作业要求:https://edu.cnblogs.com/campus/nenu/SWE2017FALL/homework/922
本次作业的重点是确立核心功能,确立之后其他功能都是在核心功能之外的拓展;而难点则是文件流的处理,这是我比较薄弱的部分,因而对我来说文件流的处理是我所认为的难点。
Part 1 代码版本控制
coding :https://git.coding.net/137911934/SE20170914.git
Part 2 主要思路
1. 确定作业要求:四个功能都围绕词频统计进行了不同的拓展;
2. 确定开发语言:C/C++是我最为熟悉的语言,因此选择C/C++,开发环境为codeblocks 16.10;
3. 确定数据结构:利用map以及vector进行统计是C/C++开发中最为适合的数据结构;
4. 确定之后进行代码的编写。
Part 3 功能实现
我选取 map 这个数据结构进行编程的原因,是因为Map作为STL的一个关联容器,它具有两个元素 key 和 value ,每一个 key 值都是唯一的,且具有一个对应的 value 值。所以每当我们读取到一个单词,就可以在对应的 value 值进行增加,进而达到词频统计的目的。
0. 准备工作
1)降序排序函数
由于 map 不能直接进行排序,需要通过将 map 中的数据转存到 vector 中,利用库函数进行排序。
排序控制条件代码:
int cmp(const PAIR& x, const PAIR& y)//compare { return x.second > y.second; }
转存到 vector 以及排序代码:
for (map<string,int>::iterator curr = mp.begin(); curr != mp.end(); ++curr) { vt.push_back(make_pair(curr->first, curr->second)); } sort(vt.begin(), vt.end(), cmp);
2)格式化输入输出
for(int i = 0 ; i<(vt.size()>10?10:vt.size()); i++) { cout<<setw(8)<<left<<vt[i].first; cout<<" " <<setw(8)<<right<<vt[i].second << endl; }
3)从文件中读取数据
system("cmd /c dir F:\software\*.txt /a-d /b /s >F:\software\output.txt"); ifstream myfile("F:\software\output.txt");
1. 读取 test.txt 文档中的内容,统计词频
本部分的重点就是实现最基础的功能,才能在其他功能中对其进行拓展;由于是对于map最基础的应用,所以没有难点。

运行截图
核心代码:
num = 0; mp.erase(mp.begin(),mp.end()); vt.erase(vt.begin(),vt.end()); //cin.get(); ifstream fin(name.c_str());//read the file named 'name' // cout << name << endl; // The big change //GoDie while(fin>>s)//input the file { //DEBUG; int len=s.size(); //cout <<s<<"~~"<< endl; if (ispunct(s[len-1])) { s.erase(len-1,1); } std::transform(s.begin(),s.end(),s.begin(),::tolower); // cout<<s<< endl; mp[s]++; if(mp[s] == 1) num ++; } //sort for (map<string,int>::iterator curr = mp.begin(); curr != mp.end(); ++curr) { vt.push_back(make_pair(curr->first, curr->second)); } sort(vt.begin(), vt.end(), cmp); // if(num == 1) printf("total 1 word "); else if(num != 0) printf("total %d words ",num); cout <<endl; for(int i = 0 ; i<(vt.size()>10?10:vt.size()); i++) { cout<<setw(8)<<left<<vt[i].first; cout<<" " <<setw(8)<<right<<vt[i].second << endl; }
2. 读取大文件内容,统计并输出词频Top 10
本部分功能是为了读取具有大量单词的文档的统计,在本部分中我发现功能1中我没有注意到的一个Bug,就是区分大小写,所以导致第一遍调试中单词总数变大,词频变低。
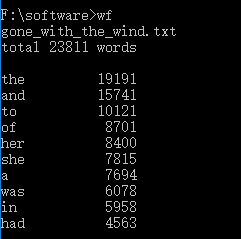
运行截图
核心代码与功能1相同。
3. 遍历文件夹中所有 .txt 后缀文件进行词频统计
本部分重点是遍历整个文件夹,所以我利用了库函数提取文件夹中所有 .txt 后缀文件的路径,并对每个路径进行处理,去掉路径仅留下文件名并添加 .txt 后缀,利用一个结构体储存所有处理后的“文件名 + .txt ",最后利用一个循环遍历所有结构体内的文件名进行词频统计。
1)提取文件名
myfile.getline (buffer,1024); int len = strlen(buffer); // char filename[50]; int cnt = 0; bool tmp = false; // memset(filename,0,50); for(int i = len - 1; i >= 0 ; i --) //get the name of files { //cout << buffer[i] << endl; if(buffer[i] == '.') { for(int j = i-1; buffer[j] != '\'; j --) { fn[Cnt].s[cnt] = buffer[j]; cnt ++; } } //if(tmp) break; }
2)添加 .txt 后缀
for(int i = 0; i < Cnt-1 ; i ++) { swap_c(fn[i].s); strcat(fn[i].s,".txt"); }
这里需要注意的是,在提取文件名的过程中由于是从后向前进行处理的,所以储存起来是倒序的,所以需要进行字符串的翻转。
void swap_c(char s[50]) //Swap { int len = strlen(s); for(int i = 0,j = len-1; i < j ; i ++,j--) { char c; c = s[i]; s[i] = s[j]; s[j] = c; } }
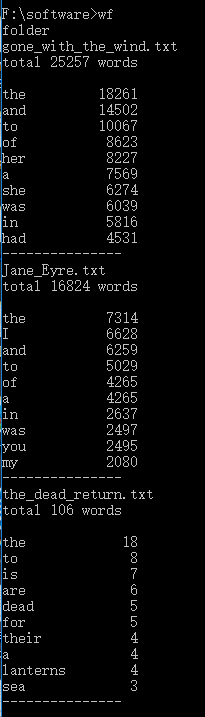
程序截图
4. 输入一段文章,进行词频统计
由于我编写的代码都是利用文件流进行处理,我没有完成如何从文件流将内容进行读取进行词频统计,所以功能4没有完成。
Part 4 每周例行报告
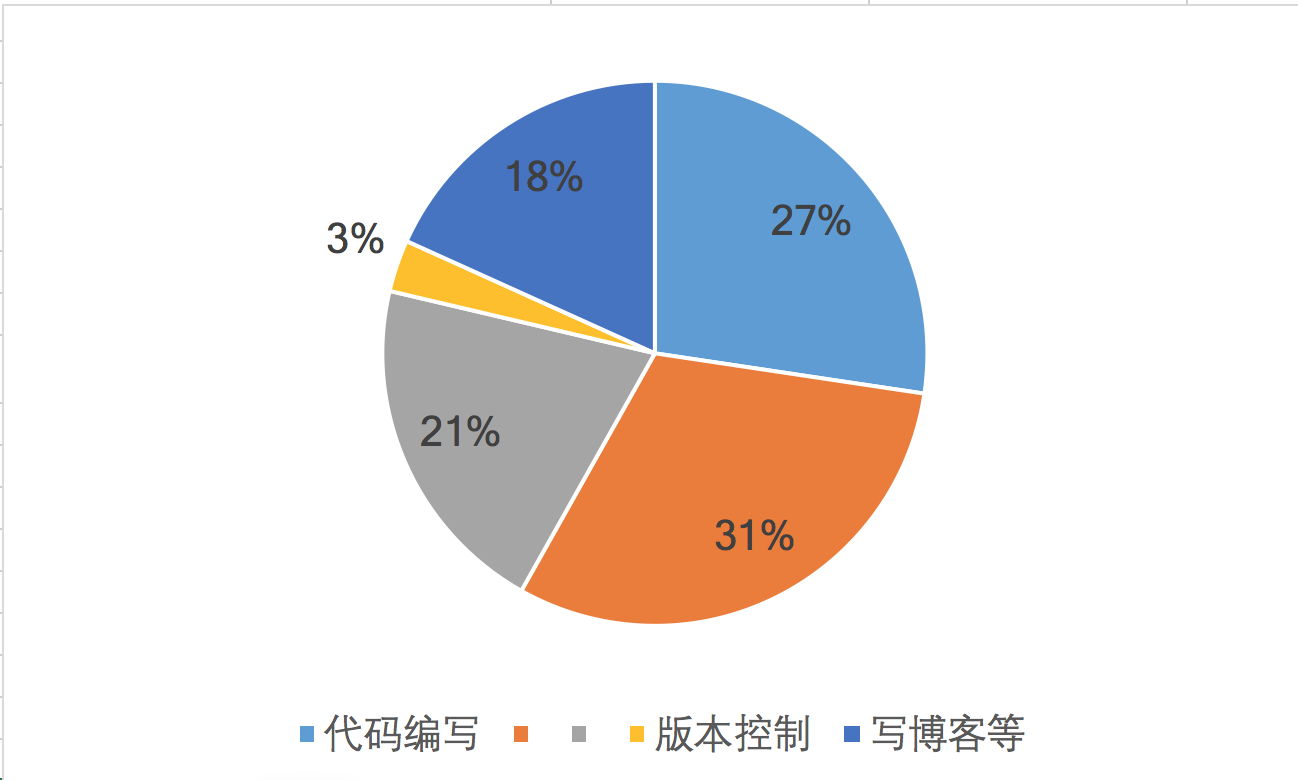
1.本周PSP

预计完成功能时间为630分钟,实际花费时间为690分钟。主要是因为第一个考虑的方法是使用字典树这个数据结构进行代码编写,后来发现字典树不是处理此类问题的最佳方案,改为使用 Map 进行编写。
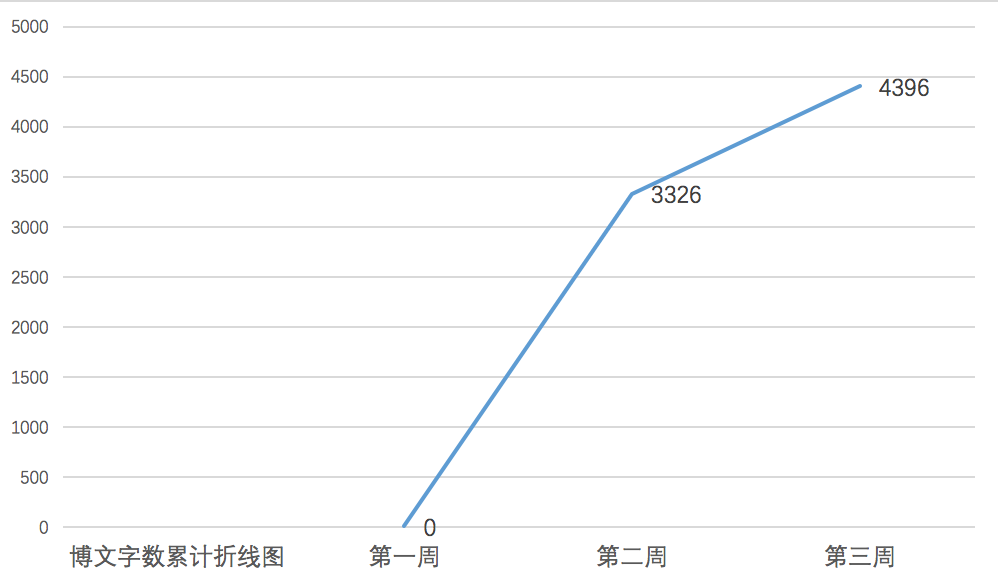
2. 本周进度条

3.累计进度图
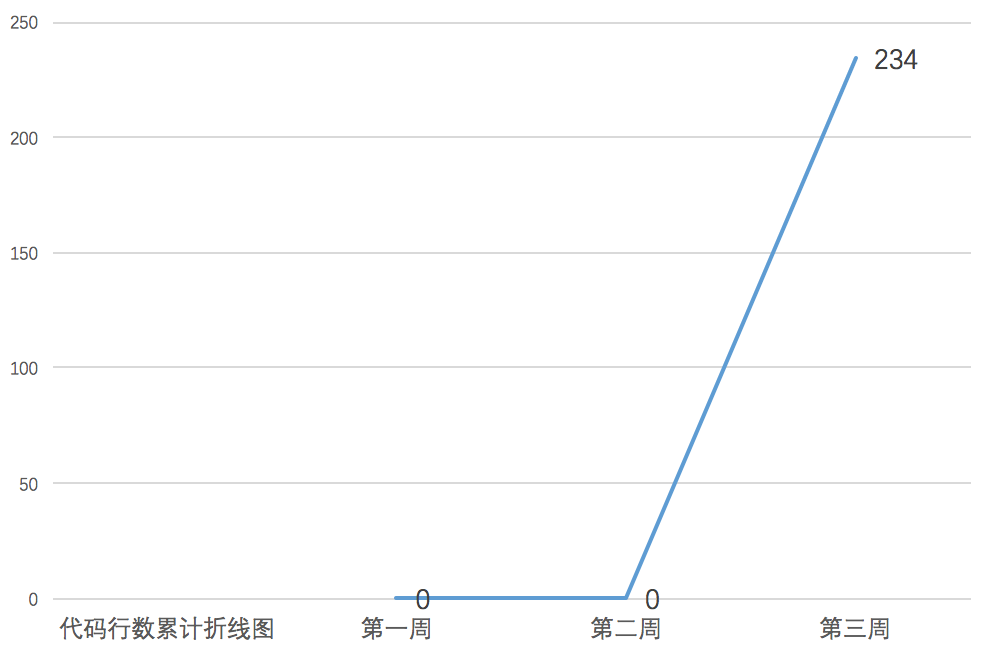
4. 本周PSP饼状图