https://blog.csdn.net/lyxuefeng/article/details/79776751
使用爬虫爬取网页经常遇到各种编码问题,因此产生乱码
1.首先先来网页编码是utf-8的:
以百度首页为例:
使用requests库
使用urllib库
接下来介绍encode()和decode()方法
encode()用于解码,decode()方法用于编码
注:python3默认编码为utf-8
例1:
<class 'str'>
b'xd6xd0xbbxaa'
b'xe4xb8xadxe5x8dx8e'
UnicodeEncodeError: 'latin-1' codec can't encode characters in position 0-1: ordinal not in range(256)
为什么第四个报错?
我查寻了一下latin-1是什么?
Latin1是ISO-8859-1的别名,有些环境下写作Latin-1。
ISO-8859-1编码是单字节编码。
Unicode其实是Latin1的扩展。只有一个低字节的Uncode字符其实就是Latin1字符(这里认为unicode是两个字节,事实上因为各种版本不一样,字节数也不一样)
所以我的理解是:因为中文至少两个字节,所以不能解码出来
例2:
因为他们解码和编码使用的编码标准不一样。text1是用gbk解码,那么用utf-8编码回去就会报错,text6同理
好,回到百度例子,那么我们要怎么样才能看到我们想要的网页源代码呢?
使用requests库
正确代码:
今天折腾了一天,全部总结一遍
环境:win10,pycharm,python3.41.首先先来网页编码是utf-8的:
以百度首页为例:
使用requests库
-
import requests
-
-
url="http://www.baidu.com"
-
response = requests.get(url)
-
content = response.text
-
print(content)
使用urllib库
-
import urllib.request
-
-
response = urllib.request.urlopen('http://www.baidu.com')
-
print(response.read())
接下来介绍encode()和decode()方法
encode()用于解码,decode()方法用于编码
注:python3默认编码为utf-8
例1:
-
text = '中华'
-
print(type(text))
-
print(text.encode('gbk'))#以gbk形式解码,即把utf-8的字符串text转换成gbk编码
-
print(text.encode('utf-8'))#以utf-8形式解码,因为原本是utf-8编码,所以返回二进制
-
print(text.encode('iso-8859-1'))#报错
<class 'str'>
b'xd6xd0xbbxaa'
b'xe4xb8xadxe5x8dx8e'
UnicodeEncodeError: 'latin-1' codec can't encode characters in position 0-1: ordinal not in range(256)
为什么第四个报错?
我查寻了一下latin-1是什么?
Latin1是ISO-8859-1的别名,有些环境下写作Latin-1。
ISO-8859-1编码是单字节编码。
Unicode其实是Latin1的扩展。只有一个低字节的Uncode字符其实就是Latin1字符(这里认为unicode是两个字节,事实上因为各种版本不一样,字节数也不一样)
所以我的理解是:因为中文至少两个字节,所以不能解码出来
例2:
-
text = '中华'
-
print(type(text)) #<class 'str'>
-
text1 = text.encode('gbk')
-
print(type(text1)) #<class 'bytes'>
-
print(text1) #b'xd6xd0xbbxaa'
-
text2 = text1.decode('gbk')
-
print(type(text2)) #<class 'str'>
-
print(text2) #中华
-
text3 = text1.decode('utf-8') #报错:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd6 in position 0: invalid continuation byte
-
print(text3)
-
-
text4= text.encode('utf-8')
-
print(type(text4)) #<class 'bytes'>
-
print(text4) #b'xe4xb8xadxe5x8dx8e'
-
text5 = text4.decode('utf-8')
-
print(type(text5)) #<class 'str'>
-
print(text5) #中华
-
text6 = text4.decode('gbk') #报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 2: illegal multibyte sequence
-
print(text6)
因为他们解码和编码使用的编码标准不一样。text1是用gbk解码,那么用utf-8编码回去就会报错,text6同理
好,回到百度例子,那么我们要怎么样才能看到我们想要的网页源代码呢?
