注意B-树就是B树,-只是一个符号.
简介
B/B+树是为了磁盘或其它存储设备而设计的一种平衡多路查找树(相对于二叉,B树每个内节点有多个分支),与红黑树相比,在相同的的节点的情况下,一颗B/B+树的高度远远小于红黑树的高度(在下面B/B+树的性能分析中会提到).B/B+树上操作的时间通常由存取磁盘的时间和CPU计算时间这两部分构成,而CPU的速度非常快,所以B树的操作效率取决于访问磁盘的次数,关键字总数相同的情况下B树的高度越小,磁盘I/O所花的时间越少.
B树中所有结点的孩子结点数的最大值称为B树的阶,通常用m表示。
一棵m叉树的性质如下:
树中每个结点至多有m棵子树(即至多含有m-1个关键字)
若根结点不是终端结点,则至少有两棵子树
除根结点以外的所有非叶子结点至少有[m/2](向上取整)棵子树(即至少含有[m/2]-1个关键字)
所有非叶子结点的关键字:K[1], K[2], …, K[m-1];且K[i] < K[i+1];
非叶子结点的指针:P[1], P[2], …, P[m];其中P[1]指向关键字小于K[1]的子树,P[m]指向关键字大于K[m-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
所有叶子结点位于同一层;
这里只是一个简单的B树,在实际中B树节点中关键字很多的.上面的图中比如35节点,35代表一个key(索引),而小黑块代表的是这个key所指向的内容在内存中实际的存储位置.是一个指针。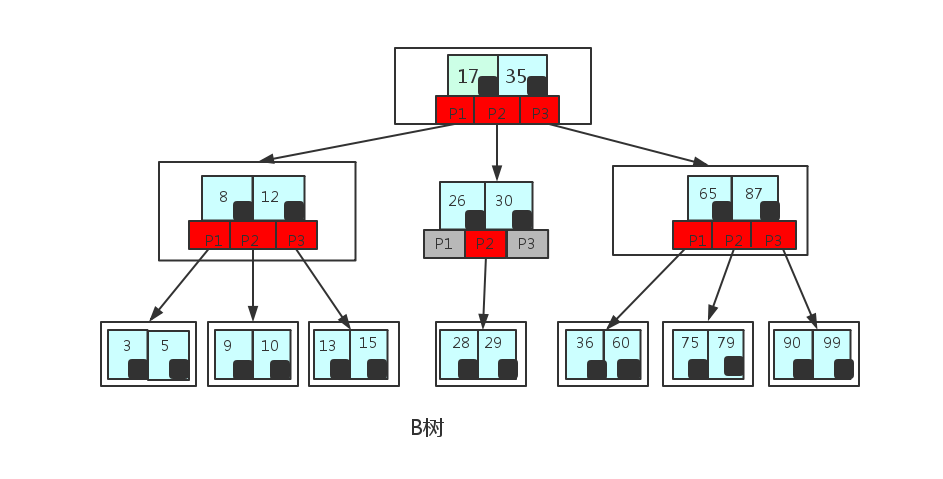
B+树
B+树是应文件系统所需而产生的一种B树的变形树(文件的目录一级一级索引,只有最底层的叶子节点(文件)保存数据.),非叶子节点只保存索引,不保存实际的数据,数据都保存在叶子节点中.这不就是文件系统文件的查找吗?我们就举个文件查找的例子:有3个文件夹,a,b,c, a包含b,b包含c,一个文件yang.c, a,b,c就是索引(存储在非叶子节点), a,b,c只是要找到的yang.c的key,而实际的数据yang.c存储在叶子节点上.
所有的非叶子节点都可以看成索引部分,这里就不详细介绍了
但为什么数据库大部分都采用B树呢?
当数据量很大的时候,磁盘的I/O速度是远远比不上内存的读写的。B-Tree的查询效率好像也并不比平衡二叉树高,但查询所经过的结点数量要少很多,也就意味着要少很多次的磁盘IO,这对
性能的提升是很大的。
操作系统从磁盘读取数据到内存是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么。即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理: 当一个数据被用到时,其附近的数据也通常会马上被使用。对于B树来讲,一个结点包含多个数据,比如从磁盘读取时读取一个结点的信息,包含多个数据中有就有目标数据,就不用再次进行IO读取了
附一篇mysql索引更详细的讲解
https://blog.csdn.net/weixin_42181824/article/details/82261988