https://genforce.github.io/mganprior/
Image Processing Using Multi-Code GAN Prior
Abstract
尽管生成对抗网络(GANs)在图像合成方面取得了成功,但将经过训练的GAN模型应用于真实图像处理仍然具有挑战性。以前的方法通常通过反向传播或学习额外的编码器将目标图像反向回潜在空间。但两种方法的重建效果都不理想。在这项工作中,我们提出了一种新的方法,称为mGANprior,将训练有素的GANs作为有效的在各种图像处理任务的先验。特别地,我们利用多个潜码在生成器的某个中间层生成多个特征图,然后将它们组合成具有自适应channels重要性的特征图,以恢复输入图像。这种潜在空间的过参数化显著提高了图像重建质量,优于现有的竞争对手。得到的高保真图像重建使经过训练的GAN模型能够作为许多真实应用,如图像着色、超分辨率、图像修补和语义操作的prior操作。我们进一步分析了GAN模型学到的基于层的表征的属性,并阐明了每一层能够表示什么知识
1. Introduction
最近,生成式对抗网络(GANs)[16]通过提高合成质量[23,8,24]和稳定训练过程[1,7,17],提高了图像生成。GANs具有生成高质量图像的能力,这使得GANs适用于许多图像处理任务,如语义人脸编辑[27,36]、超分辨率[28,42]、图像到图像的转换[53,11,31]等。然而,大多数基于GAN的方法需要针对特定任务设计特殊的网络结构[27,53]或损失函数[36,28],这限制了它们的泛化能力。另一方面,大型GAN模型,如StyleGAN[24]和BigGAN[8],经过数百万张不同的图像训练后,可以合成非常逼真的图像。他们的神经表征被显示包含不同层次的语义基础上的观察数据[21,15,35,44]。在进行真实图像处理之前重用这些模型可能会带来更广泛的应用,但还需要更多的探索。
实现这一目标的主要挑战是,标准GAN模型最初设计用于从随机噪声合成图像,因此将真实图像用于任何后处理操作。一种常见的做法是将给定的图像反转回潜在的代码,以便生成器可以重新构建它。这样,反向的代码就可以用于进一步的处理。为了逆转生成过程,现有的方法分为两种类型。一种是通过反向传播将重构误差最小化,直接优化潜在代码[30,12,32]。另一种方法是训练额外的编码器学习从图像空间到潜在空间的映射[34,52,6,5]。然而,这两种方法的重建效果都不理想,特别是当给定的图像具有高分辨率时。因此,重建的图像质量较差,无法用于图像处理任务。
原则上,不可能用一个潜码来恢复任意真实图像的每一个细节,否则,我们就有了一种无与伦比的图像压缩方法。换句话说,潜码的表达能力是有限的,因为它的有限维数。因此,为了忠实地恢复目标图像,我们提出在生成器的某一中间层使用多个潜码并生成相应的特征图。利用多重潜码,使生成器能够利用在深层生成表示中学习到的所有可能的组合知识恢复目标图像。实验表明,该方法显著提高了图像重建质量。更重要的是,我们的方法能够更好地重建输入图像,通过使用预先训练好的GAN模型,不需要再训练或修改,简化了各种真实图像处理应用程序,如图1所示。我们的工作总结如下:
