1、问题描述:
爬取猫眼TOP100榜的100部高分经典电影,并将数据存储到CSV文件中
2、思路分析:
(1)目标网址:http://maoyan.com/board/4
(2)代码结构:

(3) init(self)初始化函数
· hearders用到了fake_useragent库,用来随机生成请求头。
· datas空列表,用于保存爬取的数据。
def __init__(self,url):
self.headers = {"User-Agent": UserAgent().random}
self.url = url
self.datas = list()
(4) getPage()函数
猫眼Top100榜总共有10页电影,每页的链接基本一样,只有最后一个数字在变化http://maoyan.com/board/4?offset=10,所以可以通过for循环来访问10页的电影。
# 通过for循环,获取10页的电影信息的源码
def getPage(self):
for i in range(0,10):
url = self.url + "?offset={0}".format(i*10)
response = requests.get(url, headers = self.headers)
if response.status_code == 200:
self.parsePage(response.text)
else:
return None
(5)parsePage()函数
每页都有10部高分经典电影,通过BeautifulSoup获取每页10部电影的详细信息:名字、主演、上映时间、评分。
# 通过BeautifulSoup获取每页10部电影的详细信息
def parsePage(self, html):
soup = BeautifulSoup(html, "html.parser")
details = soup.find_all("dd")
for dd in details:
data = {}
data["index"] = dd.find("i").text
data["name"] = dd.find("p", class_ = "name").text
data["star"] = dd.find("p", class_="star").text.strip()[3:]
data["time"] = dd.find("p", class_="releasetime").text.strip()[5:]
data["score"] = dd.find("p", class_="score").text
self.datas.append(data)
(6)savaData()函数
通过DataFrame(),把Top100的电影存储到CSV文件中。
它默认的是按照列名的字典顺序排序的。想要自定义列的顺序,可以加columns字段
# 通过DataFrame,把Top100的电影存储到CSV文件中
def saveData(self):
self.getPage()
data = pd.DataFrame(self.datas)
columns = ["index", "name", "star", "time", "score"]
data.to_csv(".maoyanTop100.csv", index=False, columns=columns)
3、效果展示
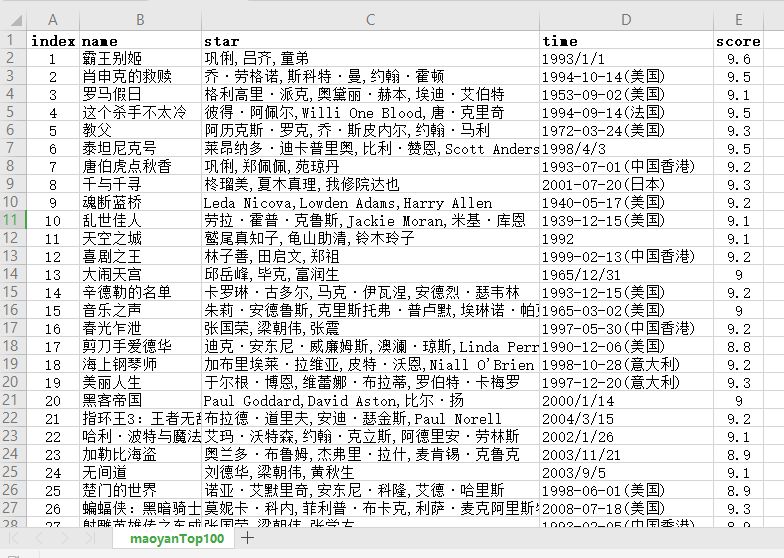
4、完整代码:
# -* conding: utf-8 *-
#author: wangshx6
#data: 2018-11-08
#description: 爬取猫眼TOP100榜的100部高分经典电影
import requests
from bs4 import BeautifulSoup
import pandas as pd
from fake_useragent import UserAgent
class MaoyanSpider(object):
def __init__(self,url):
self.headers = {"User-Agent": UserAgent().random}
self.url = url
self.datas = list()
# 通过for循环,获取10页的电影信息的源码
def getPage(self):
for i in range(0,10):
url = self.url + "?offset={0}".format(i*10)
response = requests.get(url, headers = self.headers)
if response.status_code == 200:
self.parsePage(response.text)
else:
return None
# 通过BeautifulSoup获取每页10部电影的详细信息
def parsePage(self, html):
soup = BeautifulSoup(html, "html.parser")
details = soup.find_all("dd")
for dd in details:
data = {}
data["index"] = dd.find("i").text
data["name"] = dd.find("p", class_ = "name").text
data["star"] = dd.find("p", class_="star").text.strip()[3:]
data["time"] = dd.find("p", class_="releasetime").text.strip()[5:]
data["score"] = dd.find("p", class_="score").text
self.datas.append(data)
# 通过DataFrame,把Top100的电影存储到CSV文件中
def saveData(self):
self.getPage()
data = pd.DataFrame(self.datas)
columns = ["index", "name", "star", "time", "score"]
data.to_csv(".maoyanTop100.csv", index=False, columns=columns)
if __name__ == "__main__":
url = "http://maoyan.com/board/4"
spider = MaoyanSpider(url)
spider.saveData()