https://github.com/frgfm/torch-cam
SS-CAM: Smoothed Score-CAM for Sharper Visual Feature Localization
Abstract
由于深度卷积神经网络在high-risk环境中的应用,对其潜在机制的解释已成为深度学习领域研究的一个重要方面。为了解释这些黑箱架构,已经应用了许多方法,以便能够分析和理解内部决策。本文以Score-CAM为基础,介绍了一种基于视觉清晰度的加强视觉解释,称为SS-CAM,它通过平滑的操作产生图像内目标特征的集中定位。我们在ILSVRC 2012验证数据集上评估我们的方法,它在可信度和定位任务上都优于Score-CAM。
I. INTRODUCTION
在过去几年里,解决视觉问题的主要方法是卷积神经网络(CNNs)。它的架构[6][21]已经有了足够的进步以处理复杂的问题,如图像字幕[8],图像分类[20],语义分割[10]和许多其他问题[7],[13],[22]。尽管它们解决主要视觉任务的能力是不断在进步的,但它们仍然像黑盒架构一样工作,并且解释这些模型已经成为一项困难的任务。由于这些架构应用于医疗、金融和自动导航设施等高度敏感的环境,人们必须了解架构的基础,以防止任何类型的不可挽回的损害。随着体系结构复杂性的增加,任务将继续变得越来越困难。
为了避免这种因敏感问题受到阻碍的情况发生,这些无法解释的架构需要通过可视化推理来解释它们所做的决策。视觉信息不仅可以帮助识别架构的缺陷,还可以帮助生成洞察力来改进模型。识别缺陷可以帮助调试网络。在执行上述任务时,模型通常倾向于错误地分类,但是要理解模型究竟为什么会犯这样的错误,需要花费大量的时间和精力。视觉信息可以帮助指出模型的错误。其他的见解可以是与改进模型有关的,以产生更好的定位结果、可信度和获得人们的信任。他们还可以帮助解决[1]中解释的问题,[1]侧重于非包容性数据集中涉及的种族和性别偏见,这已经成为许多开发人员日益关注的问题。任何不能处理种族主义和性别偏见的结构在任何方面都不会被接受。
[26]的Deconvolution方法和[19]的Guided Backpropagation方法是第一个解决这个问题的方法。但是最近的进展是通过在最终的池化层之前给予图像中每个区域对应的权重来得到最好的attribution maps结果。基于梯度的可视化、基于扰动的可视化和类激活映射[27]是当前常用的三种maps方法,它们可以帮助开发可视化辅助工具。基于梯度的方法通过反向传播[19],利用目标类分数对输入图像的导数来生成saliency maps。扰动(Perturbing)方法[11],[14]也是一种常用的在图像中寻找感兴趣区域的技术,它通过masks输入中的某个特定区域来工作。在目标类上造成最大下降的区域被视为重要区域。其他作品[24]添加了regularizers来使这些attribution maps结果更加健壮,并且已经开发了一些[25]封装包。
