这里记录下一些之前不太了解的知识点,还有一些小细节吧
序
首先,为什么要有Containers来持有对象,直接用array不好吗?——数组是固定大小的,使用不方便,而且是只能持有一个类型的对象,但当你要存储或者操作基本数据类型的是,就推荐直接用array数组了。
如果不用泛型指定类型,直接new ArrayList()这样的话,存在里面的和直接get方法拿出来的都是Object类的对象,你必须对他进行另外的强制转换。如果你用了泛型,在编译器就可以帮你检测你是否put或者add正确的类型进containers中,而且get对象引用出来的时候,也会提前帮你做好转换工作。
添加元素的方法
这里介绍两个相关的方法:Arrays.asList()和Collections.addAll()
Arrays.asList()方法
这个是Arrays类的一个static方法可以接收一个数组、或者是一系列以逗号分隔的element参数(一种可变参数这样的),然后返回一个List。
这是个很好用的方法,我们可以很方便地用这个结合数组来初始化我们的Collection。
但这个方法有几个要注意的地方:
1. 这个asList()方法的底层实现是数组,所以它的特性和数组的特性是一样的——size是固定的。意味着这个Arrays.asList()方法产生的List是不能被改变大小的,也就是说如果你对这个返回的list进行add()或者delete()操作,这其实就企图去改变底层array的大小了,你会get一个运行时的异常——Unsupported Operation error
而且,因为这个List对象是用底层数组作为物理实现的,所以如果你调整了这个list的元素顺序,比如用Collections.shuffle()方法打乱了这个List,那么原来的数组的顺序也会一样改变。
2.这个方法有个特性,也可以说是个限制它会根据你array数组里面的元素,然后去猜测数组所持对象的类型,然后返回该类型的List对象,但这个机制不会去管你把这个list传给什么引用!!
百度了很久,这句话的意思是,Arrays.asList()生成的List的时候,会根据list里面的元素来决定返回一个元素是什么的List。
如果不指定返回List的类型(即<>部分)的话,Arrays.asList()对其返回List的类型有自己的判断,可以视为它自身的一种优化机制。
看一个例子来说明:
//: holding/AsListInference.java // Arrays.asList() makes its best guess about type. import java.util.*; class Snow {} class Powder extends Snow {} class Light extends Powder {} class Heavy extends Powder {} class Crusty extends Snow {} class Slush extends Snow {} public class AsListInference { public static void main(String[] args) { List<Snow> snow1 = Arrays.asList(new Crusty(), new Slush(), new Powder()); // Won’t compile: // List<Snow> snow2 = Arrays.asList( // new Light(), new Heavy()); // Compiler says: // found : java.util.List<Powder> // required: java.util.List<Snow> // Collections.addAll() doesn’t get confused: List<Snow> snow3 = new ArrayList<Snow>(); Collections.addAll(snow3, new Light(), new Heavy()); List<Snow> snow3_5 = Arrays.asList(new Light(), new Crusty()); //pass // Give a hint using an // explicit type argument specification: List<Snow> snow4 = Arrays.<Snow>asList(new Light(), new Heavy()); } } ///:~
如注释中的,snow1list中,array中的三个对象都是Snow的直接子类的对象,或者说它们都是Snow类型的,然后asList方法就判断出这个list应该是Snow类型的,然后就返回Snow类型的List。
而snow2的list是编译不通过的,为什么呢? 这两个都是Power的子类,虽然间接继承,但asList就看见你两个都是Power类的,所以便返回了一个List<Power>,然后报错。可以看到asList方法不会观念前面那个引用的泛型是Snow,而是根据自己的判断然后返回。
snow3是直接用Collections.addAll方法,就不会有这个困扰。其实也很容易理解嘛,你传了个snow3给addAll方法,那么它就知道你的类型是Snow了,没毛病。
snow3_5数组里面既有Snow类的也有Power类的,然后通过了编译。
如果你依然想用asList方法来解决snow2的问题,那么可以给它留个线索,去告诉编译器——what the actual target type should be for the resulting List type produced by Arrays.asList( ).