使用requests库
-
import requests
-
-
url="http://www.baidu.com"
-
response = requests.get(url)
-
content = response.text.encode('iso-8859-1').decode('utf-8')
-
#把网页源代码解码成Unicode编码,然后用utf-8编码
-
print(content)
-
import urllib.request
-
-
response = urllib.request.urlopen('http://www.baidu.com')
-
print(response.read().decode(utf-8))
-
import requests
-
response = requests.get('http://www.dytt8.net/')
-
#print(response.text)
-
html = response.text
-
-
print(html)
-
import urllib.request
-
#get请求
-
response = urllib.request.urlopen('http://www.baidu.com')
-
print(response.read())
正确代码:
-
import requests
-
response = requests.get('http://www.dytt8.net/')
-
#print(response.text)
-
html = response.text.encode('iso-8859-1').decode('gbk')
-
-
print(html)
-
import urllib.request
-
#get请求
-
response = urllib.request.urlopen('http://www.dytt8.net/')
-
print(response.read().decode('gbk'))
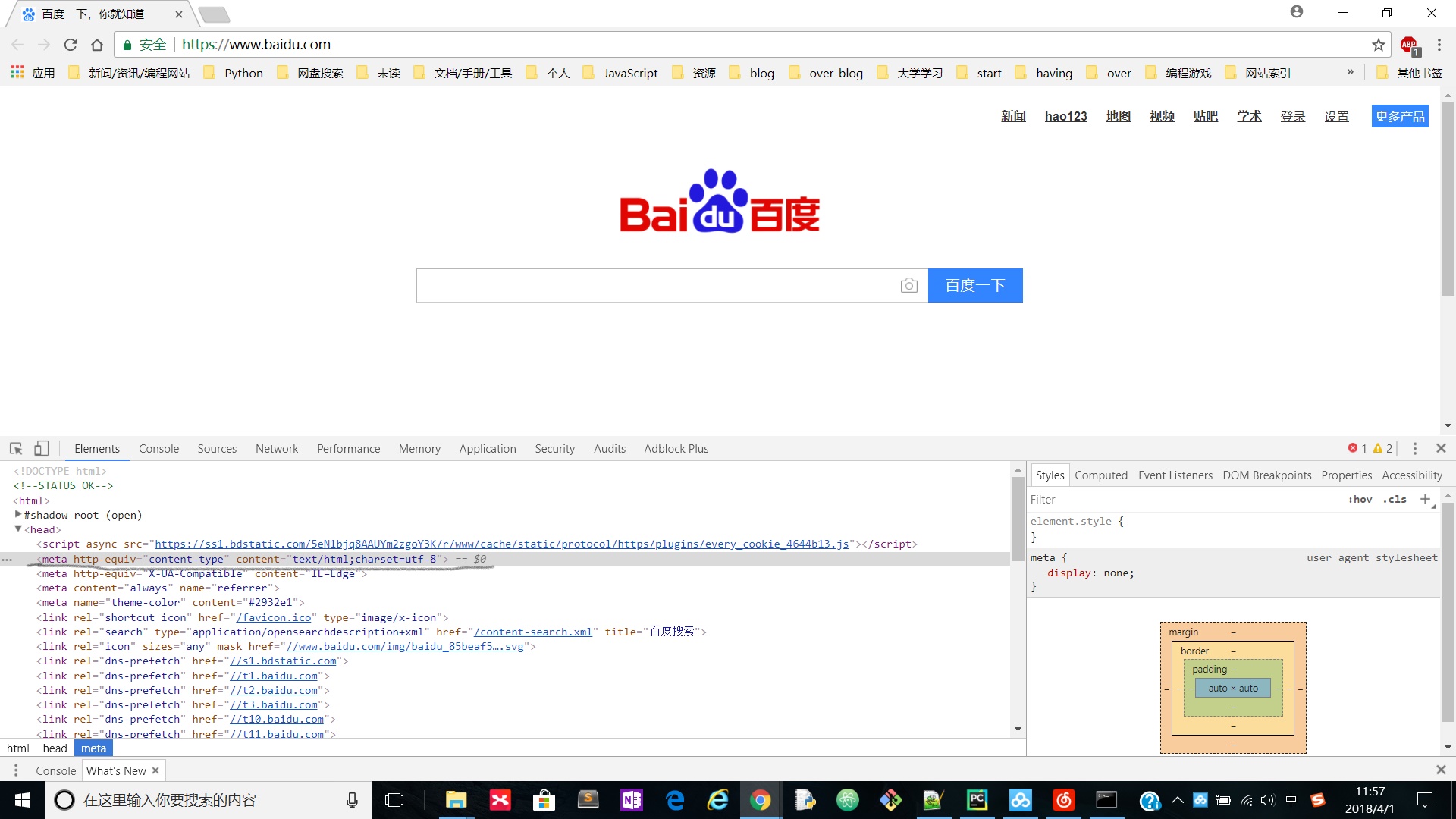
附:如何看网页源代码的编码格式?
使用F12查看网页源代码的head标签里的meta标签
如: