叮~
终于考完试啦!这段时间忙于复习,好久没刷题了,现在又要开始整大作业和各种汇报,先来弄机器学习大作业呀!
师兄早就叮嘱要做比赛,结果一直拖着没有做,现在趁着做大作业,先来上上手,kaggle,天池和DC都是数据科学的比赛,但是看了很多知乎问答后,还是决定来做kaggle呀!
kaggle入门级别题目:(1)数字识别(2)泰坦尼克号(3)放假预测
第一眼泰坦尼克号就吸引我啦!所以先来做泰坦尼克号吧,分析了题目之后发现其实这就是一个二分类问题,适用于二分类问题的机器学习算法辣么多,但是第一想法竟然是用决策树,可能是这一题有给出来很多特征,而决策树就是不断进行特征选择进行分类,所以就暂时决定用决策树做一下,之后会用其他方法来进行对比。
但是没有用过python呀,先当了人家的kernel抄人家的代码边看边学了!
不得不说scikit-learn(sklearn)真是强大,机器学习算法库,各种模型都已经在里面了,直接调用就可以,但是之后还要导入xgboost库,网上查的很多需要额外下载软件,好不容易找到了一篇直接去https://www.lfd.uci.edu/~gohlke/pythonlibs/上下载对应版本的xgboost,然后在anaconda prompt上“pip install 下载的文件名”安装即可,最后提示成功的话再用pip list或conda list查看已经有的库即可。
接下来就是代码里的各种知识点啦:
(1)numpy(numerical python):会发现基本上机器学习或python代码中都会导入该库,它是python进行科学计算的基础软件包,支持高级大量的维度计算与矩阵计算,对数组运算也支持大量的函数库,运算效率极好,是大量机器学习的基础库。
(2)pandas:是基于Numpy的一种工具,其中有两类非常重要的数据结构,序列Series和数据框DataFrame;前者类似于numpy中的一维数组,除了一维数组中的方法,还可以通过索引标签的方式获取数据,还具有索引的自动对齐功能;DataFrame类似于numpy中的二维数组。
(3)re:本模块提供了正则表达式匹配操作。
(4)matplotlib:是python的绘图库;使用%matplotlib inline是IPython的一组预定义的魔法函数,可以使用命令行样式调用,将matplotlib的图表直接嵌入之中。
(5)seaborn:以matplotlib为底层,更容易定制化作图的库,可以看做是matplotlib的补充。
(6)plotly:一个强大的开源数据可视化框架,通过构建基于浏览器显示的web形式的可交互图表来展示信息,可创建多达数十种精美的图表和地图
而且有在线和离线两种方式,在线绘图需要注册账号获取API key,离线绘图plotly.offline.plot()方式在当前工作目录下生成html格式的图像文件并自动打开。
(7)subprocess:启动一个新的进程并且与之通信,其中call和check_call都是父进程等待子进程执行命令,返回执行命令的状态码,但是后者出现错误时会进行报错,前者不会。
(8)PIL:Python Imaging Library是python的图像处理标准库了。
导入的相关库先记下这么多了,接下来要研究数据了!
拿到一个问题最先进行的就是分析数据!!!分析数据特征进行特征工程:
泰坦尼克号问题中给出了“train.csv”和“test.csv”两个数据文件,一个用来训练模型,一个用来测试。其中
train.csv文件中的数据共给出了数据的这几个特征:

给出的特征从直觉上看“Pclass”(乘客等级)、"Sex"、“Age”是最直接有用的几个数据特征;“Ticket”(船票号)、“Fare”(船票价格)、“Cabin”(舱位)是间接因素,可以判断乘客的经济水平和“Pclass”相关;另外几个特征“Name”、“SibSp”(兄弟姐妹及配偶的个数)、“Parch”(父母及子女的个数)、“Embarked”(登船口岸)直觉上没有看出来对预测有什么关系,还需要进一步分析。
另外要查看给出的数据中缺失值的数量,看是否需要进行缺失值填补:
(1)Fare有1个缺失值;(2)Age有263个缺失值(这个缺失引起注意)(3)Cabin有1014个缺失值,缺失较多不能直接填补;(4)Embarked有两个缺失值可以直接清除或默认值填补.
为了不影响之后原始数据的使用,先对原始数据进行复制备份,而不是简单的引用:
(1)使用copy()方法:original_data=train.copy();
(2)判断乘客是否拥有舱位:使用lambda魔法函数,在这里就使用一个if...else...的方法;
(3)生成新的特征:将“SibSp”和“Parch”汇总得到乘客的家庭成员总个数,即“FamilySize”新特征
(4)从“FamilySize”中生成“IsAlone”的新特征:使用pandas中的loc函数(使用行标签索引数据)和iloc函数的区别(通过行号索引行数据).
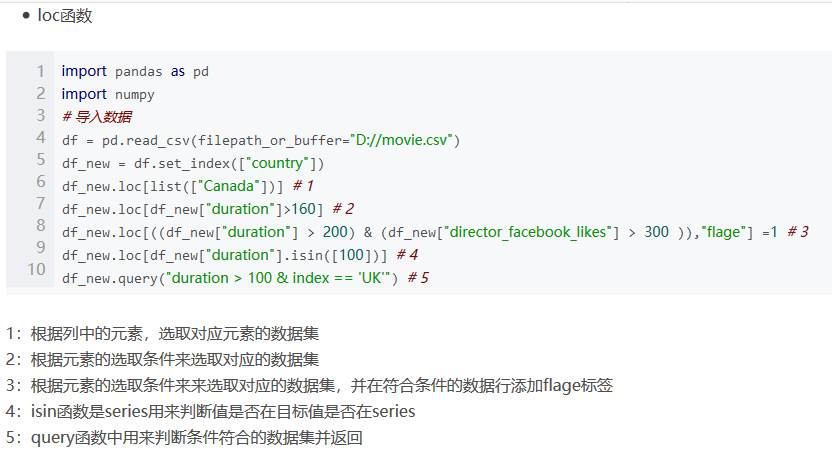
(5)对于Embarked中的缺失值,使用“S”作为缺省值填补;
(6)对于Fare中的缺失值,使用Fare的中值作为缺省值填补;
(7)对于Age中的缺失值,比较麻烦,因为Age是一个比较重要的数据特征,这里使用np.random.randint(low,high,size)函数返回一个从[low,high)的随机整形数。同时使用np.isnan()函数来获取数据中的空值,另外pd.isnull()也可以用来看行空值检测,只是前者多用来单个值的检验,后者用于对一个DataFrame或Series整体进行检验。
(8)对于Name特征,提取出有关的Title信息(lady,miss,sir等):需要使用正则表达式,其中group()为返回匹配正则表达式部分,然后将匹配的部分title信息替换为“称呼”信息。
特征提取和生成之后,将数据中的字符型都转换为整数型方便下面的统计。