我们的工作建立在基于CAM的方法[2]、[15]、[27]之上,这些方法通过权重和激活maps的线性组合获得attribution maps。最近的基于CAM的方法都是对原始CAM的推广,并不局限于具有特殊全局池化层的CNNs。它们可以分为两个分支,一个是基于梯度的CAMs[2]、[15],它们通过梯度信息表示内部激活maps对应的线性权值。另一种是无梯度CAMs[4]、[23],它们通过目标分数捕获每个激活映射在正向传播中的重要性。虽然Score-CAM[23]在视觉比较和公平性评价方面都取得了很好的成绩,但其定位结果比较粗糙,存在一定的不可解释情况。
为了实现更好的视觉特征定位,本文在Score-CAM[23]的基础上,提出了一种新的方法SS-CAM,用于增强对对象的理解,并通过平滑处理对图像中集中的目标对象提供更好的post-hoc解释。我们在ILSVRC 2012数据集上基于4个主要指标来评估我们的方法。我们的贡献可以总结如下:
- 我们介绍了一种增强的视觉特征定位方法SS-CAM,它结合了Score-CAM和一个额外的平滑操作,得到视觉上更清晰的attribution maps。
- 介绍了两种类型的平滑方法,定量地评价了不同位置平滑的差异。
- 与以往基于CAM的方法相比,我们的方法获得了更好的视觉性能。我们定量地评估了识别、定位和human trust任务,并表明SS-CAM能更好地定位与决策相关的特征。
II. RELATED WORK
基于梯度的方法通过[19]反向传播,使用目标类分数对输入图像的导数来生成saliency maps。
SmoothGrad [18]: SmoothGrad的目标是通过添加足够的噪声到图像和生成类似的图像来减少视觉噪声。然后对这些采样的相似图像的sensitivity maps进行平均。用噪声训练和用噪声推断模型的决策似乎在产生最佳结果方面有更好的效果。通过在x附近随机抽取样本并对得到的maps进行平均,可以创建视觉上清晰的基于梯度的sensitivity maps。它表示为:

其中n表示样本的数量,![]() 表示添加到图像输入x的标准差为σ的高斯噪音
表示添加到图像输入x的标准差为σ的高斯噪音
CAM [27]: CNN利用目标和可区分的图像区域,通过线性结合权重和激活图来识别特定类别。这些类别称为类激活映射(Class Activation Maps ,CAMs)。预测类分数值被映射回上一个卷积层时,对应的区域将高亮显示。表示为:
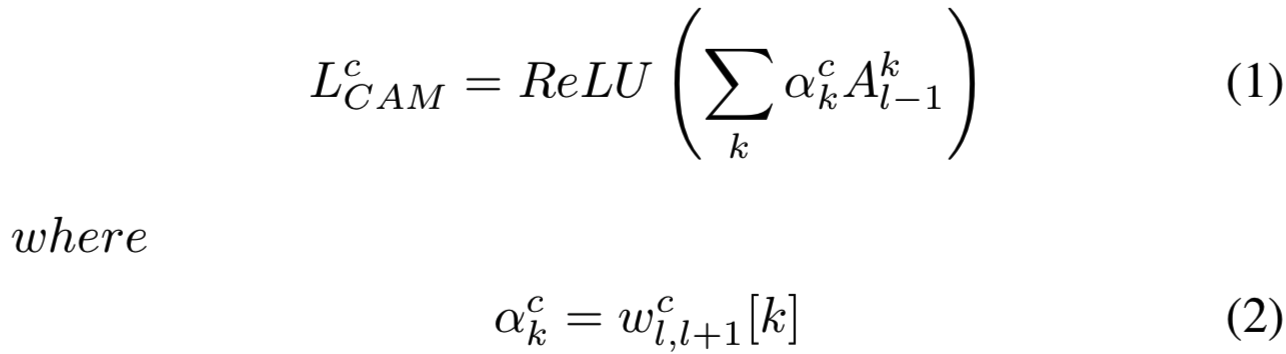
![]() 表示池化操作后第k个神经元的权重
表示池化操作后第k个神经元的权重
Grad-CAM[15]是CAM的推广。为了获得细粒度的可视化,通过与通过Guided Backpropagation获得的可视化结果相乘,对Grad-CAM 激活maps进行了修改。这被称为“Guided Grad-CAM”。
Grad-CAM [15]: 该技术利用局部梯度来表示线性权值,可以应用于任何基于平均池化的CNN架构,无需再进行训练。表示为:
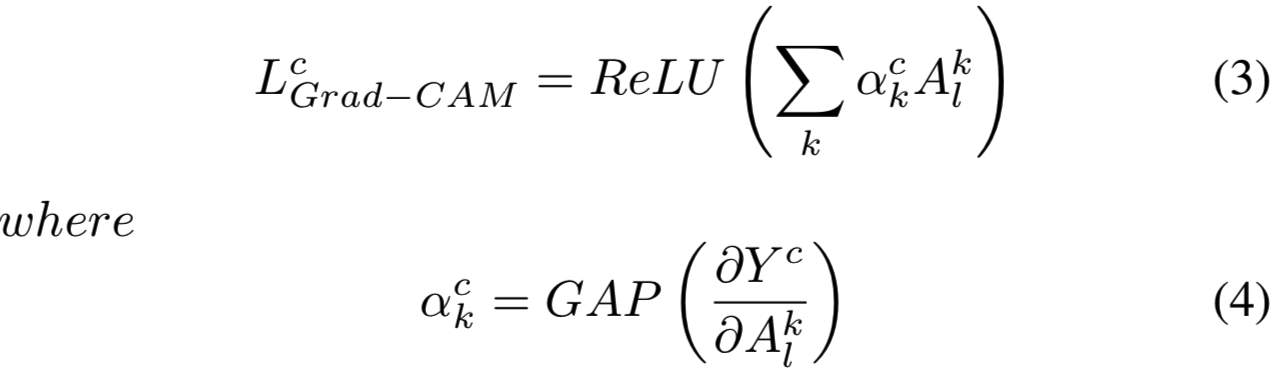
GAP(.)表示全局平均池化操作
但是,这种方法有一些局限性。由于梯度饱和,它无法在高置信度的情况下提供有价值的解释,也无法在一张图像中高亮显示同一物体的多次出现。此外,用Grad-CAM生成的热图不能完全捕捉整个物体,因为梯度往往是嘈杂的,但这却是获得更好的识别图像中的物体所必需的。
该技术在Grad-CAM++[2]中得到了进一步的改进,该技术通过定位图像中的整个对象而不是局部对象得到了更好的结果。然而,由于最初的CAM仅限于具有CAP层的CNN,因此无法对大量的CNN做出可行的解释。由于输出层是一个非线性函数,基于梯度的CAMs往往会减小反向传播的梯度,导致梯度饱和,因此难以给出具体的解释。为了解决这些问题,Score-CAM[23]作为第一个无梯度推广CAM方法,弥补了基于摄动的方法和基于CAM的方法之间的差距。
Score-CAM [23]: Score-CAM获得每个激活map在其目标类的前向传播分数中的权重。最后的结果是权重和激活maps的线性组合。在Score-CAM中,Lc表示为:
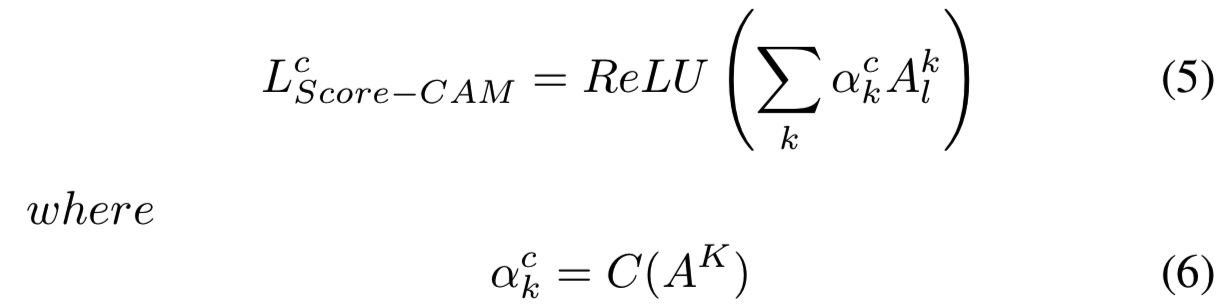
其中c是感兴趣的类,![]() 是卷积层,C(.)是激活map
是卷积层,C(.)是激活map![]() Channel-wise的Increase of Confidence(CIC)分数。
Channel-wise的Increase of Confidence(CIC)分数。
III. PROPOSED APPROACH
检测模型不良行为和良好的post-hoc可视化结果是Score-CAM[23]的主要应用。有了SS-CAM,我们可以产生更好的可视化结果和更高的可信度评估,这使得我们可以更直观地分析模型。我们借鉴了SmoothGrad[18]的想法,并将smooth集成到Score-CAM的管道中,以生成“更平滑”的特征定位。较高的“平滑度”有助于对体系结构执行更高级别的分析。在本文中,我们评估了两种平滑方法。该方法的管道如图1所示。在深入了解技术细节之前,我们先定义了探究这个主题的动机以及我们为什么要讨论它。
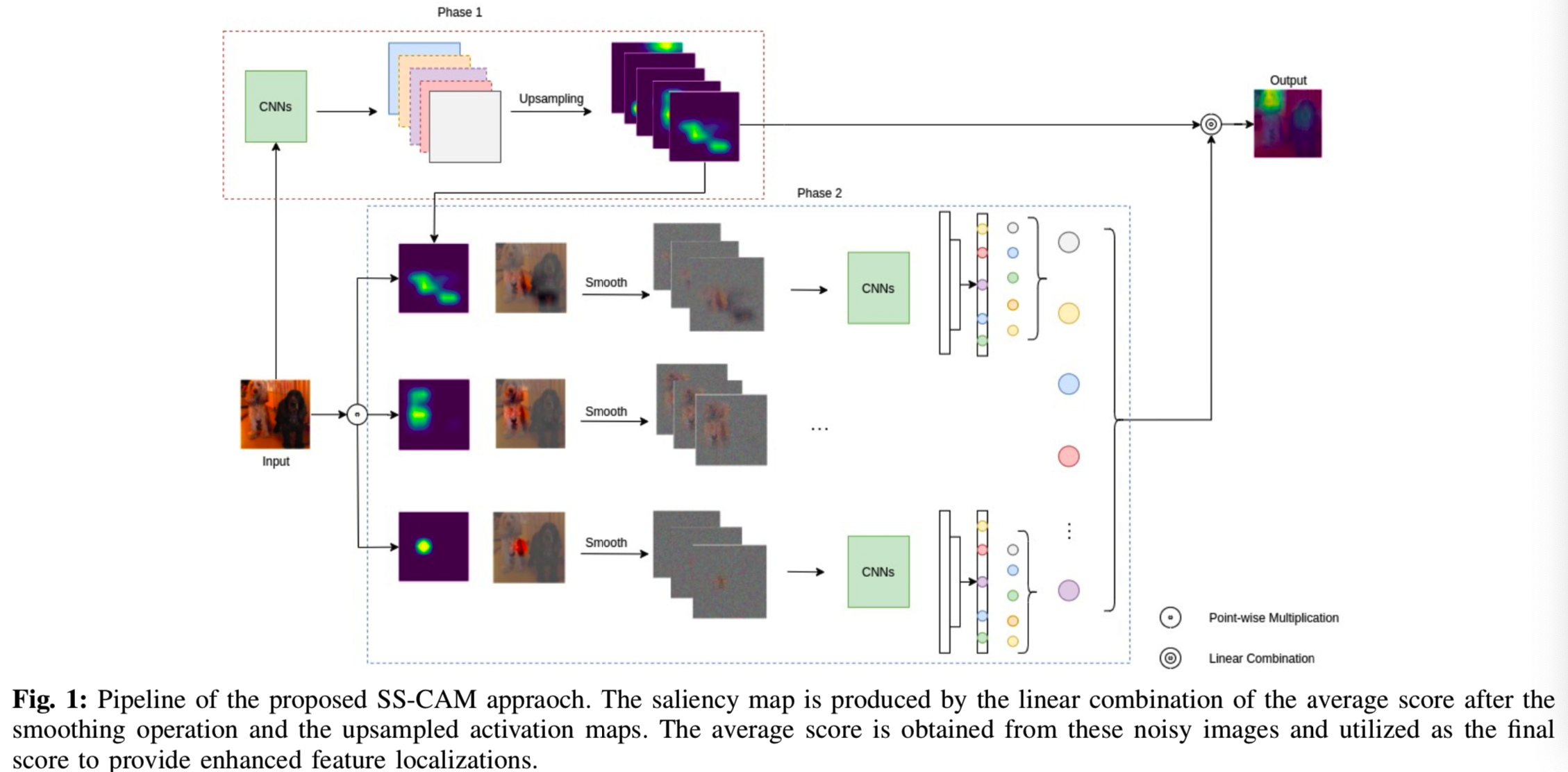
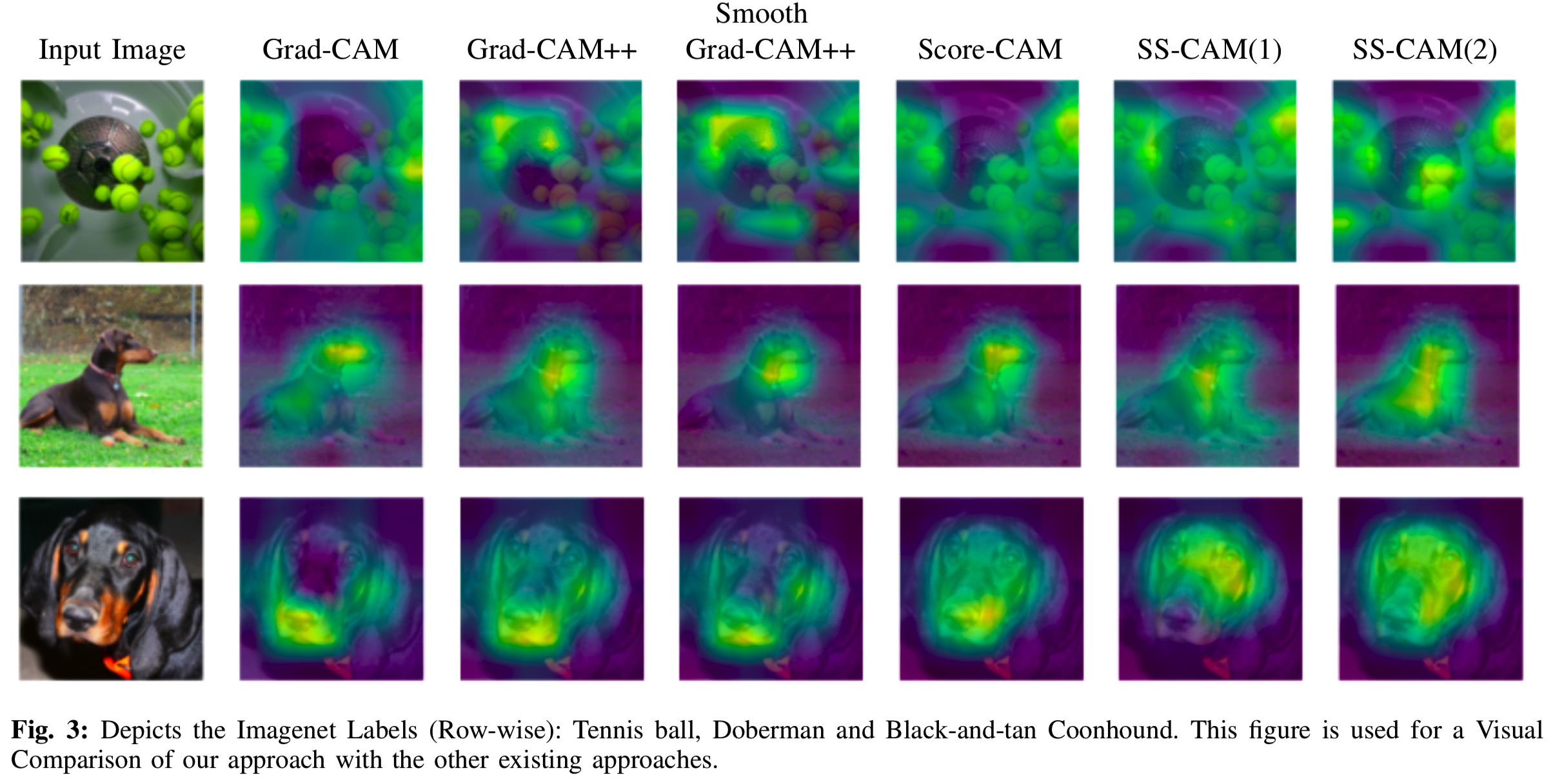
我们选择研究Score-CAM的中的平滑方法以产生更可行的解释。正如您可以看到的,Score-CAM map(图2)显然没有突出显示定位到目标对象(这里是Bull Mastiff)的区域。这可能是由于ReLU非线性函数产生的噪音。这张map覆盖了所有的地方,这使得预测任何类型的结果都非常不可靠,但SS-CAM生成的是一张集中的热图,它完全聚焦在这个物体上。这种集中的热图可以大大增加预测中发现错误的机会。如果一个模型分类错误,错误分类的热图将适当地显示被表示的图像部分,并帮助调试模型。我们现在开始解释我们的方法,首先用CIC测量每个激活map的重要性:
Channel-wise Increase of Confidence(CIC) : 给定一个模型f(x),输入图像X,f的卷积层![]() 的激活map A的第k个channel表示为
的激活map A的第k个channel表示为![]() 。对于基本输入Xb,
。对于基本输入Xb,![]() 的重要性表示为:
的重要性表示为:
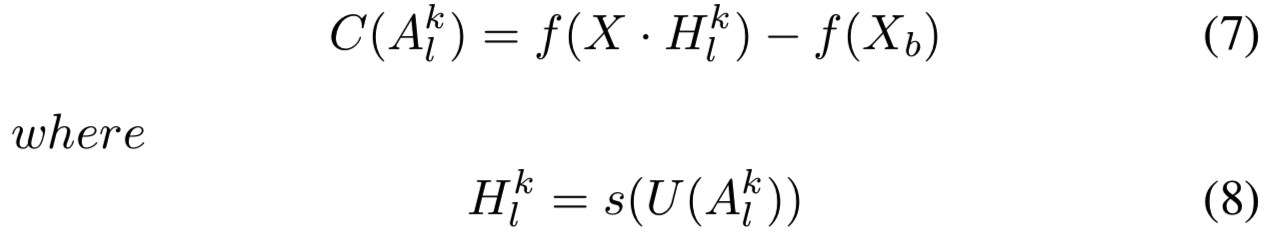
U(.)是将激活map ![]() 上采样到输入大小的操作,s(.)是归一化函数(如等式15),使得元素大小控制在[0,1]范围
上采样到输入大小的操作,s(.)是归一化函数(如等式15),使得元素大小控制在[0,1]范围
类似的CIC方法有DeepLIFT [16]、Average Drop%和[2]的Increase in Confidence。激活maps的重要性由流入最终卷积层的梯度信息来表示。
Smooth on activation map 我们通过在每个激活map Ai中添加高斯噪声来产生N个噪声样本图像。对于每个激活map Ai,生成N个分数,并平均到一个最终分数,这被认为是激活map Ai的重要性。
channel k的卷积层![]() 的激活map A为
的激活map A为![]() 。特征空间(平滑类型1)上光滑的SS-CAM可以描述为:
。特征空间(平滑类型1)上光滑的SS-CAM可以描述为:
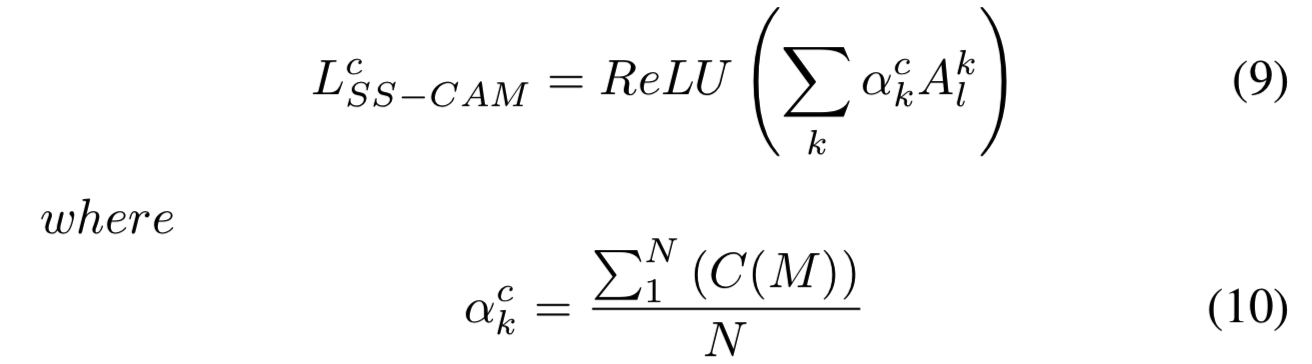
其中,c是感兴趣的类,![]() 是卷积层,
是卷积层,![]() 是激活map
是激活map ![]() 的平均Channel-wise分数,其解释了噪声maps
的平均Channel-wise分数,其解释了噪声maps ![]() 产生的分数。X0即输入图像,
产生的分数。X0即输入图像,![]() 表示层
表示层![]() 的激活map:
的激活map:
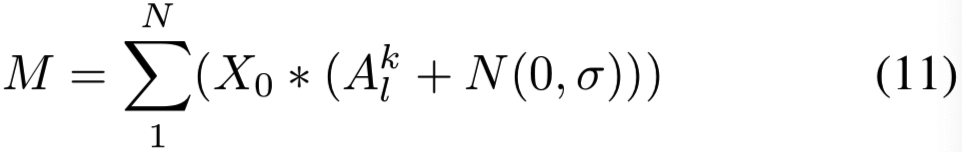
Smooth on input : 卷积层![]() 的第k个channel的激活map A表示为
的第k个channel的激活map A表示为![]() 。在输入空间进行平滑的SS-CAM(平滑类型2)表示为:
。在输入空间进行平滑的SS-CAM(平滑类型2)表示为:

其中c为感兴趣的类,![]() 是卷积层,
是卷积层,![]() 是添加噪声的归一化激活map
是添加噪声的归一化激活map ![]() 的channel-wise 平均分数。X0是输入图像,
的channel-wise 平均分数。X0是输入图像,![]() 表示归一化的输入mask:
表示归一化的输入mask:
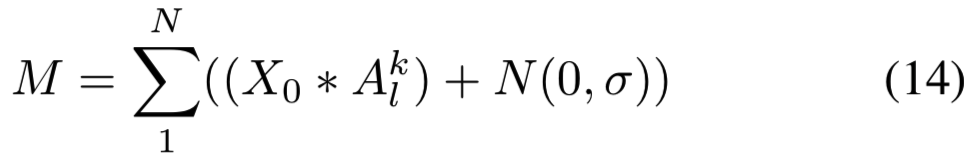
Normalization: 由于我们的目标是聚焦于物体所在的空间区域,因此在归一化map上的二进制mask不会很好,而二进制mask会忽略重要的特征。因此,我们使用与[23]相似的归一化函数来提升特定区域内的特征。
算法中使用的归一化方法如下:

IV. EXPERIMENTS
在这一节中,我们解释我们的实验设置来评估所提出的方法。我们的设置类似于[2][12][23]。首先, 通过A中在ILSVRC 2012 验证集上的可视化结果来定性比较架构的输出。第二,在B中,我们评估在目标识别中架构解释的公平性。接下来,在C中,在从ILSVRC 2012 验证集中的2000张均匀随机选择的图像上,使用Energy-based pointing game([2]中介绍的), 对给定图像中特定类的目标定位实现边界框的评估。最后,我们对Human Trust 评估进行了定量研究,以了解我们的方法如何获得足够的可解释性。
我们的与其他4个现有的CAM技术进行比较,Grad-CAM、Grad-CAM++,Smooth Grad-CAM++和Score-CAM。将图像按一定的大小(224,224,3)进行调整,转换到[0,1]范围,然后使用ImageNet[3]权重(均值向量:[0.485,0.456,0.406]和标准差向量[0.229,0.224,0.225])进行归一化。为简单起见,基线图像Xb被设置为0。
