Deep Networks with Internal Selective Attention through Feedback Connections
Abstract
传统的卷积神经网络是静止的、前馈(feedforward)的。他们在评估过程中既不改变参数,也不使用从高层到低层的反馈。然而,真正的大脑会。我们的Deep Attention Selective Network(dasNet)架构也是如此。DasNets的反馈结构可以在分类过程中动态地改变卷积滤波器的敏感性。通过允许网络迭代地将其内部注意力集中在一些卷积过滤器上,它利用了顺序处理的能力来提高分类性能。根据可扩展自然进化策略(scalable natural evolution strategies,SNES),反馈(feedback)通过直接策略搜索(direct policy search),在一个巨大的百万维参数空间进行训练。在CIFAR-10和CIFAR-100数据集上,dasNet优于以前的最先进的模型。
1 Introduction
由backprop(后向传播)[3-5]在gpu[6]上训练的具有最大池化层[2]的深度卷积神经网络(CNNs)[1]在物体识别[7-10]、分割/检测[11,12]和场景解析[13-15]方面已经成为最先进的技术(详见[16])。这些结构由许多堆叠的前馈层组成,模仿人类视觉皮层bottom-up的路径,其中每一层逐步学习输入数据的更抽象的表示。低阶阶段倾向于学习生物学上可信的特征检测器,如Gabor滤波器[17]。较高层次的探测器学会对具体的视觉物体或它们的部分做出反应,例如,[18-21]。一旦训练完成,CNN不会在评估过程中改变它的权值或过滤器。
进化已经发现了在眨眼间识别特定物体的有效前馈途径。然而,当一个鸟类学家被要求对属于两个非常相似的物种之一的鸟类进行分类时,他可能要思考几毫秒才能回答[22,23],这意味着要进行几次前馈评估,每次评估都试图从图像中抽出不同的信息。
既然人类从这种策略中获益良多,我们假设CNN也可以。这就需要:(1)建立一个训练后能够适应自身行为的非静止CNN,(2)一个决定如何适应CNN行为的过程。
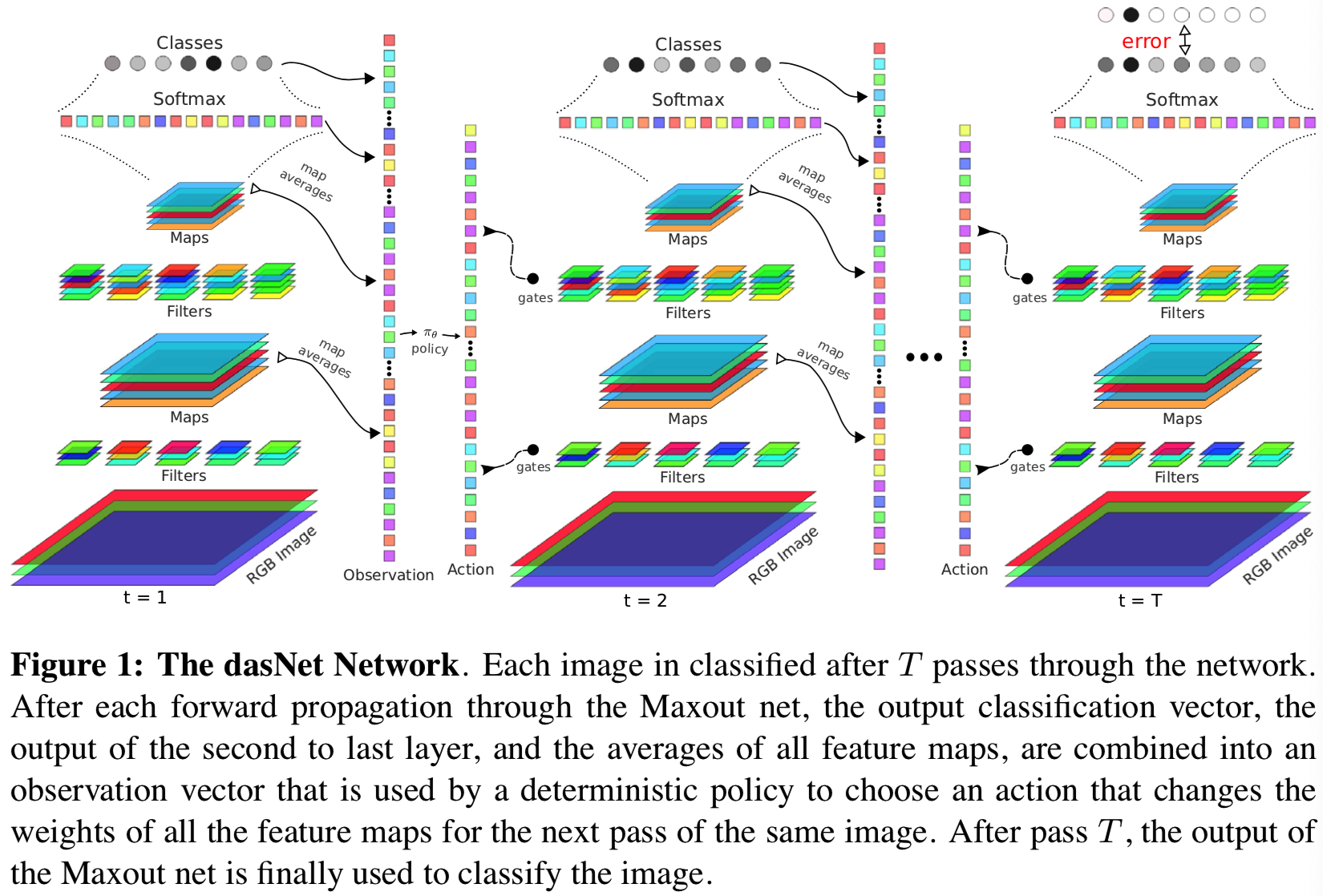
本文介绍了Deep Attention Selective Networks(dasNet),该网络通过允许每一层通过特殊连接(bottom-up和top-down),在图像的连续传递中,影响图像上的所有其他层,从而在深度CNN中构建Selective attention,这些特殊连接可以调节卷积滤波器的活动。这些特殊连接的权值实现了一种控制策略,这种控制策略是在CNN按照通常的方式通过监督学习进行训练后,通过强化学习来学习的。对于一个输入图像,注意力策略可以通过多次增强或抑制特征,以改善对最初监督训练没有捕捉到的困难情况的分类。我们的目标是让系统自动检查内部CNN过滤器的有用性,省略人工检查[24]。
