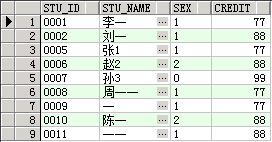
查看测试数据
select * from student;
1. like
在where字句中使用like可以达到模糊查询的效果,常用通配符如下
▶ %: 使用 % 有三种情况
① 字段 like ‘%关键字%’字段包含”关键字”的记录
select * from student where stu_name like '%一%';
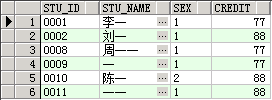
查询结果是stu_name字段中所有包含“一”关键字的记录。
② 字段 like ‘关键字%’字段以”关键字”开始的记录
select * from student where stu_name like '一%';

查询结果是stu_name字段中所有以“一”关键字开始的行。
③ 字段 like ‘%关键字’字段以”关键字”结束的记录
select * from student where stu_name like '%一';
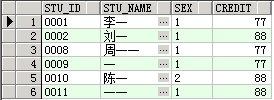
查询结果是stu_name字段中所有以“一”关键字结束的记录。
▶ _:单一任何字符,只能匹配单个的字符,使用示例如下
select * from student where stu_name like '_一';
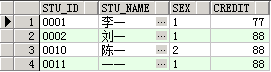
查询结果为只有两个字符,并且第二个字符为“一”的记录。
select * from student where stu_name like '_一_';

查询结果为只有三个字符,并且第二个字符为“一”的记录。
select * from student where stu_name like '_一%';

可以与通配符%一起使用,查询结果为第二个字符为“一”的所有记录。
2. regexp_like
▶ []: 实际应用中,会碰到要查询在某一范围内的字符,表示括号内所列字符的一个,类似正则表达式。指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。
① 查询名为“一”,姓“刘李孙”的学生姓名
--错误示范,无法查询到结果
select * from student where stu_name like '[刘李孙]一';
--正确示范
select * from student where regexp_like(stu_name,'[刘李孙]一');

② 查询[]内有一系列字符,如1234,abcd等记录
--错误示范,无法查询到结果
select * from student where stu_name like '赵[1-9]';
--正确示范
select * from student where regexp_like(stu_name,'赵[1-9]');

注意:[]不能与%或者_一起使用。无法查询到正确的结果。
▶ ^:不在某个范围内
① 查询名为“一”,姓不是“刘李孙”的学生姓名
--错误示范,无法查询到结果
select * from student where stu_name like '[^刘李孙]一';
--正确示范
select * from student where regexp_like(stu_name,'[^刘李孙]一');
3. Instr(StrSource,StrTarget)
instr函数也有三种情况:
① instr(字段,’关键字’)>0相当于 字段like ‘%关键字%’
② instr(字段,’关键字’)=1相当于 字段like ‘关键字%’
③ instr(字段,’关键字’)=0相当于 字段not like ‘%关键字%’
--特殊用法:
select * from student where instr('李一,刘一', stu_name) > 0;
--不完全等价于
select * from student where stu_name = '李一' or stu_name = '刘一';

这种特殊用法会奖满足条件的条件的字符串,和单个字符串数据都筛选出来。数据规范的情况下,这两者是等价的。
数据量比较小的时候,使用like,数据量较大情况下,使用instr,数据量更大情况下,使用Oracle的instr函数与索引配合提高模糊查询的效率。
4. like、instr性能测试
很多时候,我们要进行字符串匹配,在SQL语句中,我们通常使用like来达到我们搜索的目标。但经过实际测试发现,like的效率与instr函数有相当大的差别。
① 1000多万条数据,测试时like的效率与instr函数差别不是特别大。
select count(*) from student;
--数据结果:11855410
select count(*) from student where stu_name like '%王%';
--数据结果:702077
--测试时间:1.966秒
select count(*) from student where instr(stu_name,'王');
--数据结果:702077
--测试时间:2.137秒
② 亿级数量级,测试结果instr效果明显好于like。
select count(*) from student;
--数据结果:2244661391
select count(*) from student where stu_name like '%王%';
--数据结果:415065640
--测试时间:86.939秒
select count(*) from student where instr(stu_name,'王');
--数据结果:415065640
--测试时间:60.591秒
为提高效率,我们在stu_name字段上可以加上非唯一性索引,这样,再使用这样的语句查询,效率可以提高不少,表数据量越大时两者差别越大。
✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍扩展阅读✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍
5. 正则表达式
oracle 10g 增加的正则表达式函数有以下四种:
regexp_like() --返回满足条件的字段
regexp_instr() --返回满足条件的字符或字符串的位置
regexp_replace() --返回替换后的字符串
regexp_substr() --返回满足条件的字符或字符串
这四个函数的功能分别对应传统sql的 like操作符 和 instr 、replace 、substr函数,
在一般的、不怎么复杂的模式匹配中,使用传统的sql函数就能满足,当需要实现的操作
比较复杂时,使用正则表达式函数,就可以写出简洁、强大的sql语句。
匹配过程中可能会涉及到的元字符(Meta Character)对应的sql代码:
^ 使表达式定位至一行的开头
$ 使表达式定位至一行的末尾
* 匹配0次或更多次
? 匹配0次或1次
+ 匹配1次或更多次
{m} 正好匹配m次
{m,} 至少匹配m次
{m,n} 至少匹配m次但不超过n次
[:alpha:] 字母字符,匹配字符A-Z、a-z
[:lower:] 小写字母字符,匹配字符a-z
[:upper:] 大写字母字符,匹配字符A-Z
[:digit:] 数字,匹配数字0-9
[:alphanum:] 字母数字字符,匹配字符A-Z、a-z、0-9
[:space:] 空白字符(禁止打印),如回车、换行符、竖直制表符和换页符[:punct:] 标点字符
[:cntrl:] 控制字符(禁止打印)
[:print:] 可打印字符|分隔替换选项,通常与分组符()一期使用
() 将子表达式分组为一个替换单元,量词单元或后向引用单元
[char] 字符列表
. 匹配除null之外的任意单个字符
/ 要匹配的字符是一个特殊字符、常量或者后者引用
x|y 匹配 x 或 y
[abc] 匹配abc中的任何单个字符
[a-z] 匹配 a 到 z 范围内的任意单个字符
✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍扩展阅读✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍✍