补充模块的循环导入的问题
两种解决办法:
第一种:变量的名字全部往上放,导入全部往下放,保证名字全部存在
第二种:封装在函数里面,函数在定义阶段,只检测代码不运行代码
包的使用
1.什么是包
包就是一个含有__init__.py文件的文件夹
2.为何要用包
3.如何用包
导包其实是在导__init__ ,可以把分散于子文件里的功能,全部拿到__init__里面,从而屏蔽给使用者在使用上的变动
环境变量在执行文件夹下
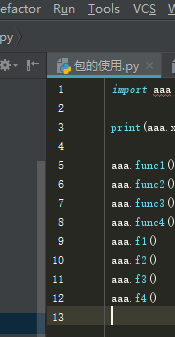

绝对导入:
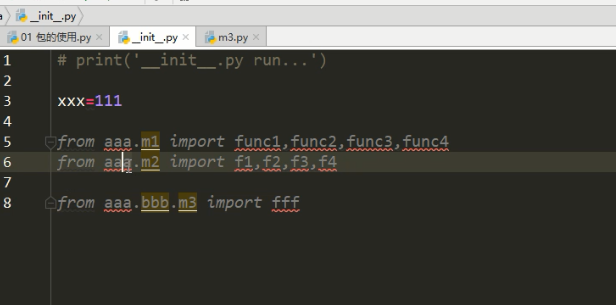
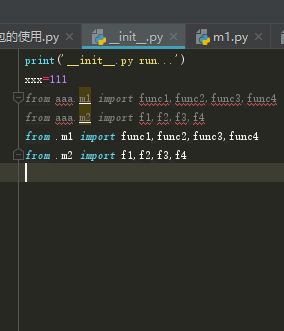
相对导入 :
绝对导入时通用的,相对导入是仅限在包内使用
1.什么是序列化
序列化就是将内存中的数据类型转成另外一种格式
即:
字典--------------序列化--------------其他的格式--------------存到硬盘
硬盘------读取-------->其他格式----------反序列化------->字典
2.为什么要序列化
1.持久保存程序的运行状态
2.数据的跨平台交互
3.如何序列化
json:
优点:这种格式是一种通用的格式,所有的编程语言都能识别
缺点: 不能识别所有的python类型
强调:json格式不能识别单引号
pickle:
优点:能识别所有的python类型
缺点:只能被python这门语言识别
json模块与pickle模块实例
# ========================json
import json
#
dic={'k1':True,'k2':10,'k3':'egon','k4':'你好啊'}
#
# # # 序列化
dic_json=json.dumps(dic)
print(dic_json,type(dic_json)) #存的时候是json读的时候也是json 把他存到文件中,把你好啊存成json格式
# #
# # # 持久化
# with open('a.json',mode='wt',encoding='utf-8') as f:
# f.write(dic_json)
# 序列化+持久化
# with open('a.json',mode='wt',encoding='utf-8') as f:
# json.dump(dic,f)
# import json
# # 从文件中读取json格式化的字符
# with open('a.json',mode='rt',encoding='utf-8') as f:
# dic_json=f.read()
#
# # 反序列化
# dic=json.loads(dic_json)
# print(dic,dic['k1'])
# 读取文件内容+发序列化
# with open('a.json',mode='rt',encoding='utf-8') as f:
# dic=json.load(f)
# print(dic['k1'])
# ========================pickle
import pickle
dic={'k1':True,'k2':10,'k3':'egon','k4':'你好啊',}
#===========>1 pickle.dumps与pickle.loads
# dic_pkl=pickle.dumps({1,2,3,4})
# # print(dic_pkl)
#
# with open('b.pkl',mode='wb') as f:
# f.write(dic_pkl)
# with open('b.pkl',mode='rb') as f:
# s_pkl=f.read()
# s=pickle.loads(s_pkl)
# print(type(s))
#===========>2 pickle.dump与pickle.load
# with open('c.pkl',mode='wb') as f:
# pickle.dump(dic,f)
with open('c.pkl',mode='rb') as f:
dic=pickle.load(f)
print(dic,type(dic))
时间模块

import time
时间分为三种形式
1、时间戳,说白了就是时间的秒数表达形式
print(time.time())
start_time=time.time()
time.sleep(3)
stop_time=time.time()
print(stop_time-start_time)
2、格式化的字符串,更多是给人看的时间
print(time.strftime('%Y-%m-%d %H:%M:%S %p'))
print(time.strftime('%Y-%m-%d %X %p'))
3、struct_time对象
print(time.localtime()) # 上海:东八区
print(time.localtime().tm_year)
print(time.localtime().tm_mday)
print(time.gmtime()) # UTC时区 世界标准时区
了解的知识
print(time.localtime(1111111111).tm_hour)
print(time.gmtime(1111111111).tm_hour)
print(time.mktime(time.localtime()))
print(time.strftime('%Y/%m/%d',time.localtime()))
print(time.strptime('2017/04/08','%Y/%m/%d'))
print(time.asctime(time.localtime()))
print(time.ctime(12312312321))
datetime模块
import datetime # print(datetime.datetime.now()) # print(datetime.datetime.now() + datetime.timedelta(days=3)) #3天后 # print(datetime.datetime.now() + datetime.timedelta(days=-3)) #3天前 # print(datetime.datetime.now() + datetime.timedelta(hours=3)) #3个月之后 # print(datetime.datetime.now() + datetime.timedelta(seconds=111)) # current_time=datetime.datetime.now() # print(current_time.replace(year=1977)) # print(datetime.date.fromtimestamp(1111111111))
随机模块(random模块)
import random print(random.random())#(0,1)----float 大于0且小于1之间的小数 print(random.randint(1,3)) #[1,3] 大于等于1且小于等于3之间的整数 print(random.randrange(1,3)) #[1,3) 大于等于1且小于3之间的整数 print(random.choice([1,'23',[4,5]]))#1或者23或者[4,5] print(random.sample([1,'23',[4,5]],2))#列表元素任意2个组合 print(random.uniform(1,3))#大于1小于3的小数,如1.927109612082716 item=[1,3,5,7,9] random.shuffle(item) #打乱item的顺序,相当于"洗牌" print(item)
随机验证码
import random
def make_code(n):
res=''
for i in range(n):
s1=chr(random.randint(65,90))
s2=str(random.randint(0,9))
res+=random.choice([s1,s2])
return res
print(make_code(9))
打印进度条
print('[ ]')
print('[## ]')
print('[### ]')
print('[#### ]')
print('[##### ]')
print('[%-50s]' %'#')
print('[%-50s]' %'##')
print('[%-50s]' %'###')
第一个%是取消第二个%号的特殊意义的
num=30
print('%s%%' %num)
width=30
print(('[%%-%ds]' %width) %'#')
print(('[%%-%ds]' %width) %'##')
print(('[%%-%ds]' %width) %'###')
def progress(percent,width=50):
if percent > 1:
percent=1
show_str=('[%%-%ds]' %width) %(int(width*percent) * '#')
print('
%s %d%%' %(show_str,int(100*percent)),end='')
import time
recv_size=0
total_size=8097
while recv_size < total_size:
time.sleep(0.1)
recv_size+=8096
percent=recv_size / total_size
progress(percent)
shutil模块
import shutil
import time
ret = shutil.make_archive(
"day15_bak_%s" %time.strftime('%Y-%m-%d'),
'gztar',
root_dir=r'D:codeSH_fullstack_s1day15'
)
import tarfile
t=tarfile.open('day15_bak_2018-04-08.tar.gz','r')
t.extractall(r'D:codeSH_fullstack_s1day16解包目录')
t.close()
shevle模块
xml模块