在我们目前的实施中,注意力策略是使用可分离的自然进化策略(Separable Natural Evolution Strategies ,SNES),而不是传统的单一代理强化学习方法(例如value iteration, temporal difference, policy gradients等),因为控制用于图像分类的CNN的一般大小都需要大量的参数(超过100万)。在CIFAR-10和CIFAR100[26]上的实验表明,在困难的分类实例上,该网络通过强调和弱化某些过滤器来自我校正,性能优于之前的最先进的CNN。
2 Maxout Networks
在这项工作中,我们使用Maxout网络[10],结合dropout[27],作为dasNet的底层模型。Maxout网络在各种任务中代表了最先进的对象识别技术,只有在几个卷积神经网络的平均committees表现得比它好(只有很小的差距)。最近也提出了一个类似的方法[28],它不降低维数,有利于稀疏表示。Maxout CNNs由卷积层和Maxout层交替叠加而成,最后在最上面有一个分类层:
Convolutional Layer. 该层的输入可以是一张图,或上一层的输出,由宽为m、高为n的c个输入maps组成![]() 。输出则由c'个输出maps的集合组成:
。输出则由c'个输出maps的集合组成:![]() 。卷积层由c*c'个大小为k*k的过滤器参数化。我们使用
。卷积层由c*c'个大小为k*k的过滤器参数化。我们使用![]() 表示过滤器,其中i和j是输入输出maps的索引,
表示过滤器,其中i和j是输入输出maps的索引,![]() 表示层数:
表示层数:

其中i和j分别索引输入和输出map,* 表示卷积操作符,Φ表示element-wise非线性函数,![]() 用来索引层。输出的大小被卷积的核大小和步长决定(可见[10])
用来索引层。输出的大小被卷积的核大小和步长决定(可见[10])
Pooling Layer. 这里使用的Maxout池化层用于降低卷积层输出的维数。通常的方法是在每张图中不重叠或部分重叠的patches中取最大值,因此可以沿高度和宽度[2]进行降维。相反,Maxout池化层通过只保留每个像素位置的最大值,将每b个连续的映射缩减为一个映射,其中b被称为块大小。因此,该映射将c输入映射简化为c' = c/b输出映射。
![]()
(所以Maxout池化层降低的是channels,而不改变高和宽)
其中![]() ,
,![]() 仍是用来索引层的。pooling层的输出要么作为另一个卷积-池化层的输入,要么作为最后分类层的输入
仍是用来索引层的。pooling层的输出要么作为另一个卷积-池化层的输入,要么作为最后分类层的输入
Classification Layer. 最后,实现一个分类step。首先,最后一个pooling层的输出被flatten成一个大向量![]() ,去形成如下等式的输入:
,去形成如下等式的输入:

其中![]() ,σ(.)表示一个softmax激活函数,生成类概率v。输入由F投射,然后使用maxout减少,类似于pooling层(3)