- 本文提出了一种基于多重潜码和自适应channels重要性的GAN反演方法,该方法是一种有效的GAN反演方法。该方法忠实地重建了给定的真实图像,优于现有的方法。
- 我们将提出的mGANprior应用于一系列真实世界的应用,如图像着色、超分辨率、图像修补、语义处理等,展示了其在真实图像处理中的潜力。
- 我们进一步分析了GAN生成器中不同层的内部表示方法,将每个层的反向潜码的特征分别组合在一起。

2.Related Work
GAN Inversion. GAN反演的任务是使用预先训练的GAN模型将给定的图像反转回潜在代码。其作为将GANs应用于实际应用的重要步骤,近年来受到越来越多的关注。为了使GAN中的固定生成器反转,现有方法要么基于梯度下降优化潜码[30,12,32],要么学习额外的编码器将图像空间投影回潜码空间[34,52,6,5]。Bau等人[3]提出使用编码器提供更好的初始化优化。也有一些模型在训练阶段考虑了可逆性[14,13,26]。然而,上述方法都只考虑使用单个潜码对输入图像进行恢复,重构质量远不理想,特别是当测试图像与训练数据之间存在较大的域间隙时。这是因为输入图像可能不存在于生成器的合成空间中,在这种情况下,使用单个潜在代码的完美反演并不存在。相反,我们提出增加潜在编码的数量,无论目标图像是域内还是域外,都能显著提高反演质量。
Image Processing with GANs. 由于GANs具有很强的合成真实感图像的能力,因此在真实图像处理中得到了广泛的应用。这些应用包括图像去噪[9,25]、图像修补[45,47]、超分辨率[28,42]、图像着色[38,20]、风格混合[19,10]、语义图像处理[41,29]等。而目前基于GAN的模型通常是针对特定任务设计的,具有专门的架构[19,41]或损失函数[28, 10],还有以一幅图像作为输入,另一幅图像作为监督进行配对数据训练[45,20]。与此不同的是,我们的方法可以重用包含在经过良好训练的GAN模型中的知识,并可以使用一个GAN模型作为上述所有任务的先验,而无需重新训练或修改。值得注意的是,我们的方法可以比现有的专门为某项任务而训练的基于GAN的方法取得类似甚至更好的结果。
Deep Model Prior. 一般来说,深层卷积模型令人印象深刻的性能可以归因于它从大规模数据中捕获统计信息的能力。该先验可反方向用于图像生成和图像重建[40,39,2]。Upchurch等人[40]倒置了一个判别模型,从深度卷积特征出发,实现了图像的语义变换。Ulyanov等人[39]用U-Net结构对目标图像进行了重构,表明生成器网络的结构足以在任何学习之前捕获底层图像的统计信息。Athar等人[2]学习了一个通用图像先验用于各种图像恢复任务。一些工作在理论上探索了深度生成模型所提供的先验[32,18],但在真实图像处理之前使用GAN的结果仍然不令人满意。最近的一项工作[3]在语义照片处理之前应用了生成图像,但它只能编辑输入图像的部分区域,不能应用于着色或超分辨率等其他任务。这是因为它只是将GAN模型反转到某个中间特征空间,而不是最早的隐藏空间。而我们的方法将整个生成过程反向,即从图像空间到最初的潜在空间,支持更灵活的图像处理任务。
3. Multi-Code GAN Prior
GAN的一个良好训练的生成器G(.)能够通过采样来自潜在空间Z的编码合成高质量的图像。给定一个目标图像x,GAN反演任务旨在通过寻找合适的编码去恢复x来反转生成过程。其公式为:

但是,由于该优化问题的高度非凸性,以往的方法不能通过优化单个潜在代码来理想地重构任意图像。为此,我们提出使用多个潜码,并构造相应的具有自适应channels重要性的中间特征图,如图2所示。
3.1. GAN Inversion with Multiple Latent Codes
单个潜在代码的表现力可能不足以恢复特定图像的所有细节。那么,使用N个潜码{zn}n=1N,每个潜码都可以帮助重构目标图像的一些子区域怎么样?下面,我们将介绍如何利用多个潜在代码进行GAN反演。
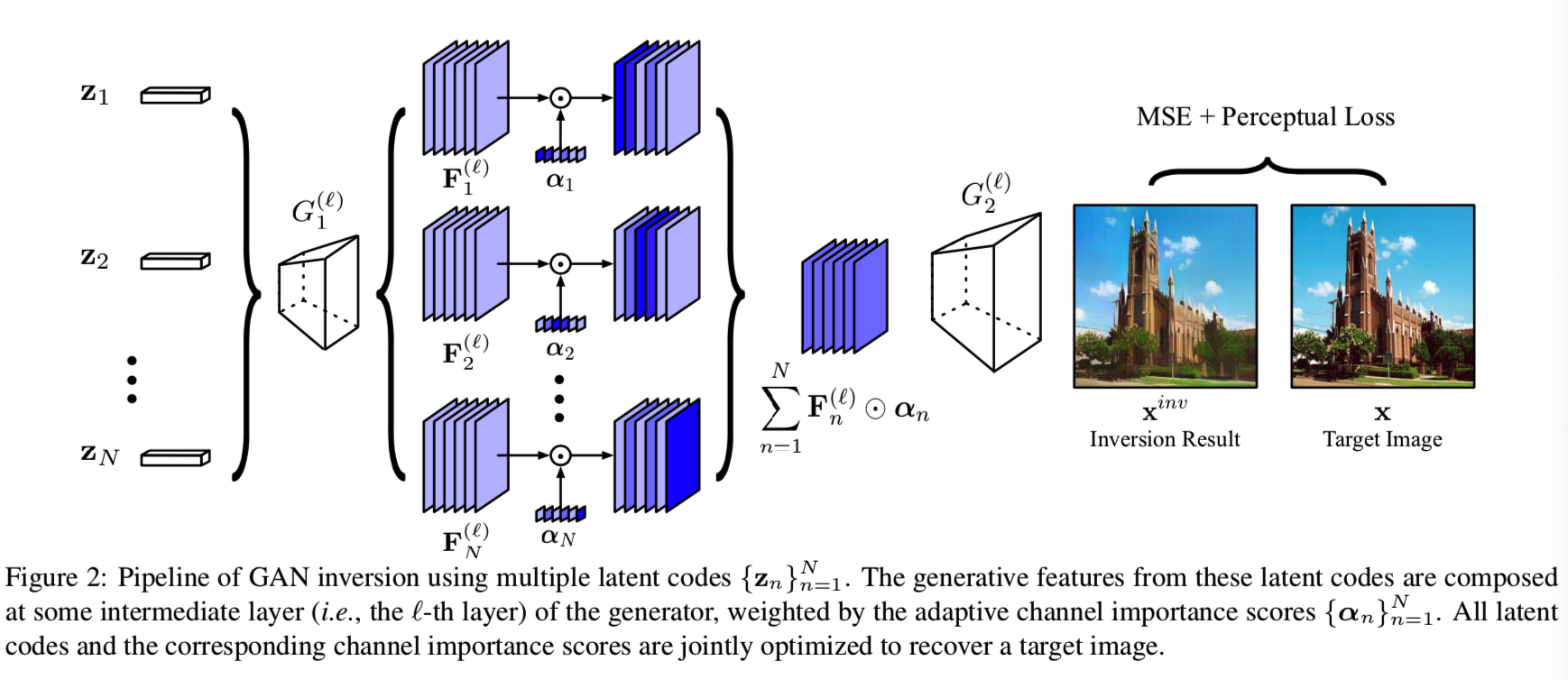
Feature Composition. 引入多重潜码后的一个关键难点是如何将其整合到生成过程中。一个简单的解决方案是将每个来自图像空间X的zn生成的图像融合。然而,X本身并不是一个线性空间,将合成的图像线性组合并不能保证生成有意义的图像,更不用说恢复细节输入。最近的一项工作[5]指出从图像空间到某个中间特征空间要比到潜在空间去反演生成模型容易得多。在此基础上,我们提出了通过构造潜码的中间特征映射来组合潜码的方法。更具体来说,就是生成器G(.)会被分成两个子网络,即G1(l)(.)和G2(l)(.)。这里l是中间层的索引,用来实现特征组合。对于任意zn,使用这样的分离,我们能够抽取到对应的空间特征![]() 用于进一步的组合。
用于进一步的组合。
Adaptive Channel Importance. 回想一下,我们希望每个zn都能恢复目标图像的某些特定区域。Bau等人[4]观察到GAN中生成器的不同单元(即通道)负责生成不同的视觉概念,如物体和纹理。在此基础上,我们为每个zn引入了自适应信道重要度αn,以帮助它们根据不同的语义进行对齐。在这里,![]() 是一个C维向量,C是G(.)在第
是一个C维向量,C是G(.)在第 层的channels数量。我们希望每一个αn都能表示对应特征映射
层的channels数量。我们希望每一个αn都能表示对应特征映射![]() 通道的重要程度。使用该组合方法,重建图像的生成为:
通道的重要程度。使用该组合方法,重建图像的生成为:
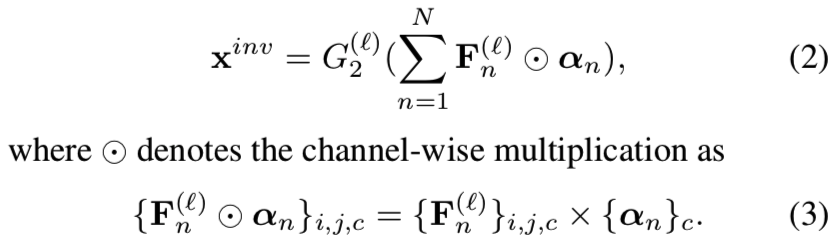