This is called an explicit type argument specification.——这个叫做显示类型参数说明喔。
语法如下:
Arrays.<Snow>asList(new Light(), new Heavy());
Collections.addAll()方法
注意噢这个也是Collections类的一个static方法,接受一个Collection对象,然后另外可以接受数组、或者一系列以逗号分隔的element参数,然后把相关参数添加到那个Collection的对象上去。
书上说,比起直接调用Collection的构造器,然后传个它个Collection对象来初始化这个Collection,这个Collections.addAll()方法更快,所以推荐比如是List就创建一个空的ArrayList然后用这个Collections.addAll()方法来初始化这个list。
然后如果你想直接用Collection对象中的类方法——addAll()的话,也行,但传给它的参数只能是一个Collection的对象,比如
List list = new ArrayList();
然后你如果用list.addAll()方法的话,你只能把要添加的元素作为Collection传进去,像list.addAll(int index, listData);或者list.addAll(listData);(listData是另一个List的Collection)
但如果用的是Collections.addAll方法的话
Collections.addAll(list, listData);甚至是Collection.addAll(list, 12, 13, 44, 23);——就直接穿element进去,当然还可以传数组,就可变参数,非常方便。
容器基本都很好地支持打印的功能。
关于List
在List容器中,你要删除一个元素的话,可以传递这个元素的引用,也可以传个index;你也可以根据一个对象的引用,来查这个对象元素在list中的index。
当需要判断一个元素是不是List中的一部分;根据传进来的对象引用找它的index;根据一个引用来删除element等等操作,都基于Object类的equals方法!!
所以有些地方要注意了噢,比如String这些重写了equals方法的类。
list的subList()方法,所生成的子序列,是来自原来的list的,这个返回给你的subList,你对它进行操作,会影响到原来的那个list的,反之亦然。
retainAll()方法可以用来求交集。
toArray()方法如果不传任何参数进去的话,就返回一个Object的数组;传一个某个类型的array的话,就会生成这个类型的array:
Pet[] pa = pets.toArray(new Pet[0]);
如果传进来的数组太小,像这里的传进来一个new Pet[0],那么会帮你创建一个新的正确大小的数组。(其实这个参数可以理解为像泛型一样的作用)
关于迭代
迭代器Iterator的作用是为了可以写更高层的代码,不用理会你用的是什么类型的Container,只需要一个框架、一个代码就可以迭代你传进来的Container。
这里我们先介绍下Iterator对象——迭代器Iterator是个遍历和选择序列中的对象的一个—— 对象。通常叫它是一个—— 轻量级的对象,它就有三个方法:
1. next();
2. hasNext();
3. remove()。
注意Java的一个Iterator对象只能单方向遍历一个Container。
对于一个Collection对象,你可以通过调用iterator()方法来获取一个Iterator对象。
for each可以理解成一个简单的Iterator语法。
ListIterator是Iterator的子类,是专门针对List的强一点的Iterator类,可以双向遍历,还有很多其他方法。
补充:
1.可以把Iterators想象成一个游标,一开始游标在containers中第一个元素的左边。
2.next方法是返回当前游标右边的元素并将游标往下移动。
3.remove是删除游标左边的元素,这个方法只能在执行完next操作后进行,而且只能执行一次。
4.遍历的过程中要是想移除元素,只能用迭代器的remove,不能用这个collection接口的的remove方法。因为在iterator循环的内部,它执行了锁定。它会把当前那的元素给锁住谁也不让动,除了它自己!!
书里面花了一章的篇幅去讲Collection还有Iterator,大概就是:
说C++的类库中没有什么容器的公共类,所有共性都是通过迭代器Iterators来实现的。但Java的Collection是包括了Iterator的,所以实现Collection接口就是意味着提供了Iterator()方法。
具体的在书上p323
for each和Iterable接口
刚刚有说到,for each语法是简洁的一个Iterator对象的遍历方式,所有Collection对象都能很好地用for each语法来遍历。这是因为jdk5以上有个新的接口——Iterable,这个接口里面只有一个iterator()方法,这个方法会返回一个Iterator对象,实现了这个接口的类,就是可以遍历的,也就是可以用for each语法的。
这里可能要搞清楚下这个Iterable接口和Iterator接口。Iterator接口是一个拿来遍历的工具,可以理解成,接口中的方法是next(),hasNext()什么的;而Iterable接口,是意味着这个类可以遍历,这个接口就一个iterator()方法,返回一个用来遍历的工具对象——Iterator类的对象。
注意数组很多时候不是Iterable的。
下面的例子是,如何利用适配器的方法来使一个已经实现了Iterable的类,可以有几种遍历的方法:
public class MultiIterableClass extends IterableClass { public Iterable<String> reversed() { return new Iterable<String>() { public Iterator<String> iterator() { return new Iterator<String>() { int current = words.length - 1; public boolean hasNext() { return current > -1; } public String next() { return words[current--]; } public void remove() { // Not implemented throw new UnsupportedOperationException(); } }; } }; } public Iterable<String> randomized() { return new Iterable<String>() { public Iterator<String> iterator() { List<String> shuffled = new ArrayList<String>(Arrays.asList(words)); Collections.shuffle(shuffled, new Random(47)); return shuffled.iterator(); } }; } public static void main(String[] args) { MultiIterableClass mic = new MultiIterableClass(); for(String s : mic.reversed()) System.out.print(s + " "); System.out.println(); for(String s : mic.randomized()) System.out.print(s + " "); System.out.println(); for(String s : mic) System.out.print(s + " "); } } /* Output: banana-shaped. be to Earth the know we how is that And is banana-shaped. Earth that how the be And we know to And that is how we know the Earth to be banana-shaped. *///:~
关于LinkedList
LinkedList实现了很多其他的方法,可以当作栈、队列、甚至双头队列来使用。很强啊!!
