https://github.com/tamarott/SinGAN
SinGAN: Learning a Generative Model from a Single Natural Image
Abstract
我们介绍SinGAN,一种可以从单个自然图像学习的无条件生成模型。我们的模型被训练来捕捉图像内patches的内部分布,然后能够生成高质量、多样化的样本,这些样本与图像具有相同的视觉内容。SinGAN包含一个由全卷积GANs组成的金字塔,每个GANs负责学习图像在不同尺度下的patch分布。这允许生成任意大小和高宽比的新样本,这些样本具有显著的可变性,同时保持了训练图像的全局结构和精细纹理。与之前的单一图像GAN方案相比,我们的方法不局限于纹理图像,而且是无条件的(即从噪声中生成样本)。用户研究证实,我们生成的样本通常被混淆为真实的图像。我们将说明SinGAN在各种图像处理任务中的使用。
1. Introduction
生成对抗网络(GANs)[19]在建模可视化数据的高维分布方面取得了巨大的飞跃。特别是,无条件的GANs在针对特定类别的数据集(例如face[33],卧室[47])进行训练时,在生成现实的高质量样本方面表现出了显著的成功。然而,捕获带有多个对象类的高度多样化的数据集(例如:ImageNet[12])的分布仍然被认为是一个主要的挑战,通常需要调节产生另一个输入信号[6]或为一个特定的任务(e.g. super-resolution [30], inpainting [41], retargeting [45])训练模型。
在这里,我们将GANs的使用带入一个新的领域——从单个自然图像学习无条件生成。具体地说,我们展示了单个自然图像中patches的内部统计信息通常携带了足够的信息来学习一个强大的生成模型。SinGAN是我们新的单一图像生成模型,允许我们处理包含复杂结构和纹理的一般自然图像,而不需要依赖于来自同一类的图像数据库的存在。这是通过一个由全卷积轻量级GANs组成的金字塔来实现的,每个GANs负责捕获不同尺度上patch的分布。经过训练后,SinGAN可以生成不同的(任意维数的)高质量图像样本,这些样本在语义上类似于训练图像,但包含新的目标配置和结构(图1)。

在许多计算机视觉任务中,建模单一自然图像中patch的内部分布一直被认为是一种强大的先验方法[64]。经典的例子包括去噪[65]、[39]去模糊、超分辨率[18]、去雾[2,15]和图像编辑[37,21,9,11,50]。本文中最相关的工作是[48],其中定义并优化了双向patch相似度度量,以保证处理后的图像patch与原始patch相同。受这些工作的启发,这里我们将展示如何在一个简单的统一学习框架内使用SinGAN来解决各种图像操作任务,包括从单一图像进行paint-to-image、编辑、协调、超分辨率和动画。在所有这些情况下,我们的模型都能得到高质量的结果,并且保留了训练图像内部的patch统计量(见图2和我们的项目页面)。所有的任务都是在同一个生成网络中完成的,没有任何额外的信息,也没有在原有的训练图像之外进行进一步的训练。

1.1. Related Work
Single image deep models. 最近的一些研究提出将深度模型“过度拟合”到单一训练示例[51,60,46,7,1]。然而,这些方法是为特定的任务而设计的(例如,超分辨率[46],纹理扩展[60])。Shocher等人[44,45]首次为单个自然图像引入了基于GAN的内部模型,并在重定向的背景下对其进行了说明。但是,它们的生成取决于输入图像(即图像到图像的映射),而不是用于绘制随机样本。相比之下,我们的框架是纯生成的(即将噪声映射到图像样本),因此适合许多不同的图像处理任务。无条件单图像GANs仅在纹理生成的背景下进行了研究[3,27,31]。在非纹理图像上训练时,这些模型不会生成有意义的样本(图3)。另一方面,我们的方法不局限于纹理,可以处理一般的自然图像(如图1)。

Generative models for image manipulation. 在许多不同的图像处理任务中,基于GAN的方法已经证明了对抗性学习的力量[61,10,62,8,53,56,42,53]。例如交互式图像编辑[61,10]、sketch2image[8,43]和其他图像到图像的翻译任务[62,52,54]。然而,所有这些方法都是在特定类的数据集上训练的,这里也常常是在另一个输入信号上生成。我们对捕获同一类图像的共同特征不感兴趣,而是考虑不同来源的训练数据——在一个单一的自然图像的多个尺度上所有重叠的patches。我们从这些数据中可以学习到一个强大的生成模型,并可用于一些图像处理任务。
2. Method
我们的目标是学习一个获取单个训练图像x内部统计信息的无条件生成模型。这个任务在概念上与传统的GAN设置类似,不同的是这里的训练样本是单个图像的小块,而不是数据库中的整个图像样本。
我们选择u不进行纹理生成,而是处理更一般的自然图像。这需要在许多不同的尺度上捕获复杂图像结构的统计数据。例如,我们想要捕捉全局属性,比如图像中大型物体的排列和形状(例如顶部的天空,底部的地面),以及细节和纹理信息。为了实现这个目标,我们的生成框架,如图4中说明的,由一个patch-GANs(Markovian判别器)[31,26]层次组成,其中每个部分负责捕获不同尺寸的x的patch分布。GANs接受域小企且能力有限,以此来阻止他们记忆单一的图像。虽然类似的多尺度架构已经在传统的GAN设置中(例如[28,52,29,52,13,24])进行了探索,但我们是第一个从单一图像进行内部学习的研究。

2.1. Multi-scale architecture