这里i和j表示空间位置,c表示channel索引
Optimization Objective. 在引入特征组合技术和自适应信道重要性对多个潜码进行集成后,总共有2N组参数需要优化。因此,我们将式(1)重新表示为
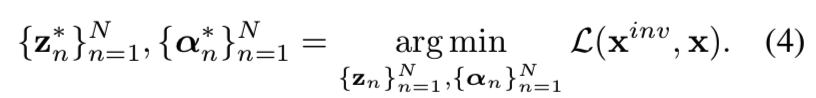
为了提高重构质量,我们通过利用低层次和高层次的信息来定义目标函数。具体来说,我们使用像素级重建误差以及从两幅图像中提取的感知特征[22]之间的l1距离。因此,目标函数为:
![]()
式中,Φ(.)为感知特征提取器。利用梯度下降算法找出最优潜码以及相应的信道重要度分数。
3.2. Multi-Code GAN Prior for Image Processing
反演后,我们将重建结果作为各种图像处理任务的多码GAN先验。每个任务都需要一个图像作为参考,它是要处理的输入图像。例如,图像着色任务处理灰度图像,图像填充任务恢复有缺失空洞的图像。针对一个输入信号,采用本文提出的多码GAN反演方法对输入信号进行重构,然后对重构后的图像进行后处理来逼近输入信号。当逼近足够接近输入时,我们假设后处理前的重构是我们想要的。这里,为了适应mGANprior到某个特定的任务,我们基于后处理功能对等式(5)进行修改:
对于图像着色任务,以灰度图像Igray作为输入,我们期望反演结果具有与Igray相同的灰度通道:
![]()
其中gray(·)表示取图像灰度通道的操作。
对于图像超分辨任务,以低分辨率图像的ILR作为输入,对反演结果进行采样,逼近ILR:
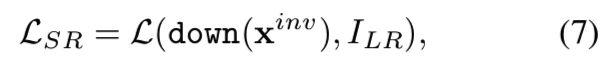
down(.)表示下采样操作
对于图像修复任务,我们使用一个完整的图像Iori和一个表示已知像素的二值掩模m,只重建未损坏的部分,并让GAN模型自动填充缺失的像素:
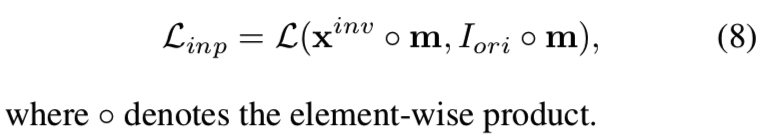
4. Experiments
为了验证mGANprior的有效性,我们对最先进的GAN模型(即PGGAN[23]和StyleGAN[24])进行了广泛的实验。这些模型在各种数据集上进行训练,包括用于人脸的CelebA-HQ[23]和FFHQ[24],以及用于场景的LSUN[46]。
4.1. Comparison with Other Inversion Methods
文献中关于GAN反演的尝试很多。在本节中,我们将我们的multi-code反演方法与下面的基本方法相比较:(a)如等式(1)[32]优化一个潜在的代码z,(b)学习一个编码器encoder反向生成器[52],和(c)合并(a)和(b)两个方法,使用(b)中编码器的输出作为(a)的初始化来进一步优化[5]。
为了定量地评价反演结果,我们引入Peak Signal-to-Noise Ratio (PSNR)来衡量原始输入和像素级重建结果之间的相似性,以及已知与人的感知相匹配的LPIPS度量[49]。我们对三种PGGAN[23]模型分别在LSUN卧室(室内场景)、LSUN教堂(室外场景)和CelebA-HQ(人脸)上进行了比较。对于每个模型,我们倒置300幅真实图像进行测试。