,σ(.)表示一个softmax激活函数,生成类概率v。输入由F投射,然后使用maxout减少,类似于pooling层(3)
3 Reinforcement Learning
强化学习(RL)是一种学习的一般框架,用于做出顺序决策,以最大化外部奖励信号[29,30]。学习agent可以是任何有能力在特定环境中行动和感知的东西。
在时间t,agent收到一个环境当前状态![]() 的观察
的观察![]() ,然后通过策略
,然后通过策略![]() 选择一个action
选择一个action ![]() ,其中
,其中![]() 分别表示所有可能的状态(states)、观察(observations)和动作(action)的空间。然后agent就会进入新的状态s,并接收到一个奖励(reward)
分别表示所有可能的状态(states)、观察(observations)和动作(action)的空间。然后agent就会进入新的状态s,并接收到一个奖励(reward)![]() 。目标是找到能够最大化expected future discounted reward
。目标是找到能够最大化expected future discounted reward![]() 的策略
的策略![]() ,其中
,其中![]() discount the future ,构建agent的“远见”
discount the future ,构建agent的“远见”
在dasNet中,观察和action空间都是实值 ![]() ,
,![]() 。因此,策略
。因此,策略![]() 必须使用一个函数近似器表示,即一个参数为Θ的神经网络。由于用于控制dasNet的注意力的策略具有接近1000个维度的状态和动作空间,因此策略参数向量Θ将包含接近100万个权重,这对于标准的RL方法是不实际的。因此,我们反而利用自然进化策略(Natural Evolution Strategies ,NES; [31, 32])的一个变体来进化策略,称为Separable NES (SNES;[25])。NES家族的黑箱优化算法在搜索空间使用参数化的概率分布,而不是显式的population(即,传统的ES[33-35])。一般来说,分布是一个由均值μ和协方差矩阵Σ参数化的多元高斯。每一个epoch从分布取样一个generation,然后在分布预期适合度的自然梯度方向更新它。SNES与标准NES的不同之处在于,它不保持搜索分布的完整协方差矩阵,而只使用对角entries。SNES理论上比标准的NES功能更弱,但实质上更有效。
必须使用一个函数近似器表示,即一个参数为Θ的神经网络。由于用于控制dasNet的注意力的策略具有接近1000个维度的状态和动作空间,因此策略参数向量Θ将包含接近100万个权重,这对于标准的RL方法是不实际的。因此,我们反而利用自然进化策略(Natural Evolution Strategies ,NES; [31, 32])的一个变体来进化策略,称为Separable NES (SNES;[25])。NES家族的黑箱优化算法在搜索空间使用参数化的概率分布,而不是显式的population(即,传统的ES[33-35])。一般来说,分布是一个由均值μ和协方差矩阵Σ参数化的多元高斯。每一个epoch从分布取样一个generation,然后在分布预期适合度的自然梯度方向更新它。SNES与标准NES的不同之处在于,它不保持搜索分布的完整协方差矩阵,而只使用对角entries。SNES理论上比标准的NES功能更弱,但实质上更有效。
4 Deep Attention Selective Networks (dasNet)
dasNet背后的想法是利用顺序处理的能力,通过允许网络迭代地集中过滤器的注意力来提高分类性能。首先,对标准的Maxout net(见第2节)进行扩充,允许对同一幅图像的不同路径进行不同的加权(与公式1比较):
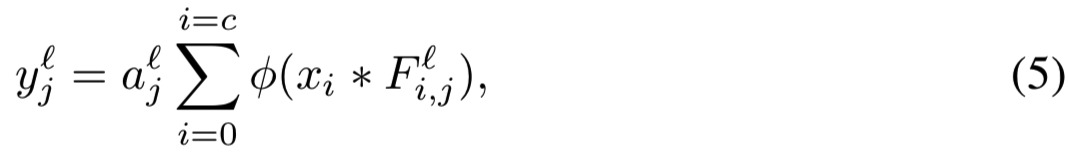
其中![]() 是层
是层![]() 的第j个输出map的权重,用于在使用maxout池化层之前改变其激活函数的力度。向量
的第j个输出map的权重,用于在使用maxout池化层之前改变其激活函数的力度。向量![]()
![]() 表示的是在图像被处理过程中,为了顺序将Maxout net的注意力集中在最具区分度的特征,可学习的策略必须要选择的action。改变动作a会改变CNN的行为,即使图像x没有改变,也会产生不同的输出。我们用以下符号表示:
表示的是在图像被处理过程中,为了顺序将Maxout net的注意力集中在最具区分度的特征,可学习的策略必须要选择的action。改变动作a会改变CNN的行为,即使图像x没有改变,也会产生不同的输出。我们用以下符号表示:
![]()
其中Θ是策略![]() 的参数向量,vt是网络第t次传播的输出。
的参数向量,vt是网络第t次传播的输出。
算法1描述了dasNet训练算法。给定一个Maxout net M,其已经使用训练集X训练好去分类图像了,策略![]() 使用SNES去进化来集中M的注意力。每一次经过while循环都代表了一代SNES。每一代都从从X中随机选择n个图像的子集开始。然后p次采样中的每次采样都从SNES搜索分布(均值μ和协方差Σ)中抽取表示候选策略
使用SNES去进化来集中M的注意力。每一次经过while循环都代表了一代SNES。每一代都从从X中随机选择n个图像的子集开始。然后p次采样中的每次采样都从SNES搜索分布(均值μ和协方差Σ)中抽取表示候选策略![]() 参数的θi,经过n次试验,每次使用batch中的一张图像。在试验期间,每张图像被呈现给Maxout net T次。在第一遍,t = 0时,action a0被设置为ai = 1,∀i,这样Maxout网络函数就是普通形式——即action没有任何影响。将图像通过网络传播后,用h(·)将M中提取的以下值串联起来,构造一个观察(observation)向量o0:
参数的θi,经过n次试验,每次使用batch中的一张图像。在试验期间,每张图像被呈现给Maxout net T次。在第一遍,t = 0时,action a0被设置为ai = 1,∀i,这样Maxout网络函数就是普通形式——即action没有任何影响。将图像通过网络传播后,用h(·)将M中提取的以下值串联起来,构造一个观察(observation)向量o0:
- 每个Maxout层的每个输出map的平均激活Avg(yi)(等式2)
- 分类层的中间激活
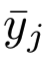
- 类概率向量vt

虽然平均map激活只提供部分状态信息,但这些值仍然应该足够有意义,以允许选择良好的操作。然后,候选策略将观察结果映射到一个动作上:
![]()
其中![]() 是神经网络的权重矩阵,σ是softMax函数。注意,softmax函数的输出值后面还根据动作空间的维数进行缩放的(即乘以dim(A)),因此动作向量中的元素平均为1(而不是常规的softmax,其总和为1),确保所有网络输出都是正的,从而保持过滤器的激活稳定。
是神经网络的权重矩阵,σ是softMax函数。注意,softmax函数的输出值后面还根据动作空间的维数进行缩放的(即乘以dim(A)),因此动作向量中的元素平均为1(而不是常规的softmax,其总和为1),确保所有网络输出都是正的,从而保持过滤器的激活稳定。
在接下来的步骤中,同样的图像被再次处理,但是这次使用过滤器权重为a1。重复此循环,直到进行T次(过程如图1所示)
此时网络性能的评分为:
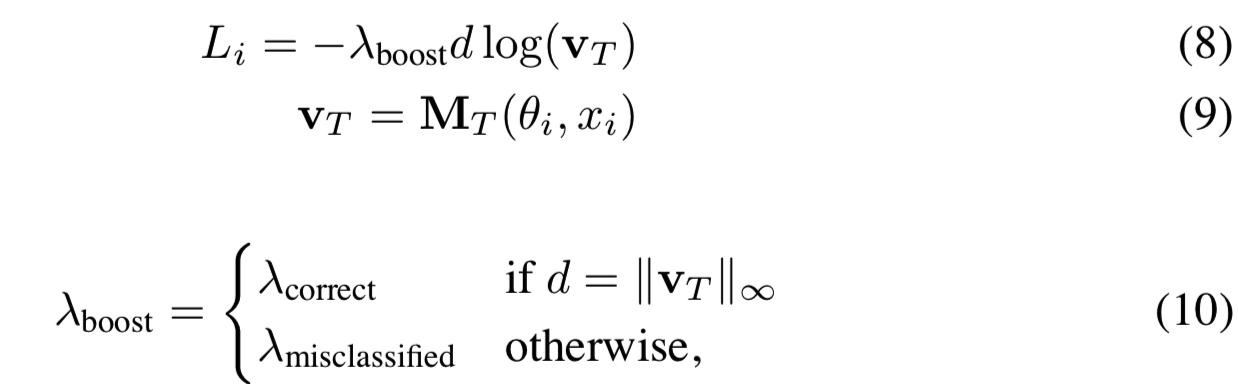
这里v是经过T次迭代后M的输出,d是正确分类,λcorrect和λmisclassified是常数。Li计算的是加权损失,错分类的样本的权重高于正确分类的权重λmisclassified > λcorrect。这个简单的boosting形式用于关注“difficult”的错分类图像。一旦所有的输入图像被处理后(即j层循环结束后),策略就被分配适合度:

其中,λL2为正则化参数。
一旦所有候选策略被评估,SNES根据由采样适合度值F计算的自然梯度更新其分布参数(μ,Σ)。SNES反复多代更新分布后,预期的分布的适合度被改善,直到改善效果符合停止标准。
5 Related Work
人类的视觉仍然是已知的最先进和最灵活的感知系统。从结构上看,视觉皮层区域是高度连接的,包括多层次的直接连接和top-down的连接。Felleman和Van Essen[36]构建了一个(现在著名的)macaque视觉皮层的32个不同视觉皮层区域的层次图。约40%的区域对被认为是连通的,大部分连通的区域是双向连通的。top-down的连接比bottom-up的连接更多,而且[37]通常更分散。它们被认为主要起着调节作用,而前馈连接作为有方向性的信息载体[38]。
对新呈现的图像的反应延迟的分析证实了视觉处理有两个阶段的理论:由于前馈处理,一个快速的、pre-attentive阶段,后面跟着的是一个注意力阶段,这是因为[39]重复处理的影响。前馈处理后,我们可以识别和定位简单的突出的刺激,使其“弹出(pop-out)”[40],无论干扰因素有多少,反应时间都不会增加。然而,这种效果只在基本特征如颜色或方向上得到证实;对于类别刺激或人脸,是否存在弹出效应仍存在争议[41,42]。在注意阶段,反馈连接被认为在[43]中起着重要的作用,例如在特征分组中,在从背景中区分出前景(特别是前景不是很突出的时候[44,45]),以及在[46]中感知填充中起着重要的作用。Bar等人[47]的研究支持了这样一种观点,即前额叶皮层top-down的投射在物体识别中起着重要作用,它可以快速提取低水平空间频率信息,对潜在类别进行初步猜测,形成top-down的预期,从而导致识别出现偏差。周期性连接似乎严重依赖于竞争性抑制和其他反馈,以使物体识别更加鲁棒[48,49]。
在计算机视觉背景下,RL已被证明能够在视觉场景中学习saccades以学习selective attention[50],学习到较低水平的反馈[51,52],并提高人脸识别[53-55]。实验表明,该方法可以有效地识别物体,并与传统的计算机视觉基础[57]相结合。利用递归算法对图像进行迭代处理,成功地实现了图像重建[58]和人脸定位[59]。所有这些方法都表明,处理中的递归性和RL视角可以带来新的算法,提高性能。然而,由于计算的限制,这项研究通常用于简化数据集的演示目的,而不是旨在改善最先进的效果。相反,我们将这个观点直接应用到已知的最先进的神经网络上,以表明这种方法现在是可行的,并且实际上提高了性能。
6 Experiments on CIFAR-10/100
dasNet的实验评估集中在CIFAR-10和CIFAR-100数据集中的模糊分类案例上,在这些案例中,由于有大量的共同特征,两个类经常被误认为是彼此。对于我们的方法来说,这些是最有趣的案例。通过在一个已经训练好的模型上学习,dasNet必须致力于修正这些错误的预测,而不破坏或忘记已经学到的东西。
CIFAR-10数据集[26]由32×32大小的彩色图像组成,分割成5×104个训练样本和104个测试样本,每幅图像被分配到10个类中的一个。CIFAR-100的组成类似,但包含100个类。
实验确定了RL的步数T,并将其固定为5;该步骤足够多以允许dasNet进行调整,同时又足够小,便于实践。虽然可以迭代直到满足某些条件,但在实时应用程序中,这可能是一个严重的限制,因为可预测的处理延迟非常重要。在所有实验中,设置λcorrect = 0.005 、λmisclassified = 1和λL2 = 0.005
实验中使用的Maxout网络M,根据建议的全局对比度归一化和ZCA归一化协议进行数据增强来进行训练。该模型由三个卷积maxout层和一个全连接的maxout和softmax输出组成。除输入层外,所有层的Dropout都是0.5,输入层的Dropout是0.2。SNES的population大小被设置为50。
表1显示了dasNet与其他方法的性能对比,其中与普通的CNN相比,它实现了6%的相对改进。这为这个具有挑战性的数据集建立了一个新的最先进的结果。
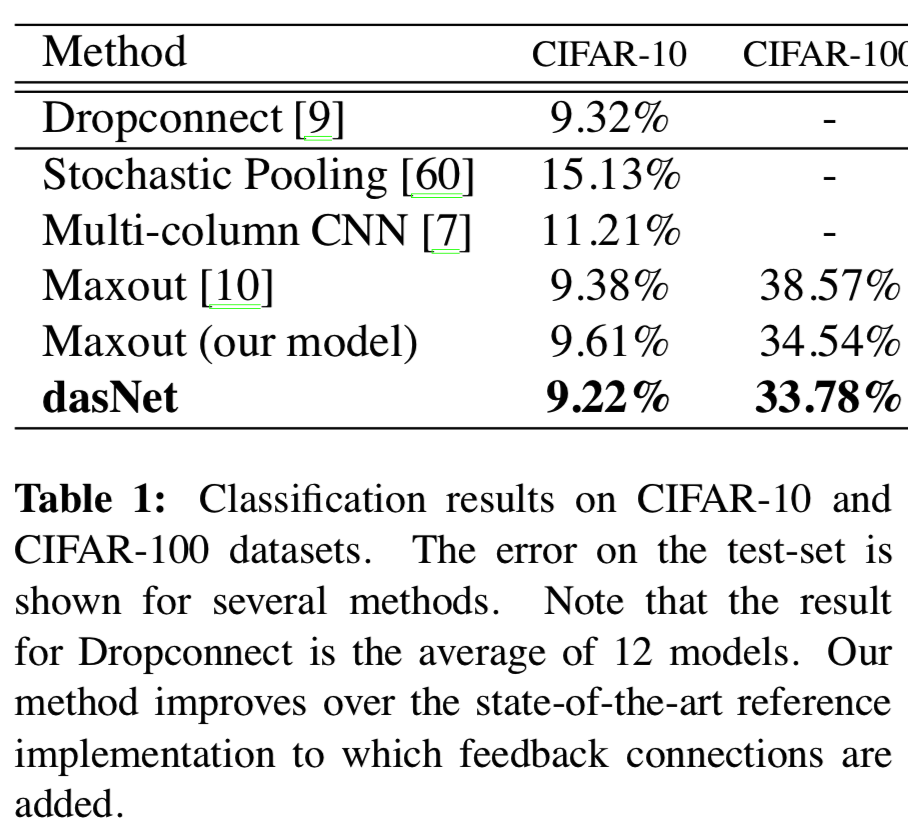
图3显示了来自测试集的cat图像的分类。最后一步中的所有输出map激活都显示在上面一行。与第一步相比,激活的不同,即每个map的(不)强调,显示下一行。左边是每个时间步长的类概率。在第一步,分类是“狗”,猫确实有可能被误认为是小狗。请注意,在第一步中,网络尚未收到任何反馈。在接下来的步骤中,“猫”的概率会大幅上升,随后在接下来的步骤中会有所下降。这个网络成功地消除了猫和狗之间的歧义。如果我们调查过滤器,我们看到在较低的层emphasis变化已经很大。一些过滤器更多地聚焦于周围环境,而另一些滤镜则不强调眼睛。

在第二层中(即layer 1),几乎所有的输出映射都被强调。在第三层也是最高的卷积层,网络有着最复杂的变化。在这个层次上,位置对应性很大程度上丢失了,而过滤器被认为编码了“更高层次”的特征。正是在这一层中,变化的影响最大,因为它们最接近最终的输出层。很难分析这些改变的影响,但是我们可以看到,这些差异不是简单的输出映射的增加或减少,因为我们会期望最终的激活和它们相应的增加是非常相似的。相反,我们看到的是复杂的强调和模式抑制。
Dynamics 为了研究dynamics,我们针对不同的T值训练了一个小的2层dasNet网络。然后通过允许它们运行[0..9]次来评估。图2显示了T = 1和T = 2时,在CIFAR-100上训练dasNet的结果。性能从普通的CNN开始上升,在step = T达到预期的峰值,之后下降但保持稳定。因此,即使只使用少量的步骤来训练dasNet,在对多达10个步骤进行评估时,动态仍然保持稳定。
为了验证dasNet策略是否真的很好地利用了它的gates(门控),它们的信息内容是按照以下方式估计的:最后一步中的gate值是直接用于分类的。如果gates被正确地使用了,那么它们的激活应该包含与分类相关的信息,我们将期望使用T = 2训练的dasNet作为分类的特征。然后只使用最终的gate值(例如不使用分类层的输出),使用15个最近邻和逻辑回归进行分类。这使得性能的正确率分别为40.70%和45.74%,类似于dasNet的性能,确认了它们包含了重要信息,并且我们可以断定它们是有目的地使用的。

7 Conclusion
DasNet是一个具有反馈连接的深度神经网络,通过强化学习可以将选择性的内部注意力引导到从图像中提取的某些特征上。在通过标准的一堆前馈滤波器进行快速的first shot图像分类后,反馈可以积极地改变某些滤波器"inhindsight"的重要性,通过额外的内部“thoughts”纠正最初的猜测。
DasNet成功地学会了对训练有素的前馈Maxout网络产生的图像误分类进行纠正。它主动的,选择性的,内部spotlight的注意力得到了最先进的结果。
未来的研究还将考虑更复杂的空间聚焦(或改变)部分观察图像的动作。