我们的模型由一个生成器金字塔{G0,…, GN}组成,训练图像金字塔x: {x0,…,xN},其中xn是x的下采样版本,乘以一个因子rn,其中 r > 1。每个生成器Gn负责生成真实图像样本 w.r.t. 对应图像xn中的patch分布。这是通过对抗训练来实现的,其中Gn学会欺骗一个相关的判别器Dn,该判别器试图将生成的样本中的patch与xn中的patch进行区分。
图像样本的生成从最粗糙的尺度开始,依次经过所有的生成器,直到最细的尺度,并在每个尺度中注入噪声。所有的生成器和判别器都具有相同的接受域,因此随着生成过程的进行,捕获结构的大小逐渐减小。在最粗糙的尺度上(即一开始),生成就是纯生成的,即GN将映射空间高斯白噪声zN到一个图像样本x̃N,
![]()
该级别的有效感受域一般为图像高度的1/2,因此GN生成了图像的总体布局和物体的整体结构。在更细的尺度(n < N)上的每个生成器G都添加了以前的尺度没有生成的细节。因此,除了空间噪声zn之外,每个发生器Gn从较粗尺度接受图像的上采样版本,即,
![]()
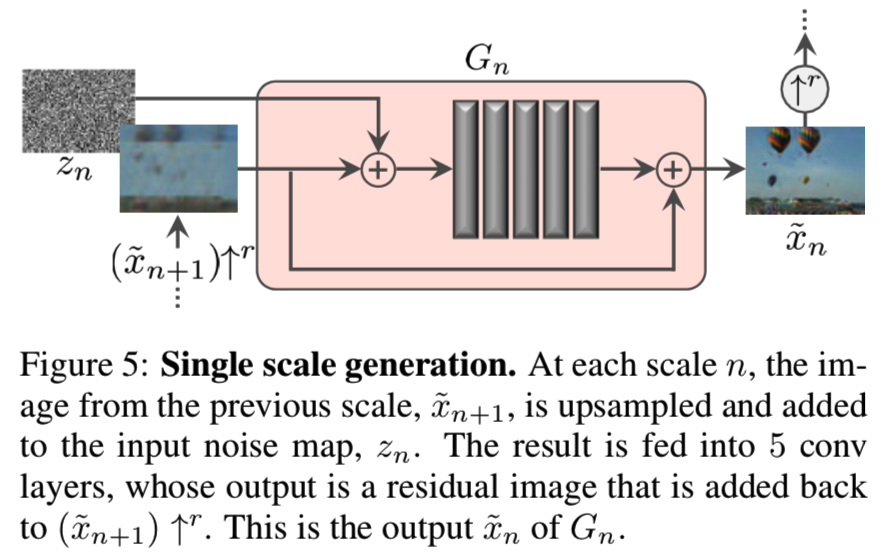
每个生成器都有相似的结构,如图5所示。具体来说,噪音zn被添加到图像![]() 上,然后输入到一系列卷积层中。这确保了GAN不会忽略噪声,就像在包含随机性的条件方案中经常发生的那样[62,36,63]。卷积层的作用是生成
上,然后输入到一系列卷积层中。这确保了GAN不会忽略噪声,就像在包含随机性的条件方案中经常发生的那样[62,36,63]。卷积层的作用是生成![]() 中丢失的细节(残差学习[22,57])。主要是,Gn实现了操作:
中丢失的细节(残差学习[22,57])。主要是,Gn实现了操作:
![]()
其中![]() 是一个带有5个格式为Conv(3 x 3)-BatchNorm-LeakyReLu[25]的卷积块的全卷积网络。一开始在粗糙尺度上使用每个块32 kernels,然后每4个尺度增加2倍。因为生成器是完全卷积的,我们可以在测试时生成任意大小和宽高比的图像(通过改变噪声映射的维度)。
是一个带有5个格式为Conv(3 x 3)-BatchNorm-LeakyReLu[25]的卷积块的全卷积网络。一开始在粗糙尺度上使用每个块32 kernels,然后每4个尺度增加2倍。因为生成器是完全卷积的,我们可以在测试时生成任意大小和宽高比的图像(通过改变噪声映射的维度)。
2.2. Training
我们按顺序训练我们的多尺度架构,从最粗糙的尺度到最精细的尺度。每个GAN一旦被训练,它就是固定的。第n个GAN的训练损失由一个对抗项和一个重建项组成,
![]()
对抗损失Ladv惩罚在xn中的patch的分布和在生成样本x̃n中的patch的分布之间的距离。重建损失Lrec保证了能够产生xn的一组特定噪声映射的存在,这是用于图像处理的一个重要特性(第4节)。接下来我们将详细描述Ladv, Lrec。有关优化细节,请参阅补充材料(SM)。
Adversarial loss . 每个生成器Gn都与一个Markovian判别器Dn相组合,该Dn将其输入的每个重叠patches分类为真或假[31,26]。我们使用wgan-gp损失[20],我们发现它提高了训练的稳定性,其中最终的辨别分数是patch辨别映射上的平均值。相对于用于纹理的单一图像GANs(例如[31,27,3]),这里我们在整个图像上定义损失,而不是在随机crop上定义损失(batch大小为1)。这允许网络学习边界条件(见SM),这是我们设置中的一个重要特性。Dn的架构与Gn内的网络![]() 相同,其patch大小(网络接受域)为11×11。
相同,其patch大小(网络接受域)为11×11。
Reconstruction loss. 我们想要保证这里存在一组特殊的输入噪声映射,能够用来生成原始图像x。具体来说就是选择![]() ,其中z*是一些固定的噪声映射(在训练中一旦绘制就固定)。使用
,其中z*是一些固定的噪声映射(在训练中一旦绘制就固定)。使用![]() 表示在训练该噪声映射时在第n个尺度上的生成图像。对于n<N,
表示在训练该噪声映射时在第n个尺度上的生成图像。对于n<N,

重构图像![]() 在训练中有另一个作用,就是去决定噪音zn在每个尺度上的标准差σn。具体来说就是使σn与
在训练中有另一个作用,就是去决定噪音zn在每个尺度上的标准差σn。具体来说就是使σn与![]() 和xn之间的均方根误差RMSE成正比,其给出了需要在该尺度下添加的细节数量的指示。
和xn之间的均方根误差RMSE成正比,其给出了需要在该尺度下添加的细节数量的指示。
3. Results
我们在各种图像上对我们的方法进行了定性和定量的测试,这些图像跨越了大范围的场景,包括城市和自然风景,以及艺术和纹理图像。我们使用的图像取自Berkeley Segmentation Database (BSD) [35], Places[59]和Web。我们总是将最粗尺度上的最小维度设置为25px,并选择尺度的数量N s.t.,尺度因子r尽可能接近4/3。对于所有的结果(除非另有说明),我们将训练图像的最大尺寸调整到250px。
我们生成的随机图像样本的定性例子如图1、图6所示,SM中还包含了更多的例子。对于每个示例,我们都展示了一些与原始图像具有相同长宽比的随机样本,并且在每个轴上都有缩小和扩大的维度。可以看出,在所有这些情况下,生成的样本描述了新的真实的结构和对象配置,同时保留了训练图像的视觉内容。我们的模型成功地保存了物体的全局结构,例如山脉(图1)、气球或金字塔(图6),以及精细的纹理信息。因为网络有一个有限的接受域(小于整个图像),它可以生成在训练图像中不存在的新的patch组合。此外,我们注意到,在许多情况下反射和阴影能逼真合成,可见图6和图1(和图8的第一个例子)。注意,SinGAN架构是分辨率无关,因此可以用于高分辨率的图像,如图7中所示(在补充材料中可见4Mpix结果)。在这里,所有尺度的结构都能很好地生成,从天空、云和山的全局排列到雪的精细纹理。


