mysql 数据管理
数据库中的不同表负责不同业务的管理
数据库:是表的集合,是一个大的分类
表:是一个小的分类
mysql -u root -p 登录mysql的命令
db_name : 代表的数据库的名字
登录mysql: mysql -u root -p
1.显示服务器上所有已有的数据库:
show databases;
2.在服务器中创建自己的数据库
create database;
create database character set utf8;创建的数据库支持中文
3.如何切换到指定的数据库
use db_name;
4.如何删除已有数据库
drop database db_name;
如何在数据库中建立数据表
数据表是一个二维表格(行,列)
一行代表一条数据
每一个列代表的是当前一条数据的字段

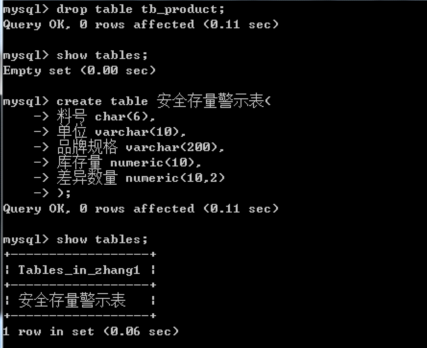
建表的基本语法: create table tb_name(字段1 类型,字段2 类型)
主键:唯一的识别一条记录的字段,是不重复的 primary key 主键
自增:某个字段不需要手动填写数据,而是通过系统分配的整数(每一条数据分配的值都是前一条数据的增量)auto_increment 自增
非空:字段设置为非空属性时,填写数据时要求该字段为必填项 not null
默认值:向表中填写数据时,字段不写入数据时,会默认填充值 default
comment ‘’ 字段说明
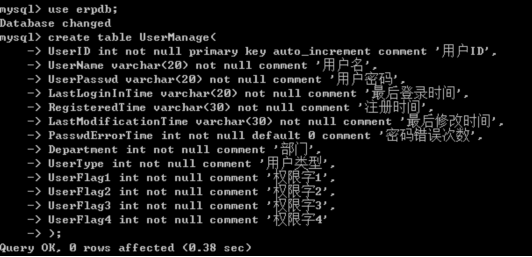
插入数据: 方法1: insert tb_name values() 适用于全记录插入
注意:按表中字段顺序插入数据
方法2:
insert tb_name (字段1,字段2,……) values(‘字段1的值’,‘字段2的值’,……);
对指定的字段进行数据的插入操作
如果是字符类型的数据要用’’号包含要插入的数据
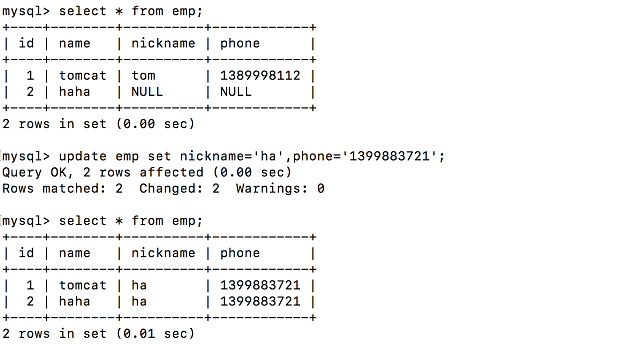
修改表中数据
upadate tb_name set 字段1=值,字段2=值 where 条件
1.把表中的要修改的字段,所有的指定字段都给修改了
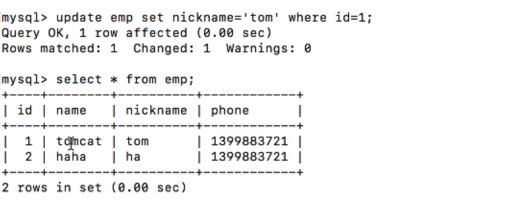
2.指定要修改的是哪行的字段,只修改指定行的字段
删除表中的指定记录
delete语法
delete from tb_name where 条件
删除掉后,但系统会记住自增量(id设的自增),再添加一条数据的时候,id为3,不是2.
查看全表信息select * from tb_name
投影
select 字段1,字段2,…… from tb_name
在查询时,将字段别名
select id '编号', title '主题' from tb_name;
带筛选条件的查询
select 字段 from tb_name where 条件 title=‘’
模糊查询 select 字段 from tb_name where 条件 title like‘%公告’
select 字段 from tb_name where 条件 title like‘_公告’
%是通配符,可以代表任意多个字符
_只代表一个未知字符
两个条件都需满足时,两个条件之间 用and 链接
两个条件只需满足任意一个两个条件之间 用or 链接:
任何查询操作的反查询都可以用 not 列如:not like
not like 满足的条件是 “不是…”
count是统计函数或者叫聚合函数,作用:统计当前记录的个数
只显示统计的结果,不显示查询的具体的信息
sum求和
select sum()from tb_name
avg 求平均值
select avg()from tb_name
最大值 max
select max()from tb_name
最小值 min
select min()from tb_name
升序排序 asc(可以省略)
select * from tb_name order by 字段
降序排序 desc
select * from tb_name order by 字段 desc
第一排序,第二排序
当第一排序出现有部分行字段相同的情况时,可以进行第二排序
select * from tb_name order by age,id desc
多个排序用 ,(逗号)分隔
group by 分组
先会把指定的字段里面相同的数据划分成一组,然后再进行显示
select 字段名 from tb_name group by 字段名;
注意:在分组的时候做其他字段的投影是没意义的
分组可以和聚合函数一起使用
select 字段名,count(*) from tb_name group by 字段名
having 分组后的筛选(不分组的时候筛选用where)
两表关联,一定有主从之分,从主表建立一个新的字段以便关联到从表,主表中新建的这个用于关联的字段称为外键。
如何建这个外键?
- 在主表中新建一个字段
- 新建的这个字段应于从表的主键类型相同,并关联到从表的主键
一次查询,涉及到的数据来自多张表
join 多表联合查询 多表查询时:先关联在查询
语法:select from tb_name inner join tb_name on 主表的外键=从表的主键
where放在关联之后
子查询
select * from tb_name where 字段 = (select 字段名 from tb_name2 where 字段2='条件');
将分步操作合在一起,
子查询中in的用法(包含)
select * from tb_name where 字段 in (select 字段名 from tb_name2 where 字段2='条件');
limit 限制查询显示结果
limit 5 查询显示前5条记录
在子查询中使用limit 外层不能使用 in、all…
从第五条开始显示三条 limit 4,2
注:mysql中两个生日日期(年月日)相减时,得到的是年与年之间相减的数值 如果得到的数字为‘0’那就是同年
在mysql中取日期只取年用 year 只取月用month
表的查询结果还是表
语法:(select * from tb_name) as
将两个结构相同的查询结果进行合并 union