表1和图3分别为定量和定性比较。从表1可以看出,无论从像素级(PSNR)还是感知级(LPIPS), mGANprior在三种模型上都优于其他竞争对手。从图3中我们还可以看到,现有的方法无法恢复目标图像的细节,这是由于单个潜在代码的表示能力有限。与之相比,我们的方法获得了更令人满意的重建与大多数细节,受益于多个潜在代码。我们甚至用在西方数据上训练的模型(CelebA-HQ[23])恢复了一张东方面孔。


4.2. Analysis on Inverted Codes
如第3节所述,我们的方法实现了N个潜在编码和N个重要性因子的高保真GAN反演方法。以PGGAN为例,选择第6层(即512通道)作为N = 10的组成层,优化的参数数为10×(512 + 512),是原始潜在空间维数的20倍。在本节中,我们将对反演代码进行详细的分析。
Number of Codes. 显然,在优化空间的维数和反演质量之间存在权衡。为了更好地分析这种权衡,我们通过改变要优化的潜在代码的数量来评估我们的方法。从图4可以看出,使用的潜码越多,重构效果越好。然而,这并不意味着可以通过增加潜在代码的数量来无限地提高性能。从图4可以看出,当数量达到20时,加入更多的潜码并没有显著的改善。
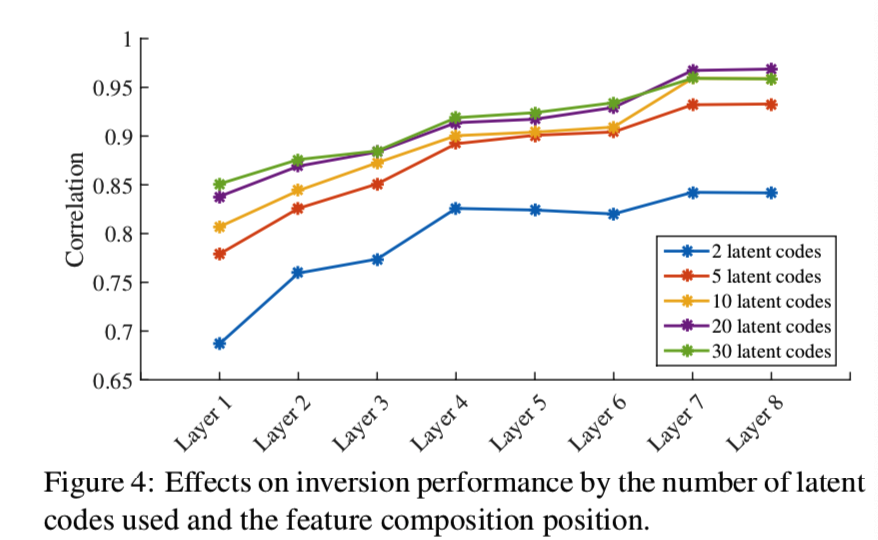
Different Composition Layers. 在哪一层上进行特征合成也会影响mGANprior的性能。因此,我们在PGGAN的各层(即1 - 8层)上构建潜码,比较反演质量,如图4所示。一般来说,组合层越高,反演效果越好。然而,正如[4]中显示的那样,更高的层包含局部像素模式的信息,如边缘和颜色,而不是高级语义。在更高层次上组合特征很难重用GANs学习的语义知识。这将在第4.4节中进一步讨论。
Role of Each Latent Code. 我们采用多重潜码,期望每一个潜码负责一个特定区域的反演,从而彼此互补。在这一部分中,我们可视化不同的潜码在反演过程中所扮演的角色。正如[4]所指出的,对于GAN模型中的特定层,不同的单元(通道)控制不同的语义概念。回想一下,mGANprior使用自适应通道重要性来帮助确定特定z应该关注哪种语义。因此,对于每一个zn,我们将αn中大于0.2的元素值改设为0,得到了α'n。然后,我们计算了分别使用的αn和α'n重建的图像之间的差异映射。借助[51]分割模型,我们还可以得到各种视觉概念的分割图,如塔和树。最后,我们基于相应的差异映射与所有候选分割映射之间的Intersection-over-Union (IoU) 度量对每个潜在代码进行注释。图5显示了所选潜码的分割结果和IoU映射。结果表明,潜码是专门用来将图像中不同的有意义区域倒置,从而构成整个图像的。这也是使用多个潜在代码而不是使用单个代码的巨大优势。
4.3. Image Processing Applications
在高保真图像重建的情况下,我们的多码反演方法与之前一样,用预先训练过的GANs简化了许多图像处理任务。在本节中,我们将提出的mGANprior应用于各种实际应用程序,以演示其有效性,包括图像着色、图像超分辨率、图像修补和去噪,以及语义操作和样式混合。对于每个应用程序,GAN模型都是固定的。
Image Colorization. 给定一个灰度图像作为输入,我们可以使用mGANprior对其着色,如3.2节所述。我们将我们使用了优化中间特征图[3]的反演方法进行了比较。我们还与DIP[39]进行了比较,DIP[39]使用了一个判别模型作为先验,Zhang等人的[48]模型是专为着色任务设计的。我们在经过训练的卧室和教堂合成图的PGGAN模型上进行实验,并以ab颜色空间上累积误差分布曲线下的面积作为评价指标,如[48]模型所做。表2和图6分别为定量和定性比较。结果表明,使用判别模型作为先验并不能使图像充分着色。这是因为辨别性模型侧重于学习高级别的表现形式,而不适合低级别的任务。相反,使用生成模型作为先验,可以得到更令人满意的色彩丰富的图像。作为主要目标为图像着色的模型(图6 (c)和(d)),我们也获得了可比较的结果。这得益于GANs学到的丰富知识。请注意,Zhang等人提出的[48]用于一般图像着色,而我们的方法只能应用于与给定GAN模型相对应的特定图像类别。在更多样化的数据集上训练一个更大的GAN模型应该可以提高它的泛化能力。

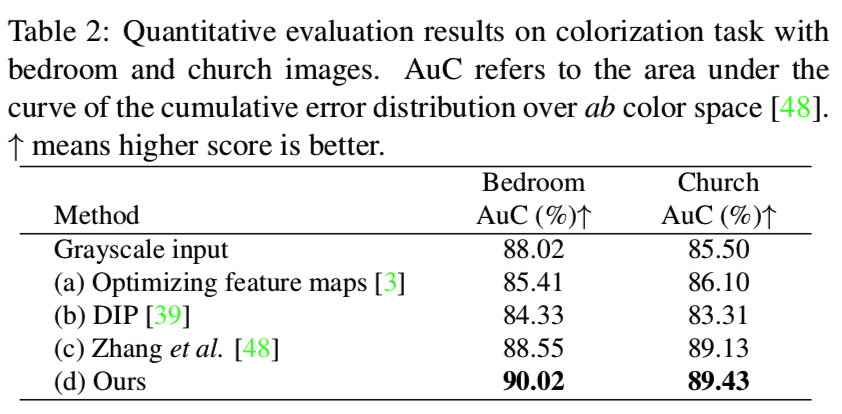
Image Super-Resolution. 我们也评估了我们的方法在图像超分辨率(SR)任务。我们在训练好的人脸合成PGGAN模型上进行实验,并将SR因子设为16。这么大的因子对于SR任务来说是非常具有挑战性的。我们与DIP[39]以及最先进的SR方法,RCAN[50]和ESRGAN[42]进行了比较。除了PSNR和LPIPS之外,我们还引入了Naturalness Image Quality Evaluator (NIQE)[33]作为额外的度量指标。表3为定量比较。我们可以得出结论,我们的方法与先进的以学习为基础的竞争对手相比,取得了可比较甚至更好的性能。一个可视化的例子也显示在图7中,在那里我们的方法重建了更详细的人眼。与RCAN和ESRGAN等现有的基于学习的模型相比,我们的mGANprior对于SR因素更加灵活。这表明,自由训练的PGGAN模型自发地学习了丰富的知识,因此可以将其用作增强低分辨率(LR)图像的先验。
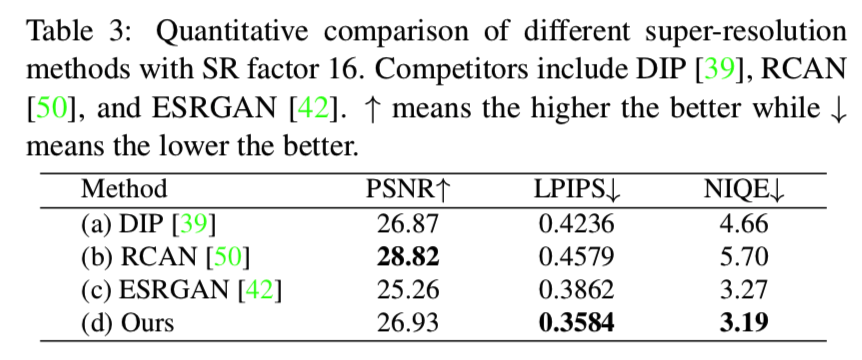

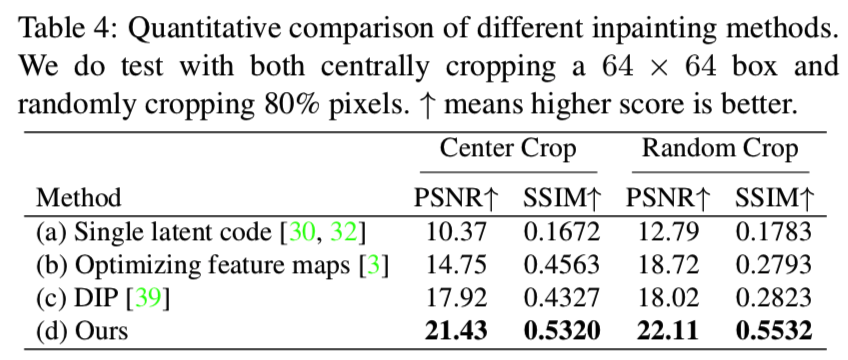
Image Inpainting and Denoising. 我们进一步扩展了我们的方法的图像恢复任务,如图像的修复和去噪。我们首先通过随机裁剪或添加噪声破坏图像内容,然后使用不同的算法恢复它们。在PGGAN模型上进行了实验,并与几种基线反演方法以及DIP[39]方法进行了比较。采用PSNR和Structural SIMilarity (SSIM) [43]作为评价指标。
表4给出了定量比较,其中我们的方法在中心裁剪和随机裁剪两种情况下都取得了最好的效果。图8包括一些恢复损坏图像的例子。很明显,现有的反演方法和DIP方法都不能充分地填充缺失的像素,也不能完全去除添加的噪声。相比之下,我们的方法能够使用训练有素的GANs来令人信服地修复带有有意义填充内容的损坏图像。

Semantic Manipulation. 除了前面提到的低级应用程序之外,我们还用一些高级任务测试了我们的方法,比如语义操作和样式混合。正如之前的工作所指出的[21,15,35],GANs已经在潜在空间内编码了一些可解释语义。从这一点上讲,我们的反演方法为将这些学习到的语义应用于实际图像处理提供了一种可行的方法。我们利用[35]中提出的基于潜码的操作框架实现了人脸属性的语义编辑。操作结果如图9所示。我们看到mGANprior可以为语义操作提供足够丰富的信息。

4.4. Knowledge Representation in GANs
如上所述,使用单个潜在编码的主要限制是其表达能力有限,特别是当测试图像与训练数据之间存在域间隙时。在这里,我们验证使用多个潜在编码是否有助于缓解这个问题。特别是,我们尝试使用训练来合成脸,教堂,会议室和卧室的不同GAN模型来反演卧室图像。如图10所示,当使用单一的潜在代码时,重构的图像仍然处于原始训练域中(例如,PGGAN CelebA-HQ模型的反演看起来像一张脸而不是一间卧室)。相反,我们的方法能够组成一个卧室的图像,无论GAN生成器是用什么数据训练。

通过在不同的层上进行特征组合,我们进一步分析了受过良好训练的GAN模型的分层知识。从图10可以看出,使用的层越高,重构效果越好。这是因为重建侧重于恢复底层像素值,而GANs倾向于在底层表示抽象语义,而在顶层表示内容细节。我们还观察到,第4层对于卧室模型来说已经足够好来反转卧室图像,但是其他三个模型需要第8层来实现满意的反转。原因是,卧室与脸、教堂和会议室共享不同的语义,因此不能重用来自这些模型的高级知识(包含在底层)。我们进一步将我们的方法应用于图像着色和图像修补任务进行分层分析,如图11所示。着色任务在第8层得到最好的结果,而修补任务在第4层得到最好的结果。这是因为着色更像是一个低级的渲染任务,而修补需要GAN先验用有意义的对象填充缺失的内容。这与图10的分析是一致的,即GAN先验的低级知识可以在更高的层重用,而高级知识可以在更低的层重用。

5. Conclusion
我们提出了mGANprior,它使用多重潜码,利用预先训练的GAN模型重建真实图像。它使这些GAN模型成为各种图像处理任务的强大先验。