Effect of scales at test time. 我们的多尺度架构允许在测试时开始通过选择生成的尺度来控制样本之间的可变性。从尺度n开始,我们将噪声映射固定到该尺度,即![]() ,然后对
,然后对![]() 使用随机绘制。其效果如图8所示。可以看出,从最粗糙的尺度(n = N)开始生成,会导致全局结构的大变异性。在某些情况下,一个大的突出对象,如斑马图像,这可能导致不真实的样本。然而,从较细的尺度开始生成,可以保持全局结构的完整,同时只改变较细的图像特征(例如斑马的条纹)。更多例子见补充材料。
使用随机绘制。其效果如图8所示。可以看出,从最粗糙的尺度(n = N)开始生成,会导致全局结构的大变异性。在某些情况下,一个大的突出对象,如斑马图像,这可能导致不真实的样本。然而,从较细的尺度开始生成,可以保持全局结构的完整,同时只改变较细的图像特征(例如斑马的条纹)。更多例子见补充材料。
Effect of scales during training. 图9显示了较少尺度的训练的效果。在小尺度的情况下,最粗糙级别的有效感受域更小,只允许捕捉细微的纹理。随着尺度的增加,出现了更大的支持结构,并更好地保留了全局对象的安排。

3.1. Quantitative Evaluation
为了量化生成的图像的真实性以及他们捕获的训练图像的内部统计,我们使用两个指标:(i)Amazon Mechanical Turk (AMT) “Real/Fake”的用户研究,和(ii)一个新的单一图片版本的Fre ́chet Inception Distance [23]。
AMT perceptual study. 我们遵循了[26,58]的协议并在两种设置下进行了感知实验。(i)Paired(真与假):向测试者展示一轮50次的实验,每一次实验中,一幅假图像(由SinGAN生成)和其对应的真实的训练图像一起呈现1秒。测试者被要求从中挑选出假照片。(ii)Unpaired(真或假):让测试者看一张图片1秒钟,然后问它是不是假的。总共有50张真实的图像和50张不相交的假图像以随机的顺序呈现给每个测试者。
我们为两种类型的生成过程重复了这两种协议:从最粗糙(第N个)尺度开始生成,以及从尺度N−1(如图8所示)开始生成。通过这种方式,我们在两个不同的可变性水平上评估我们结果的真实性。为了量化生成图像的多样性,对于每个训练实例,我们计算每个像素在100幅生成图像上的强度值的标准差(std),并将其平均到所有像素上,然后用训练图像的强度值的标准差进行归一化。
真实图像从“places”数据库[59]的山脉、丘陵、沙漠、天空等子类别中随机选取。在这4个测试中,每一个都有50个不同的参与者。在所有测试中,前10个测试都是包含反馈的教程测试。结果如表1所示。
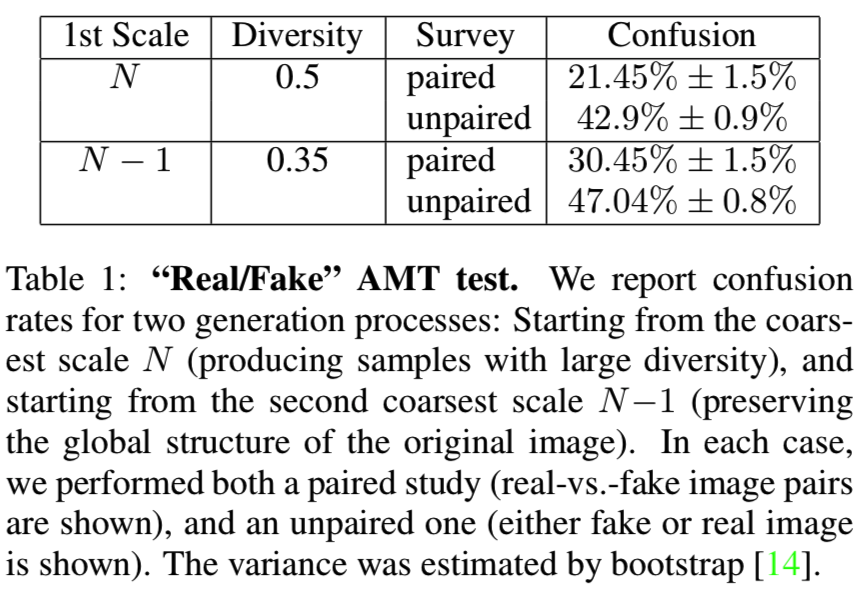
正如预期的那样,在没有配对的情况下,混淆率更大,因为没有可供比较的参考。此外,可以清楚地看到,随着生成图像的多样性增高,混淆率降低。然而,即使大的结构被改变了,我们生成的图像也很难与真实的图像区分开来(50%的分数意味着真实和虚假的完全混淆)。所有的测试图像都包含在补充材料中。
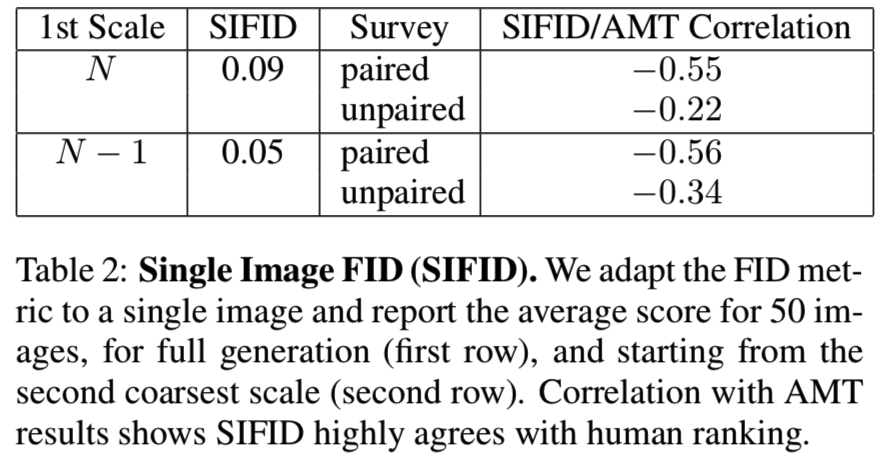
Single Image Fre ́chet Inception Distance.我们下一步则是量化SinGAN如何捕捉x的内部统计数据。GAN评价的通用指标是Fre ́chet Inception Distance(FID)[23],衡量生成的图像和真实图像的深度特征分布之间的偏差。然而,在我们的设置中,我们只有一个真实的图像,并且对它的内部patch统计数据非常感兴趣。因此,我们提出了Single Image FID (SIFID) 度量。我们没有使用Inception网络[49]中最后一个池化层之后的激活向量(每个图像一个向量),而是使用在第二个池化层之前的卷积层输出处的深层特征的内部分布(在map中每个位置一个向量)。我们的SIFID是在真实图像和生成的样本中那些特征的统计特征之间的FID。
从表2中可以看出,从N−1中产生的平均SIFID比从N中产生的平均SIFID要低,这与用户研究结果一致。我们也报告了SIFID分数和假图像的混淆率之间的相关性。注意,两者之间有显著的(反)相关性,这意味着一个小的SIFID是一个典型的大混淆率的好指标。成paired测试的相关性更强,因为SIFID是成对的度量(设有一对xn, x̃n)。
4. Applications
我们将探索SinGAN在许多图像处理任务中的使用。为此,我们在训练后使用我们的模型,不进行架构更改或进一步调优,并对所有应用程序采用相同的方法。其思想是利用在推理时,SinGAN只能生成与训练图像patch分布相同的图像。因此,我们可以在n < N的尺度下,将一幅图像(可能是下采样的图像)注入到生成金字塔中,通过生成器进行前向传播,使其patch分布与训练图像的patch分布匹配。不同的注入尺度会产生不同的效果。我们考虑以下应用(参见补充材料获得更多结果和注入尺度效果)。
Super-Resolution. 使用一个因子s来增加一个输入图像的分辨率。我们在低分辨率(LR)图像上训练我们的模型,重构损失的权重设置为α= 100和金字塔尺度因子设置为![]() 。小结构往往会在自然场景[18]中重现,在测试时间我们使用因子 r 上采样LR图像和冰将其(和噪音一起)注入到生成器G0中。我们重复其k次以获得最终的高分辨率输出。实例结果如图10所示。可以看出,我们的重建的视觉质量超过了最先进的内部方法[51,46],也超过了以PSNR最大化[32]为目标的外部方法。
。小结构往往会在自然场景[18]中重现,在测试时间我们使用因子 r 上采样LR图像和冰将其(和噪音一起)注入到生成器G0中。我们重复其k次以获得最终的高分辨率输出。实例结果如图10所示。可以看出,我们的重建的视觉质量超过了最先进的内部方法[51,46],也超过了以PSNR最大化[32]为目标的外部方法。

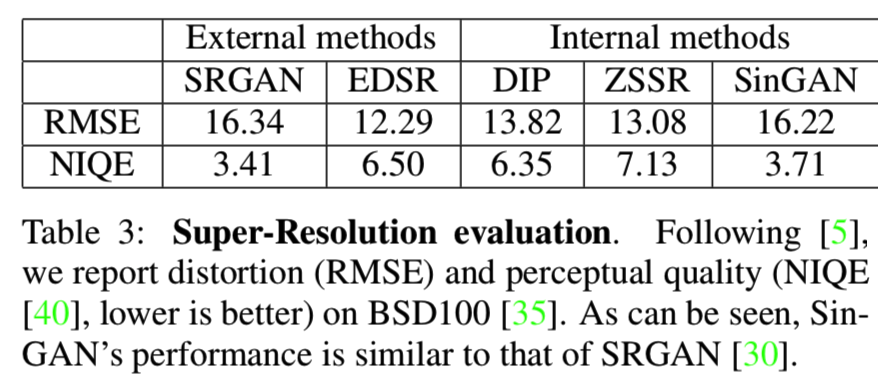
有趣的是,它可以与外部训练的SRGAN方法[30]相媲美,尽管它只暴露在一个单一的图像中。在[4]之后,我们在BSD100数据集[35]上比较了表3中的5种方法,在失真(RMSE)和感知质量(NIQE[40])方面进行对比,这是两个从根本上相互冲突的需求[5]。可以看出,SinGAN在感知质量上很优秀;它的NIQE得分仅略低于SRGAN, RMSE比SRGAN略好。
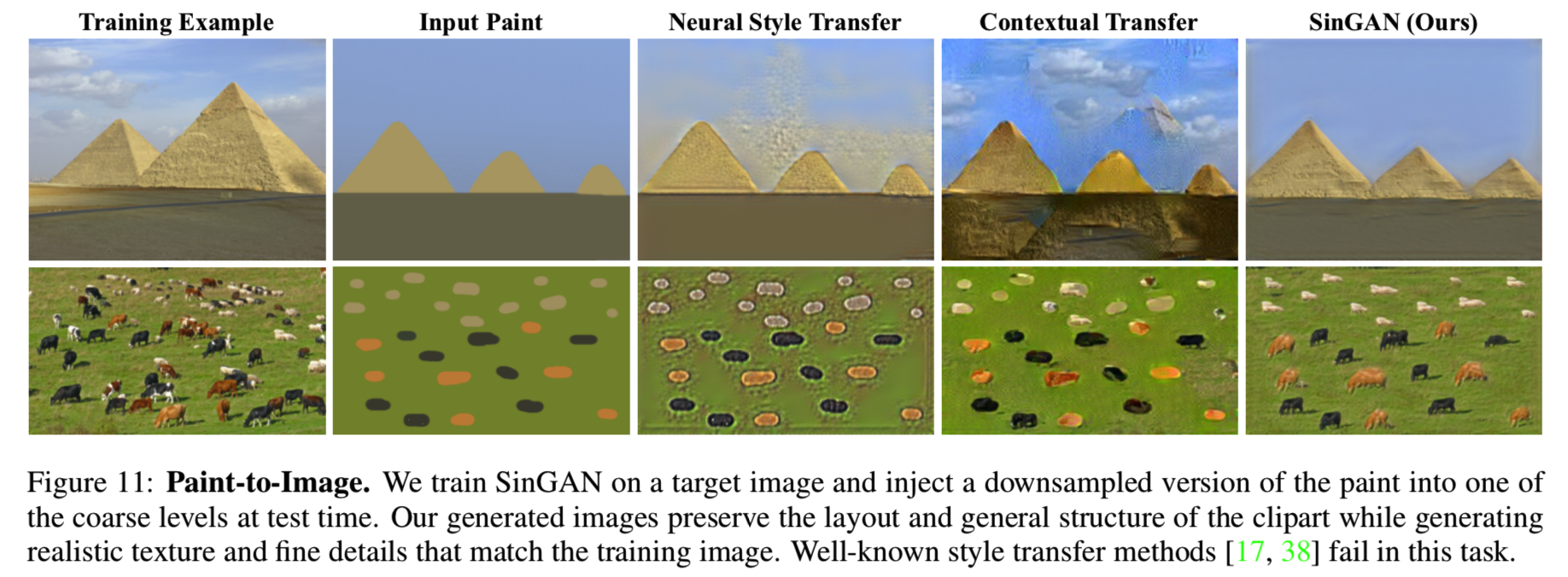
Paint-to-Image . 将剪贴画转换成逼真的图像。这是通过下采样剪纸画,并将其输入一个粗糙尺度(如N−1或N-2)的网络来实现的。在图2和11可见结果,剪贴画的全局结构保存了下来,同时匹配原始图像的纹理和高频信息生成得很逼真。在视觉质量方面,我们的方法优于风格转换方法[38,17](图11)。
Harmonization. 逼真地混合粘贴对象与背景图像。我们在背景图像上训练SinGAN,并在测试时注入一个naively粘贴的合成图像的下采样版本。在这里,我们将生成的图像与原始背景相结合。从图2和图13中可以看出,我们的模型裁剪了粘贴的物体的纹理来匹配背景,通常比[34]更好地保留了它的结构。尺度2、3、4通常在保存物体结构和转移背景纹理之间达到良好的平衡。

Editing.生成一个无缝组合结果,其中图像区域已复制和粘贴到其他位置。在这里,我们再次将一个向下采样的复合版本注入到一个粗糙尺度中。然后我们将SinGAN在编辑区域的输出与原始图像结合起来。如图2和图12所示,SinGAN重新生成了精细的纹理,并将粘贴的部分无缝拼接,比Photoshop的Content-Aware-Move效果更好。

Single Image Animation.从单一的输入图像创建一个带有真实的物体运动的短视频clip。自然图像经常包含重复内容,在相同的动态物体[55](例如,一群鸟的图像显示了一只鸟的所有翅膀姿势)的时间里显示不同的“快照”。使用SinGAN,我们可以沿着图像中物体的所有外观的manifold移动,从而从单个图像合成运动。我们发现,对于许多类型的图像,所有生成尺度上的第一帧从zrec开始,通过在z空间中进行随机游走可以获得真实的效果。结果可以在https://youtu.be/xk8bWLZk4DU上获得。
5. Conclusion
我们介绍了SinGAN,一种新的无条件生成方案,从单一的自然图像学习。我们演示了它能够超越纹理并为自然复杂的图像生成多样的真实样本的能力。与外部训练的生成方法相比,内部学习在语义多样性方面是有限的。例如,如果训练图像只包含一条狗,我们的模型将不会生成不同犬种的样本。然而,正如我们的实验所证明的,SinGAN可以为广泛的图像处理任务提供一个非常强大的工具。