0x00电影天堂爬虫代码
#coding:utf-8
from lxml import etree
import requests
BASE_DOMAIN = "https://www.dy2018.com/"
url = "https://www.dy2018.com/html/gndy/dyzz/index_2.html"
proxy = {
'http':'117.69.150.100:9000'#设置代理
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'
}
def get_detail_urls(url):
response = requests.get(url,headers=headers,proxies=proxy)
#requests库,默认会使用自己猜测的编码方式,将抓取下来的网页进行解码,然后存储到text属性。这里乱码我们需要自己指定解码方式
#text = response.content.decode('gbk')
text = response.text
#with open('dianying.html','w',encoding='utf-8') as fb:
# fb.write(response.text)
html = etree.HTML(text)
detail_urls = html.xpath("//table[@class='tbspan']//a/@href")#获取a标签下的href属性
#for detail_url in detail_urls:
# print(BASE_DOMAIN+detail_url)
detail_urls = map(lambda url:BASE_DOMAIN+url,detail_urls)#使用无名函数,将列表中的每一项都执行一下函数。等价于下面的:
#def abc(url):
# return BASE_DOMAIN+url
#index = 0
#for detail_url in detail_urls:
# detail_url = abc(detail_url)
# detail_urls(index) = detail_url
# index += 1
return detail_urls
#获取内容页数据
def parse_detail_page(url):
response = requests.get(url,headers=headers)
movie = {}
#text = response.content.decode('utf-8')
text = response.content.decode('gbk')
html = etree.HTML(text)
title = html.xpath("//div[@class='title_all']")
#for x in title:
# print(etree.tostring(x,encoding='utf-8').decode('utf-8'))
movie['title'] = title
zoomE = html.xpath("//div[@id='Zoom']")[0]
imgs = zoomE.xpath(".//img/@src")
cover = imgs[0]
screenshot = imgs[1]
movie['cover'] = cover
movie['screenshot'] = screenshot
def parse_info(info,rule):
return info.replace(rule,"").strip()
infos = zoomE.xpath(".//text()")
for index,info in enumerate(infos):
if info.startswith("◎年 代"):
info = info.replace("◎年 代","").strip()#将年代字符串替换为空,strip方法去掉前后空格
movie['year'] = info
elif info.startswith("◎产 地"):
info = parse_info(info,"◎产 地")
movie['country'] = info
elif info.startswith("◎类 别"):
info = parse_info(info,"◎类 别")
movie['category'] = info
elif info.startswith("◎豆瓣评分"):
info = parse_info(info,"◎豆瓣评分")
movie['douban_rate'] = info
elif info.startswith("◎片 长"):
info = parse_info(info,"◎片 长")
movie['duration'] = info
elif info.startswith("◎导 演"):
info = parse_info(info,"◎导 演")
movie['director'] = info
elif info.startswith("◎主 演"):
info = parse_info(info,"◎主 演")
actors = [info]
for x in range(index+1,len(infos)):#因为演员不止一个,所以要用遍历形式打印
actor = infos[x].strip()
if actor.startswith("◎"):
break
actors.append(actor)
movie['actors'] = actors
elif info.startswith("◎简 介"):
info = parse_info(info,"◎简 介")
for x in range(index+1,len(infos)):
profile = infos[x].strip()
movie['profile'] = profile
down_url = html.xpath("//td[@bgcolor='#fdfddf']/a/@href")[0]
movie['download_url'] = down_url
return movie
#获取列表数据:
def spider():
base_url = "https://www.dy2018.com/html/gndy/dyzz/index_{}.html"
movies = []
for x in range(2,9):#第一个for循环,用来控制电影共有7页
url = base_url.format(x)
#print(url)
detail_urls = get_detail_urls(url)
#url = "https://www.dy2018.com/html/gndy/dyzz/index_2.html"
#detail_urls = get_detail_urls(url)
for detail_url in detail_urls:#第二个for循环,用来遍历一页中所有电影的详情url
#print(detail_url)
movie = parse_detail_page(detail_url)
movies.append(movie)
print(movie)
if __name__ == '__main__':
spider()
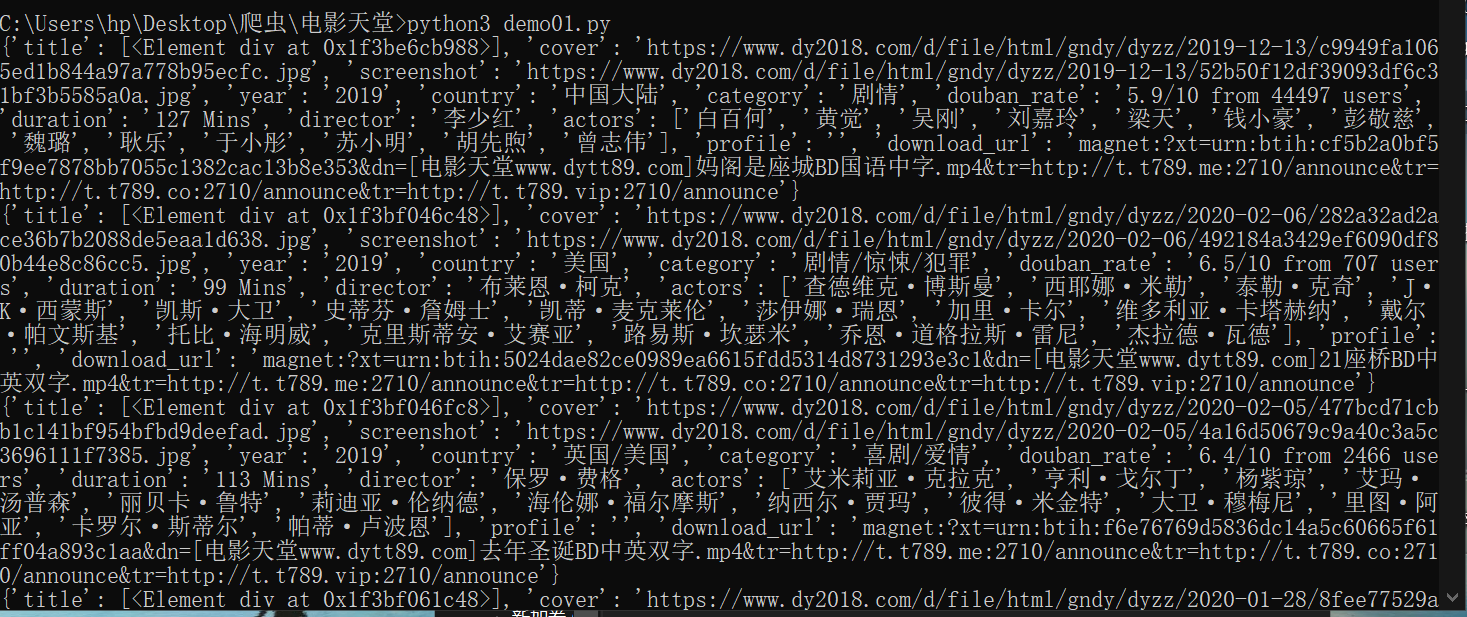
运行效果