Multi-shot Pedestrian Re-identification via Sequential Decision Making
2019-07-31 20:33:37
Code: https://github.com/TuSimple/rl-multishot-reid
1. Background and Motivation:
本文引入 DRL 到 person re-ID 任务,通过序列决策来完成难易样本的识别问题。主要动机如下图所示:

2. The Proposed Method:
2.1 Image-level feature extraction:
作者对图像特征提取,采用了多个组合损失函数的形式,即:classification loss, pairwise verification loss, and triplet verification loss。用了两种经典的骨干网络,即:Inception-BN 和 AlexNet。作者将一个序列中所有图像的 feature 进行聚合,得到 l2-normalized features,即:
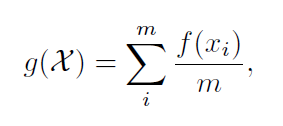
并且根据 l (*, *) 进行 identities 的排序,即:
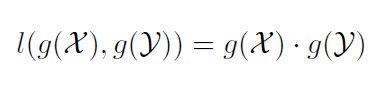
2.2 Sequence Level Feature Aggregation :
作者将该问题看做是 Markov Decision Processes (MDP), 表达为 (S, A, T, R)。 在每一个步骤中,agent 将会从两个输入序列中得到一个选择的图像对,来观察 state,然后选择一个动作,接下来该 agent 将会得到一个奖励 r。在此之后,如果序列没有结束,该智能体将会接收下一个 image pair,然后得到一个新的 state。
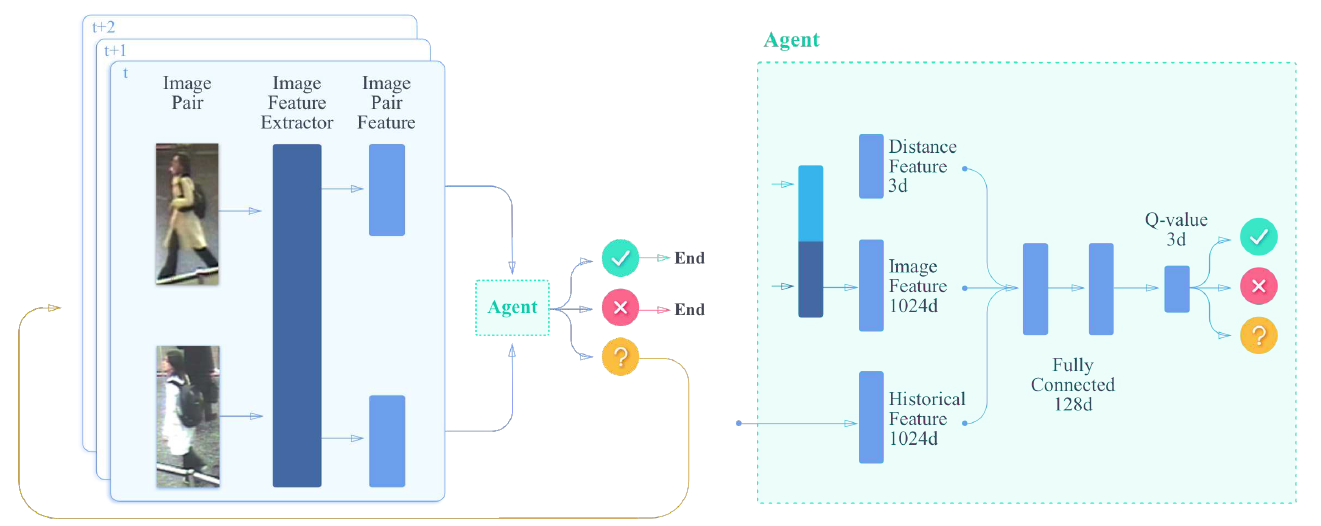
Actions and Transitions:
首先随机的从两个序列中,选择两个图像,构成 image pair。然后将该样本对输入到 agent 中,agent 会输出三个动作:same, different, and unsure。前两个动作将会停止当前的 episode,然后即可输出当前的结果。作者认为当智能体收集到了足够的信息,并且足够自信来进行决策的时候,就可以及时停止以避免不必要的计算代价。如果智能体选择的 action 是 unsure,那么我们将会选择其他的 image pair 来进行判别。
Rewards:我们定义如下的奖励情况:
如果 agent 给定的结果和 gt 一致,那么给定 +1 的奖励;
如果 at 与 gt 不同,奖励将是 -1;要么当 t = $t_{max}$ 时,at 仍然是 unsure 的时候;
当 t < $t_{max}$,$a_t$ 是 unsure 的时候,奖励是 $r_p$ ;
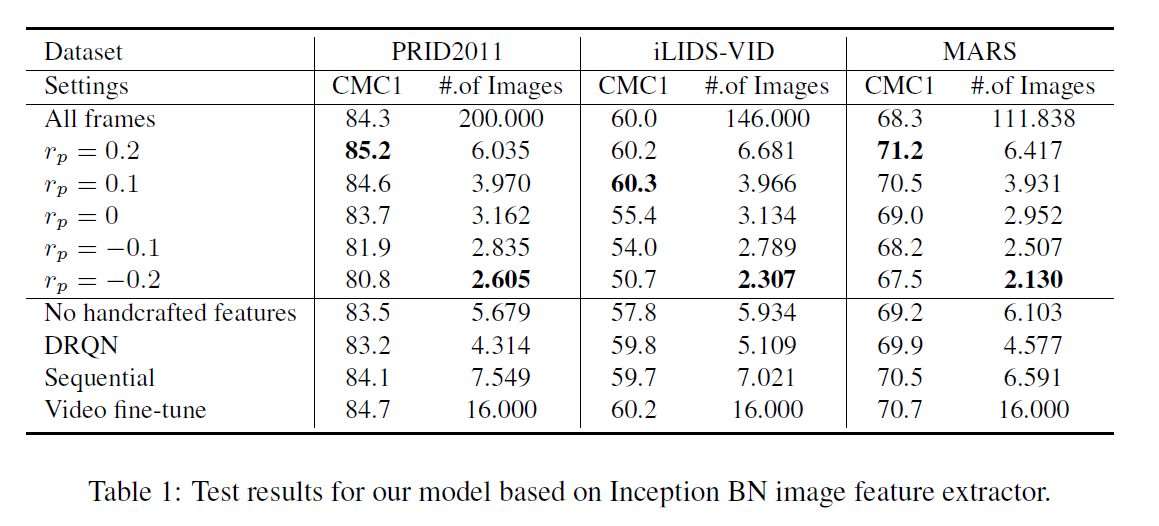
这里的 rp 可能是 + 也可能是 -,具体看情况:If rp is negative, it will be penalized for requesting more pairs; on the other hand, if rp is positive, we encourage the agent to gather more pairs, and stop gathering when it has collected $t_{max}$ pairs to avoid a penalty of -1. 这个值,将会极大地影响最终 agent 的行为。
States and Deep Q-learning:
我们使用 deep Q-learning 来找到最优的策略。对于每一个 state and action $(s_t, a_t)$, $Q(s_t, a_t)$ 代表了当前状态和动作下的折扣的累积奖励。在训练阶段,我们可以迭代的更新 Q-function:
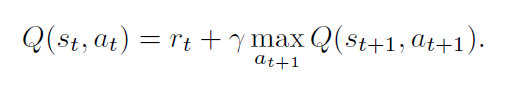
在时刻 t,状态 st 由如下的三个部分构成:
1). the first part is the observation $o_t$,即图像的特征;
2). the second part is a weighted average of the difference between historical image features of two sequences; 权重计算方法如下:

3). we also augment the image features with hand-crafted features for better discrimination.
3. Experimental Results:

==