A. Visual Comparison
为了进行这个实验,我们从ILSVRC 2012验证集中随机选择了2000张图像。图3显示了我们的方法与现有的CAM方法(Grad-CAM、Grad-CAM++,Smooth Grad-CAM++和Score-CAM)的比较。这里,我们使用N = 35和σ= 2。D子节进一步深化了这种比较。
B. Faithfulness Evaluations
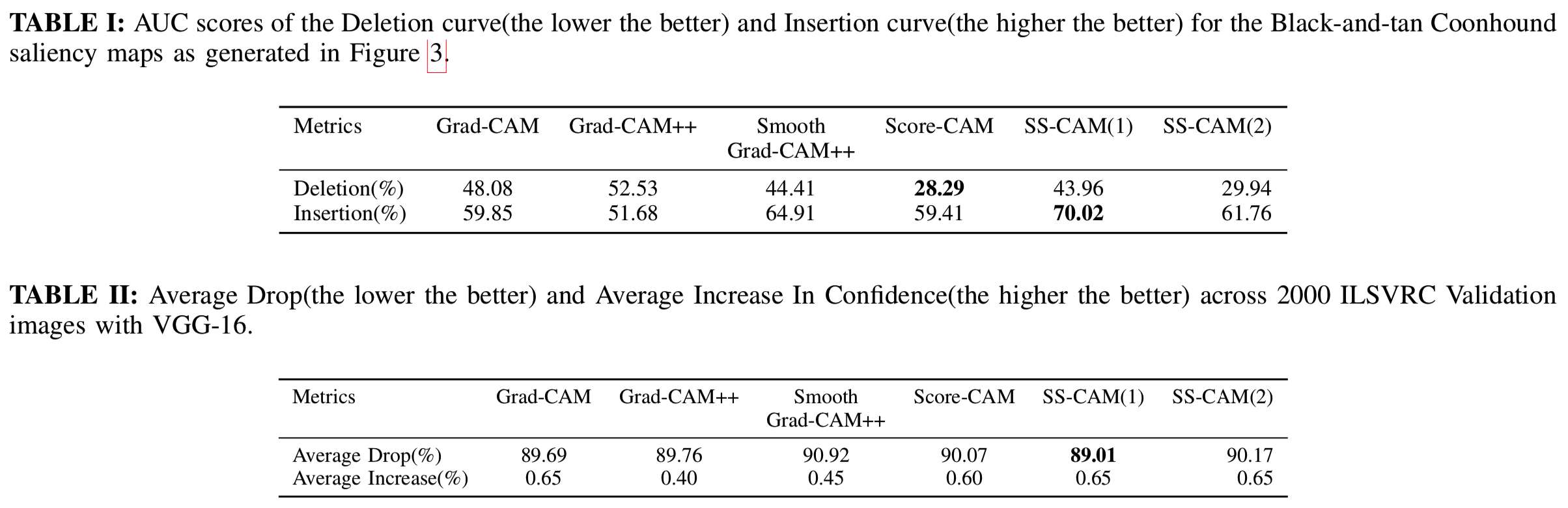
可信度评估是按照Grad-CAM++[2]中的描述进行的,目的是用于目标识别。引入了三个指标,即Average Drop、Average Increase In Confidence 和Win %。
这些指标通过预训练的VGG-16模型对从ILSVRC 2012验证集随机选取的2000幅图像进行评估。我们使用N = 10和σ= 2来进行这个子实验。
Insertion and Deletion Curves被用来计算Area Under Curve(AUC)度量,以了解有多少saliency map像素可以贡献或减少得到的 fractioned maps的分数。我们采用了类似于[12]中引入的设置。Deletion操作显示了按像素销毁map信息的能力。产生的分数的急剧下降和较低的AUC表明了这是一个很好的解释结果。Insertion操作决定了从给定基线重建saliency map的能力。所产生的分数的急剧增加和较高的AUC表明有很好的解释。
1) Average Drop %: Average Drop是指使用输入图像进行的预测与使用saliency map进行的预测之间的最大正差值。式子为
![]() 。这里
。这里![]() 表示使用图像i的类c的预测分数,
表示使用图像i的类c的预测分数,![]() 表示使用输入图像i产生的saliency map在类c的预测分数。
表示使用输入图像i产生的saliency map在类c的预测分数。
2) Increase in Confidence %: The Average Increase in Confidence表示为![]() ,其中Func表示布尔函数,当条件
,其中Func表示布尔函数,当条件![]() <
<![]() 为true时,返回1;否则返回0。这些标注符号表示的意义如上面所说的Average Drop相同。
为true时,返回1;否则返回0。这些标注符号表示的意义如上面所说的Average Drop相同。
3) Win %: Win percentag 是指SS-CAM生成的解释map的模型置信度的降低。这个指标将SS-CAM(1)和SS-CAM(2)map的置信度与Score-CAM[23]map生成的置信度进行比较。与Score-CAM相比时,SS-CAM(1)的结果说明有49.8%的分数偏向于它;SS-CAM(2)与Score-CAM相比时,显示了Win %为47.8%上下的结果。本实验采用N=10和σ=2。
表二描述了在Average Drop和Average Increase in Confidence中得到的类似的性能。表1从Deletion曲线来看,SS-CAM(2)略低于Score-CAM;而SS-CAM(1)在Insertion曲线表现很好,增加了5%。
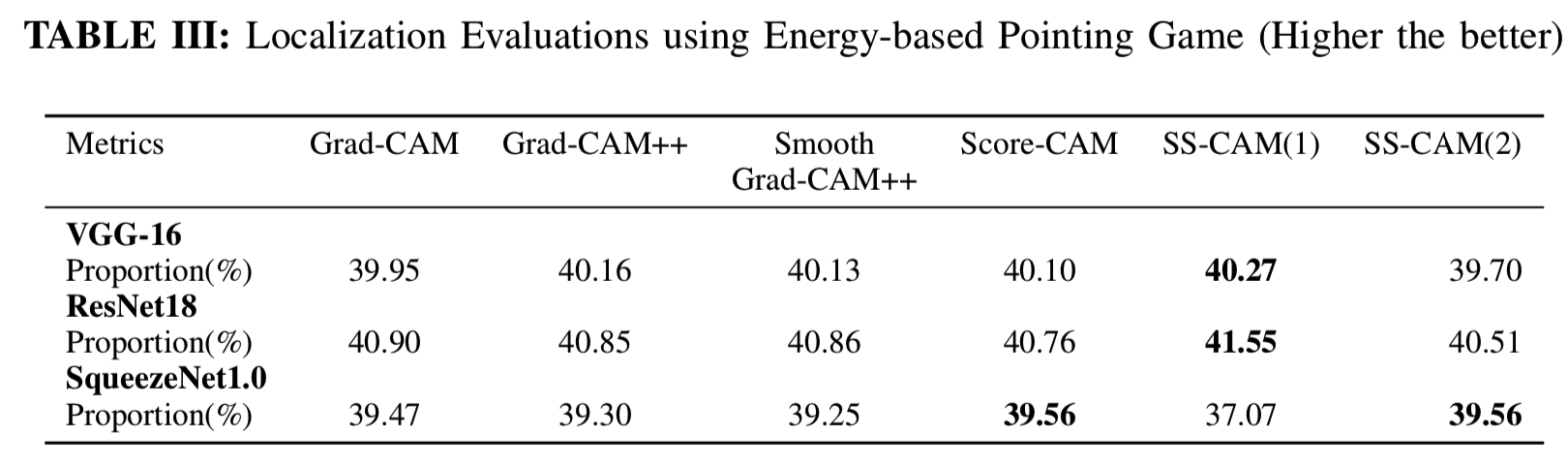
C. Localization Evaluations
边界框计算在本节中完成。我们采用了类似的指标,就像在Score-CAM中指定的那样,叫做the Energy-based pointing game。在这里,saliency map的energy的数量是通过找出有多少saliency map落在边界框内来计算的。具体地说,输入是将边界框的内部标记为1,边界框外的区域标记为0。然后,将此输入与生成的saliency map相乘并求和去计算比例比,式子为
![]() 。使用了三个预训练模型——VGG-16、ResNet-18(Residual Network with 18-layers) [6] 和SqueezeNet1.0 [9] 模型在从ILSVRC 2012验证集随机选取的2000幅图像上实现 Energy-based pointing game。设置N=10和σ=2来实现该实验。虽然差距很小,表3显示3个架构中的两个架构有了更好的定位效果
。使用了三个预训练模型——VGG-16、ResNet-18(Residual Network with 18-layers) [6] 和SqueezeNet1.0 [9] 模型在从ILSVRC 2012验证集随机选取的2000幅图像上实现 Energy-based pointing game。设置N=10和σ=2来实现该实验。虽然差距很小,表3显示3个架构中的两个架构有了更好的定位效果
D. Evaluating Human Trust
在本实验中,我们在盲评的基础上评估所产生的视觉解释的可信度或可解释性。我们从ILSVRC 2012验证数据集[3]的1000个类中随机选择5个类,生成50幅解释map,总计250幅图像。Grad-CAM maps被视为生成的可视化maps的基线。这些maps和输入的图像一起展示给10名受试者(他们没有这个领域或深度学习的知识),并证明哪张map能更深入地观察捕获的物体,从而得到更多的信任和更高的可解释性。使用一个预训练的VGG-16模型来创建解释maps。我们随机选择5个类,因为这将使所有类从1000个ImageNet类中被选中的概率相等,因此,能消除任何偏差。
对于每一幅图像,生成6个解释maps,分别是Grad-CAM、Grad-CAM++,Smooth Grad-CAM++, Score-CAM, SS-CAM(1)和SS-CAM(2)。受试者被要求选择哪张地图能更好地解释图像中的物体(不知道哪张地图对应于哪一种方法)。这些回答经过归一化处理,使每张图像的总分等于1。然后把这些归一化的分数加起来,这样每个subject的最高分数就可以达到250分。记录的响应总数为10*250 = 2500个响应。如果受试者不能辨别视觉maps,也会提供一个“不确定”选项。表4显示了使用该评价指标所获得的相应分数。我们使用N = 35和σ= 2进行这个实验。表4所示的值明显地对SS-CAM(2)方法提出了更高的响应,从而得出了更高的人类可解释性和可信度的结论。

V. CONCLUSION
我们提出的方法显著地增强了目标类特征在图像中的定位,从而更好地解释了图像。在这方面,我们的方法使用Energy-based pointing game(表3)得到的评估结果远高于现有的CAM的方法。(表1)提出的更高的AUC分数进一步说明了我们的技术在可信度评估上的能力,(表4)显示了在Human Trust评估上,我们具有的显著优势。Insertion曲线(图4)还表明,SS-CAM具有很大的潜力,因为随着像素的插入,得分显著增加。
使用参数为σ[5]、[18]的高斯噪声平滑了attribution maps的输入空间,构建视觉清晰的attribution maps。如果参数σ不定,发现如果σ很低,产生的分数很“noisy”,因为得到的attribution maps趋向于太noisy;如果参数σ过高,生成的attribution maps在不同类中将更泛化,将意味着maps会变得无用和无关紧要。因此,我们精心选择了一个理想的σ来进行评估,以获得最佳的结果。
与Grad-CAM[15]相比,SS-CAM的局限性在于它需要花费大量的时间来处理这些解释。这是由于在上采样阶段迭代每个特征图来计算N个噪声样本的分数,并平均它们以生成更平滑的attribution maps。但应该注意的是,这些技术的应用主要集中在一个单一的错误就可能造成巨大伤害和损害的环境中。因此,我们优先考虑结果,而不是获得同样的结果所花费的时间。