p311介绍了很多LinkedList的方法,很多名字不同但功能差不多或者有些其他什么的区别。
关于Stack
LinkedList具有Stack的所有功能,可以当作Stack来使用。当然你也可以通过LinkedList来封装一个自己的Stack类,这样用起来更清晰点。
Java的util包中没有公共的方法接口,因为原来的一开始的util.Stack类设计的不好,建议不要用喔。说LinkedList提供了更好的Stack实现。
关于Set
HashSet用一个很复杂方法来存储元素,但这个方法是可以最快地获取到你想要的元素的。但它里面的存储是没有顺序的。
如果你对存储的顺序很看重,或者希望set里面的元素按某种顺序来存储,可以使用TreeSet,这个container可以按照一个比较的顺序来存储元素。
LinkedHashSet的话,是可以按照你添加进这个set的顺序,来存储元素的,
Set里面不能有重复的元素,所以经常用来测试一个对象的归属性。
set接口的方法和Collection接口的方法是一样的!所以我们说set就是一个Collection。
想要让TreeSet换一种排序的方式?——通过传入比较器对象:
//: holding/UniqueWordsAlphabetic.java // Producing an alphabetic listing. import java.util.*; import net.mindview.util.*; public class UniqueWordsAlphabetic { public static void main(String[] args) { Set<String> words =new TreeSet<String>(String.CASE_INSENSITIVE_ORDER); words.addAll(new TextFile("SetOperations.java", "\W+")); System.out.println(words); } } /* Output: [A, add, addAll, added, args, B, C, class, Collections, contains, containsAll, D, E, F, false, from, G, H, HashSet, holding, I, import, in, J, java, K, L, M, main, mindview, N, net, new, Output, Print, public, remove, removeAll, removed, Set, set1, set2, SetOperations, split, static, String, to, true, util, void, X, Y, Z] *///:~
关于Map
Map容器中,每个键key只能存一个。一样,HashMap可以提供最快的查询操作,但存储元素的顺序是没有一个很明显的顺序的;TreeSet可以keeps the keys by一个比较的顺序;然后LinkedHashMap是a LinkedHashMap keeps the keys in insertion order while retaining the lookup speed of the HashMap.
map的keySet()方法返回所有键key的一个set。
map的values()方法通过一个Collection对象来返回它的值value。
Map.Entry说明
Map是java中的接口,Map.Entry是Map的一个内部接口。
Map提供了一些常用方法,如keySet()、entrySet()等方法,keySet()方法返回值是Map中key值的集合;entrySet()的返回值也是返回一个Set集合,此集合的类型为Map.Entry。
Map.Entry是Map声明的一个内部接口,此接口为泛型,定义为Entry<K,V>。它表示Map中的一个实体(一个key-value对)。接口中有getKey(),getValue方法。
关于Queue
队列在并发编程中很重要。
强大的LinkedList提供了许多Queue特有的方法,并且实现了Queue的接口!!
Queue<Integer> queue = new LinkedList<Integer>();
queue有一些特有的方法,直接上书里的图:
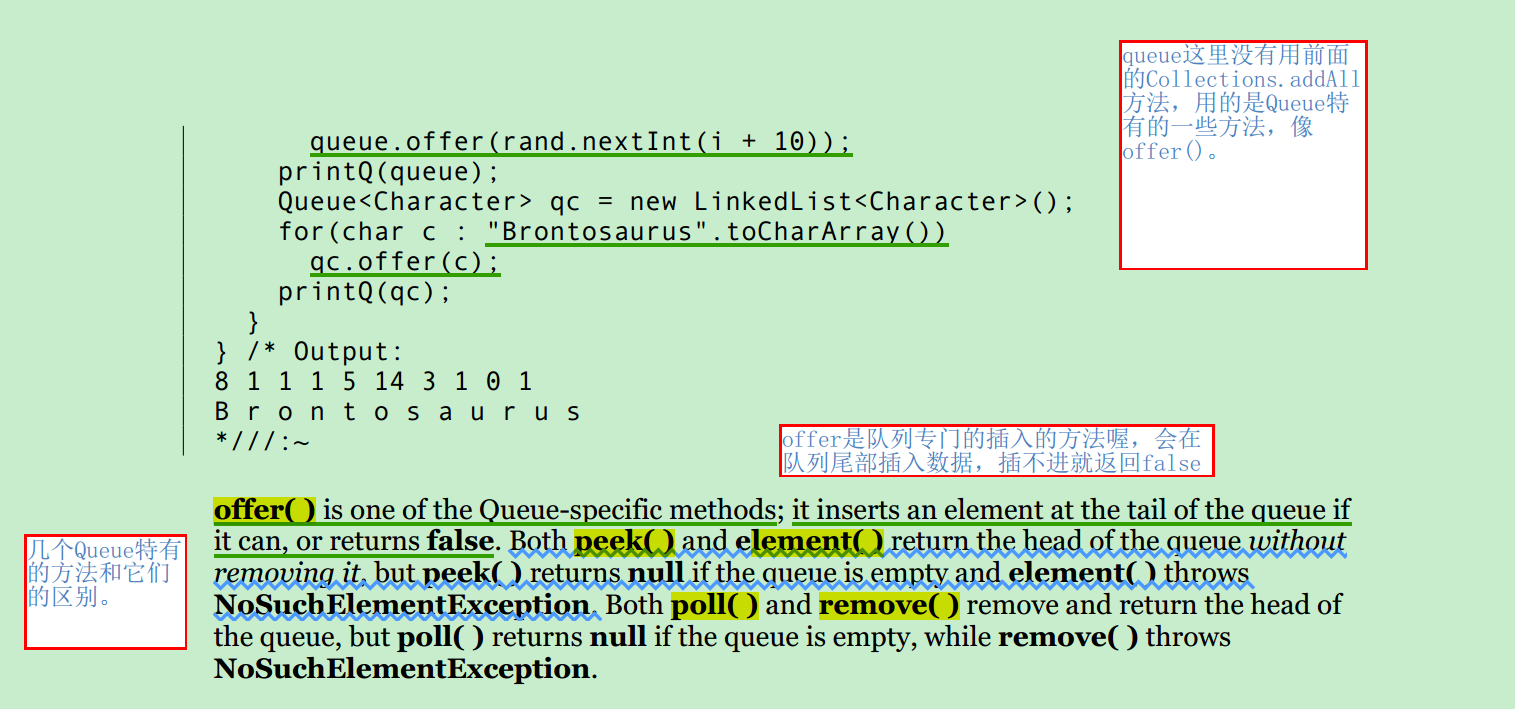
默认的queue的策略是先进先出,Java里面还有个Priority Queue,按优先级先出。
可以修改优先队列中默认的排序,通过提供你的Comparator
默认的排序用的是队列中的对象的自然排序。
像Integer、String还有Character这些都能直接用这个Priority Queue了。(注意,在String中默认排序里,空格也算一个value,而且优先级比字母高)
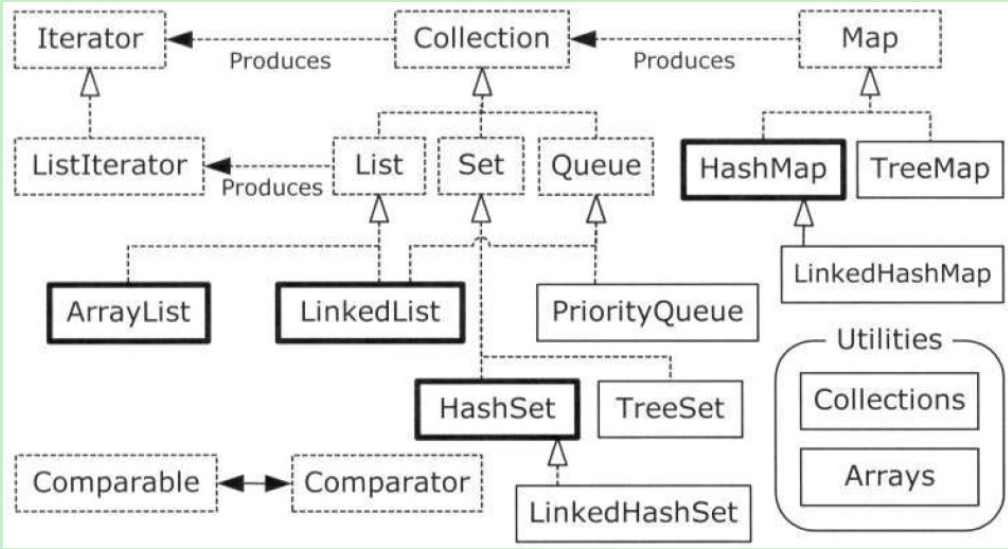
最后上个Containers关系图: