得用判断覆盖区域的合理部分变得非常困难(即使是64×64的彩色块也代表了一个难以处理的12k维空间)。其次,通过选择较小的patch大小,我们将重点放在较低级别的相似方面,以减轻高级语义[36]对不同“相似方面”的影响。最后,现代图像合成方法对基于patch的损失(实现为卷积)的深度网络进行训练[8,21]。我们的数据集包含超过161k个patch,这些patch来自于用于训练的MIT-Adobe 5k数据集[7](5000张未压缩图像),以及用于验证的RAISE1k数据集[10]。
为了实现大规模收集,我们的数据是在Amazon Mechanical Turk的“in-the-wild”上收集的,而不是在受控的实验室设置下。Crump等人的[9]表明,尽管AMT不能控制所有的环境因素,但它可以可靠地用于复制许多心理物理学研究。我们要求每个例子在我们的“训练”集合中有2个判断(即一张图和另外两个扭曲图做对比得到判断两者是否相同的两个判断结果),在我们的“val”集合中有5个判断。要求更少的判断能让我们探索更大的一组图像patch和扭曲。我们加入由具有明显变形的小patch对组成的哨兵,例如大量的高斯噪声与少量的高斯噪声。大约90%的Turkers能够正确的通过93%的哨兵(15个中的14个),这表明他们理解任务并且集中注意力。我们选择使用比之前的数据集更多的扭曲。
Just noticeable differences (JND).2AFC任务的一个潜在缺点是,它是“认知可渗透的”,也就是说,参与者可以有意识地选择在完成任务[36]时,他们会选择关注哪些相似方面,这将主观性引入到判断中。为了验证这些判断实际上反映了一些客观和有意义的东西,我们还收集了用户对“just noticeable differences”(JNDs)的判断。我们展示一幅参考图像,然后是一幅随机扭曲的图像,然后问一个人这两幅图像是相同的还是不同的(类似训练网络去分类)。这两个图像patch分别显示1秒,间隔250ms。两个看起来相似的图像很容易混淆,一个好的感知度量将能够从最易混淆到最不容易混淆对排序。像这样的JND测试可能被认为不那么主观,因为每个判断都有一个正确的答案,而且参与者被假定知道正确的行为需要什么。在我们的传统验证集和基于CNN的验证集中,我们为每个4.8k个patch收集了3个JND观测值。每个目标图被展示了160对,带有40个哨兵(32个相同的,8个带有大的高斯噪声失真)。我们还提供了一个10对的短期训练,其中包括4对“相同”的,1对明显不同的,和5对“不同”的,由我们的扭曲方法产生的。我们这样做是为了引导用户期望大约40%的patch对是相同的。事实上,36.4%的配对被标记为“相同”(包括70.4%的哨兵和27.9%的测试对)。
这个方法其实就是拿一张图和基于该图变换的图来找人来进行判断,看这两张图是否是一样的
3. Deep Feature Spaces
我们评估不同网络中的特征距离。对于给定的卷积层,我们计算余弦距离(在channel维度)和网络的空间维度和层的平均。我们还将讨论如何在数据上优化现有网络。
网络架构。我们评估了SqueezeNet[20]、AlexNet[28]和VGG[52]架构。我们使用来自VGG网络的5个conv层,这已经成为图像生成任务的事实标准[17,14,8]。我们还将其与较浅的AlexNet网络进行比较,后者可能更接近人类视觉皮层的结构[61]。我们使用了[27]中的conv1-conv5层。最后,SqueezeNet架构被设计成非常轻量(2.8 MB)的大小,具有与AlexNet相似的分类性能。我们使用第一个conv层和一些随后的“fire”模块。
我们还评估了自监督的方法,包括puzzle-solving [40], cross-channel prediction [63, 64], learning from video [43]和generative modeling [13]。我们使用来自这些和其他方法的公开可利用的网络,其使用了AlexNet[28]的变体。
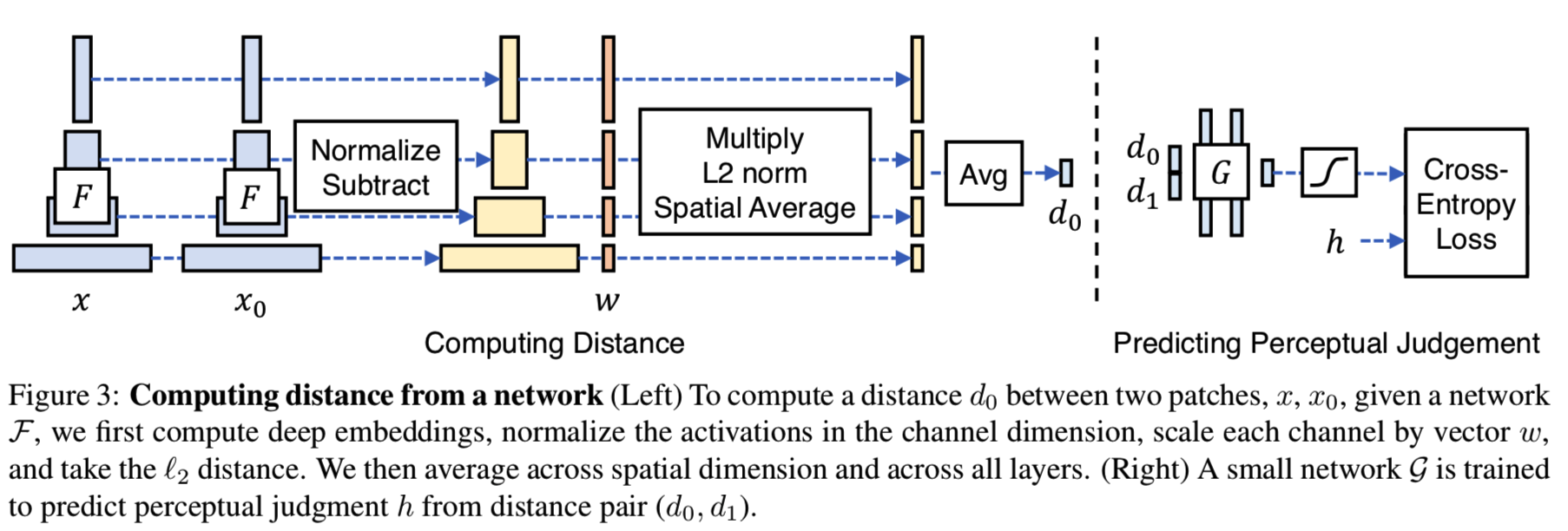
Network activations to distance. 图3和等式1说明了如何在网络![]() 中获得参考和扭曲patches x、x0之间的距离。
中获得参考和扭曲patches x、x0之间的距离。
(其实这个实现很简单,就是用不同图的特征来计算距离,然后再用距离判断那个相似度更高。其他部分都是在讲作者如何说明这个方法的效果是比其他方法效果好的,并说明使用什么样的网络效果更好等)
从L层抽取特征stack,然后在channel维度unit-normalize,然后将结果标记为层l的![]()
![]() 。然后通过向量
。然后通过向量![]() 在channel维度缩放激活,并计算L2距离。最后,在空间上平均并基于channel求和。注意使用
在channel维度缩放激活,并计算L2距离。最后,在空间上平均并基于channel求和。注意使用![]() 等价于计算cosine距离:
等价于计算cosine距离:
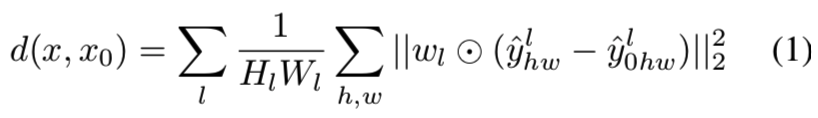
Training on our data. 我们考虑几个不同的用于训练我们的感知判断的变体:lin, tune,和scratch。对于lin的配置,我们保持预先训练好的网络权值![]() 是固定的,并在上面学习线性权值w(即图3中的w,橙色)。这构成了现有特征空间中几个参数的“感知校准”。例如VGG网络,学习了1472个参数。对于tune配置,我们从一个预先训练好的分类模型进行初始化,并允许对网络
是固定的,并在上面学习线性权值w(即图3中的w,橙色)。这构成了现有特征空间中几个参数的“感知校准”。例如VGG网络,学习了1472个参数。对于tune配置,我们从一个预先训练好的分类模型进行初始化,并允许对网络![]() 的所有权重进行微调。最后,对于scratch,我们从随机高斯权值初始化网络,并完全根据我们的判断训练它。总的来说,我们把这些称为我们提出的Learned Perceptual Image Patch Similarity (LPIPS) 度量的变体。我们在图3(右)中说明了训练损失函数,并在附录中进行了进一步的描述。
的所有权重进行微调。最后,对于scratch,我们从随机高斯权值初始化网络,并完全根据我们的判断训练它。总的来说,我们把这些称为我们提出的Learned Perceptual Image Patch Similarity (LPIPS) 度量的变体。我们在图3(右)中说明了训练损失函数,并在附录中进行了进一步的描述。
附录补充图3(右):
我们在图3(右)中说明了训练网络的损失函数,并在补充材料中进一步描述。给定两个距离,(d0, d1),我们培养一个小网络G映射到一个分数hˆ∈(0,1)。网络结构上使用两个32-channels的FC-ReLU层,其次是一层1-channel 的FC层和sigmoid。我们的最终损失函数如方程2所示:

在初步的实验中,我们还尝试了排序损失,它试图使patch对d(x, x0)和d(x, x1)之间的边界保持不变。我们发现,使用一个学习过的网络,而不是在所有情况下强制执行相同的边界,效果更好。
在这里,我们提供了一些关于训练在扭曲图像上的我们的网络哦的模型训练的额外细节。我们在初始学习速率为10−4时训练5个epoch,然后是5个带有线性衰减的epoch,batch size为50。每个训练patch对进行2次判断,并将判断结果组在一起。例如,如果将这两个判断拆分,那么分类目标(图3中的h)将被设置为0.5。我们在线性层w上执行非负权值,因为在某个特征上较大的距离不应该导致两个patch在距离度量上变得更近。这是通过在每次迭代中将权重投射到约束集来实现的。换句话说,我们检查任何负权值,并使它们为0。本项目使用PyTorch[42]实现。
4. Experiments
在验证集中的结果展示在图4。
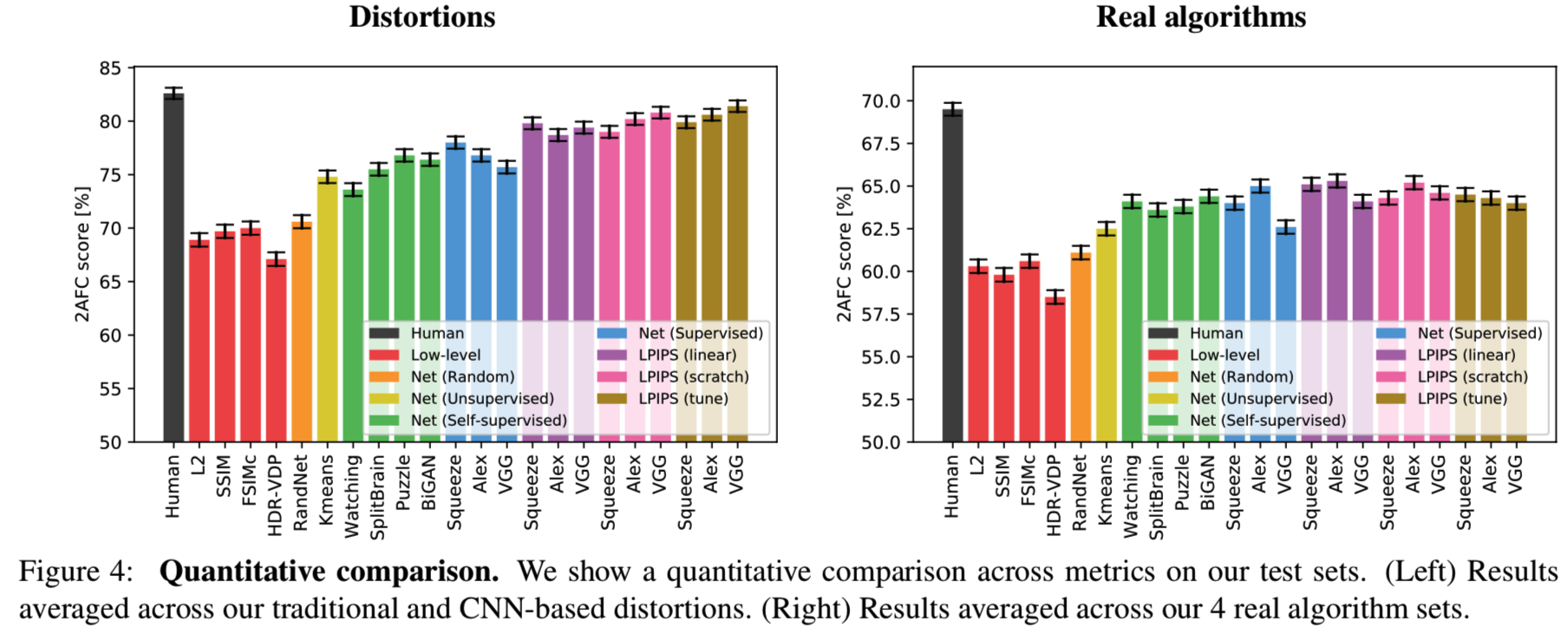
我们首先评估我们的指标和网络的工作情况。所有验证集对每个三元组包含5对判断。因为这是一个固有的有噪声的过程,我们计算一个算法与所有的判断的一致性。例如,如果x0有4个偏好,x1有1个偏好,那么预测更受欢迎的选择x0的算法将获得80%的credit。如果一个给定的例子在一个方向得分为p,而在另一个方向得分为1−p,那么一个人的预期得分为p2 +(1−p)2。
(如果人类选择了分数为{p,1−p}的patch {x1,x0},那么oracle的理论最大值为max(p, 1−p)。然而,人类的性能较低。如果agent以概率{q,1−q}选择它们,那么agent将在预期上同意qp +(1−q)(1−p)人。对于人类agent来说, q = p,所以预期的人类得分是p2 +(1−p)2。)
4.1. Evaluations
How well do low-level metrics and classification net- works perform? 图4显示了各种低级度量(红色显示)、深度网络和人类天花板(黑色显示)的性能。图4(左)中的分数是2个扭曲测试集(传统的+基于cnn的)的平均值,图4(右)中的分数是4个真实算法基准(超分辨率、帧插值、视频去模糊、彩色化)的平均值。每个测试集中的所有分数都显示在附录中。在所有6个测试集中,人类的一致性平均值为73.9%。有趣的是,即使模型大小不同——SqueezeNet (2.8 MB)、AlexNet (9.1 MB)和VGG (58.9 MB)(只有convolutional layer被计算在内),被监督的网络之间的执行效率也差不多,分别为68.6%、68.9%和67.0%。它们的表现都优于传统指标l2、SSIM和FSIM,分别为63.2%、63.1%和63.8%。尽管SSIM十分常用,但它不是为几何扭曲是一个大的影响因素[49]的这种情况设计的。
Does the network have to be trained on classification? 在图4中,我们展示了模型在各种无监督和自监督任务中的性能(绿色显示)—— 其中包含使用BiGANs[13]进行生成建模、BiGANs [13], solving puzzles [40], cross-channel prediction [64]和segmenting foreground objects from video [43]。这些自我监督的任务的执行与分类网络是一样的。这表明,跨大频谱的任务可以诱导出能很好地转移到感知距离的表征。此外,stacked k-means方法[26](用黄色显示)的性能优于低级度量标准。用橙色表示的随机网络,权值来自高斯分布,并不能产生很大的改进。这表明,网络结构的组合,以及在数据更密集的方向上的定向过滤器,可以更好地关联感知判断。
在表5中,我们使用总结在[64]的结果,包括额外的自我监督方法[1,44,12,57,63,41],探索了我们的感知任务与PASCAL数据集[15]上的语义任务的关联程度。我们通过不同的方法计算每个任务(感知或语义)之间的相关系数。我们的2AFC扭曲偏好任务与分类和检测的相关性分别为0.640和0.363。有趣的是,该值与分类任务和检测任务之间的相关性(0.429)结果相似,尽管两者都被认为是“高级”语义任务,而我们的感知任务是“低级”的。
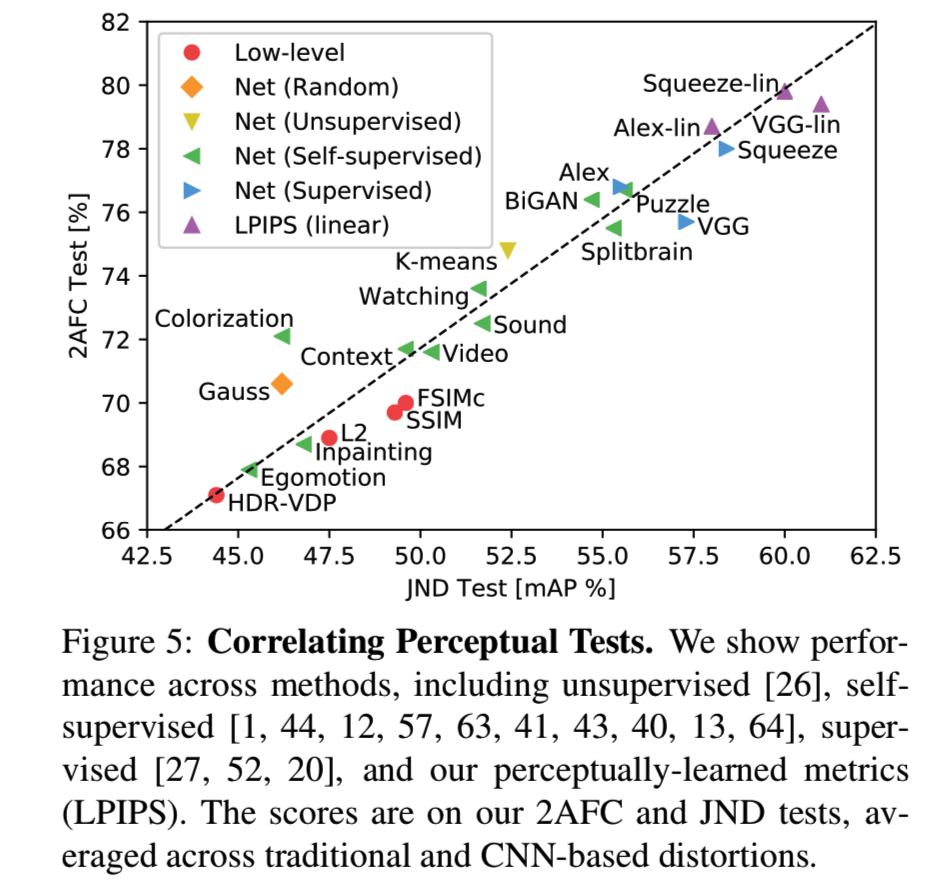
Do metrics correlate across different perceptual tasks? 我们测试了2AFC扭曲偏好测试的训练是否与另一个知觉任务JND测试相对应。我们根据给定的度量对patch进行升序排序,并在基于cnn的扭曲中计算精确度和召回 —— 对于一个好的度量,靠近的patch更有可能因为是相同的而被混淆。我们计算曲线下的面积,也就是mAP[15]。2AFC扭曲偏好测试在对不同扭曲类型的结果进行平均时,与JND: ρ = .928有很高的相关性。图5显示了不同的方法在每个感知测试中是如何执行的。这表明2AFC泛化到另一个知觉测试,并给我们关于人类判断的信号。
Can we train a metric on traditional and CNN-based distortions? 在图4中,我们使用lin、scratch和tune配置显示性能,分别以紫色、粉色和棕色显示。在验证传统的和基于cnn的扭曲时(图4(a)),我们看到了改进。允许网络通过所有方式进行调优(棕色)比简单地学习线性权值(紫色)或从头开始训练(粉色)获得更高的性能。高容量网络VGG的性能也优于低容量SqueezeNet和AlexNet架构。这些结果证实了网络确实可以从感知判断中学习。
Does training on traditional and CNN-based distortions transfer to real-world scenarios? 我们更感兴趣的是如何将性能推广到实际算法中,如图4(b)所示。SqueezeNet、AlexNet和VGG架构的初始值分别为64.0%、65.0%和62.6%。学习线性分类器(紫色)可以提高所有网络的性能。在3个网络和4个实际算法任务中,12个任务中有11个得分得到了提高,这表明使用我们的数据对已有的表现进行“校准”激活是实现性能小幅提升的一种安全方法(分别为1.1%、0.3%和1.5%)。从头训练一个网络(粉色)会使AlexNet的性能略低,而VGG的性能略高于线性校准。然而,这些仍然比低级度量要好。这表明,我们所表示的扭曲确实投射到我们判断真实算法的测试任务上。
有趣的是,从一个预先训练过的网络开始,然后在整个过程中进行调优,会降低传输性能。这是一个有趣的负面结果,因为直接训练一个低层次的感知任务并不一定像转移一个在高级任务上训练的表征那样有效。
Where do deep metrics and low-level metrics disagree? 在图11中,我们对一种深度方法BiGANs[13]和一种表示传统感知方法SSIM[58]进行了定性比较。BiGAN觉得远而SSIM觉得近的对通常都有一些模糊。对比SSIM,BiGAN倾向于感知更小扭曲的相关噪声模式。

5. Conclusions
我们的结果表明,被训练来解决具有挑战性的视觉预测和建模任务的网络,最终会学习到一个与感知判断很相关的世界的表征。最近在表示学习的文献中也出现了类似的情况:在自我监督和无监督目标上训练的网络,最终学习的表示在语义任务[12]中也是有效的。有趣的是,最近在神经科学上的发现也提出了同样的观点:在计算机视觉任务上训练的表征最终也成为猕猴视觉皮层中神经活动的有效模型[61]。此外(粗略地说),计算机视觉任务的表现越强,作为大脑皮层活动模型的表现就越强。我们的论文也有类似的发现:特征集在分类检测上越强,作为感知相似度判断模型的作用就越强,如表4所示。

总之,这些结果表明,好的特征就是好的特征。擅长语义任务的特征也擅长自我监督和非监督任务,并为人类感知行为和猕猴神经活动提供了良好的模型。最后一点与视觉认知[4]的“理性分析”解释一致,认为生物感知的特质是理性主体试图解决自然任务的结果。进一步完善这一点的真实性是未来研究的一个重要问题。