ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
2020-03-12 23:10:53
Paper: NeurIPS 2019
Code: https://github.com/facebookresearch/vilbert-multi-task
1. Background and Motivation:
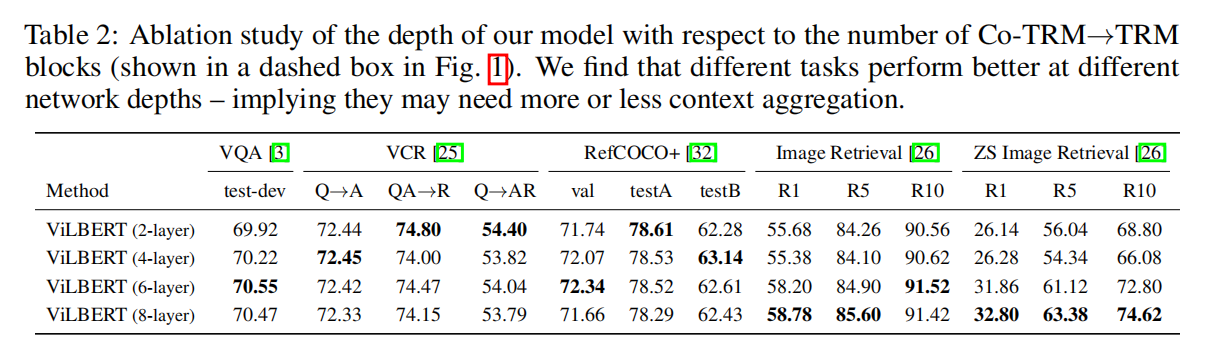
本文将 NLP 中非常火热的 BERT 模型拓展为了 多模态的版本,即:Vision + Language,称为 ViLBERT。如图 1 所示,该模型包含两个并行的流,分别用于编码 image 和 language,并且加入了 co-attention transform layer 来增强两者之间的交互,得到 pretrained model。作者在多个 vision-language 任务上得到了多个点的提升。
2. Approach Details:
本文首先对 BERT 模型进行了简要的介绍,然后介绍如何将 BERT 拓展到多模态领域,联合的进行学习视觉和语言的表达。

2.1. Preliminaries: Bidirectional Encoder Representations from Transformers (BERT):
BERT 模型是一种基于 attention 的双向语言模型。当在大型语料库上进行训练时,已经验证该方法可以取得非常有效的学习效果,并且在多个 NLP 的任务上取得了非常有效的迁移学习能力。BERT 模型在 word tokens $w_0, ... , w_T$ 上进行操作,这些 tokens 被映射到学习到的编码上,通过 L “encoder-style” transformer blocks 来产生最终的表示:$h_0, ... , h_T$。假设我们用 $H^{(l)}$ 来表示一个矩阵,其中的第 l 行 $h_0^{(l)}, ... , h_T^{(l)}$ 对应了第 l 层的中间表示。该中间层的表示 $H^{(l)}$ 用于计算三个度量 Q,K 和 V,分别对应的是:用于引导多头注意力模块的 queries, keys, and values。具体来说,queries 和 keys 之间 dot-product similarity 决定了 attentional distributions over value vectors。按照这种方式得到的 weighted-averaged value vector 构成了 attention block 的输出。作者将这种 query-conditioned key-value attention mechanism 来开发一种多模态 co-attention transformer 模型 ViLBERT。

Text Representation:BERT 处理的是离散的符号,包括 vocabulary words 以及 少量特殊的符号:SEP, CLS, 以及 MASK。对于一个给定的符号,输入的表示是 a sum of a token-specific learned embedding 以及 encodings for position(句子中符号的索引) 和 segment(如果存在多个,就标记符号句子的索引,the index of the token's sentence)。
Training Tasks and Objectives:BERT 模型在大型语料库中训练,有如下两种设定:masked language modelling 和 next sentence prediction。作者给出了如下的介绍:

2.2. ViBERT: Extending BERT to Jointly Represent Images and Text:
受到上述 BERT 的启发,作者将该模型拓展成可以处理多模态的版本,来联合的从 paired data 上来学习表示。
一种直观的方法是最少的改动 BERT:简单的通过聚类方法来离散化视觉输入,将这些 visual “tokens” 看成是 text inputs,然后从一个 pre-trained BERT model。但是这种结构有如下的缺点:
1). initial clustering may result in discretization error and lose important visual details;
2). it treats inputs from both modalities identically, ignoring that they may need different levels of processing due to either their inherent complexity or the initial level of abstration of their input representations.
3). Forcing the pretrained weights to accommodate the large set of additional visual "tokens" may damage the learned BERT language model.
所以,作者研究了一种双流结构来分别建模每一种模态,然后将其通过一组基于 attention 的交互来融合这些信息。这种方法允许每一种模态的网络深度不同,确保了可以在不同的深度进行跨模态的联系。
如图 1 所示,ViLBERT 由两个 BERT-style 的模块构成,分别用于处理 image regions 和 text segments。每一个流的是一系列的 transformer blocks(TRM)和 novel co-attention transformer layers (Co-TRM),确保不同模态进行信息交换。给定图像 I,表示为一系列的 region features v1, ... , vT 以及 文本输入 w0, ... , wT,本文提出的模型输出最终的表示 hv0, ... , hvT 以及 hw0, ... , hwT。注意到两个流的交换被限制在特定的层,the text stream 明显在与视觉特征进行交互之前得到了更多的处理 --- 这样就和作者的直觉理解相匹配了,即:the chosen visual features are already fairly high-level and require limited context-aggregation compared to words in a sentence。
Co-Attentional Transformer Layers:
如图 2b 所示,作者引入了一个 co-attentional transformer layer,给定中间视觉和语言的表示,该模块计算 query,key,and value metrices 作为其他模态 多头注意力模块的输入。所以,注意力模块在产生 attention-pooled features 的时候,是依赖于其他模态的 --- 后续的 mimics common atteniton mechansims 是从其他 vision-and-language models 上得到的。剩下的 transformer 模块像之前一样,包含一个残差。总体来说,co-attention 对于 vision-and-language 来说并不是一个新的 idea。
Image Representation:利用物体检测网络得到 instance-level 的 object proposal。不像文本数据,图像中并不存在自然的序列。作者从空间位置的角度进行编码,构建一个 5-d 的向量。作者将图像中的区域序列开始的部分记为 IMG 来表示整个图像。
Training Tasks and Objectives:像之前章节描述的那样,作者考虑两个预训练的任务:masked multi-modal modelling and multi-modal alignment prediction.
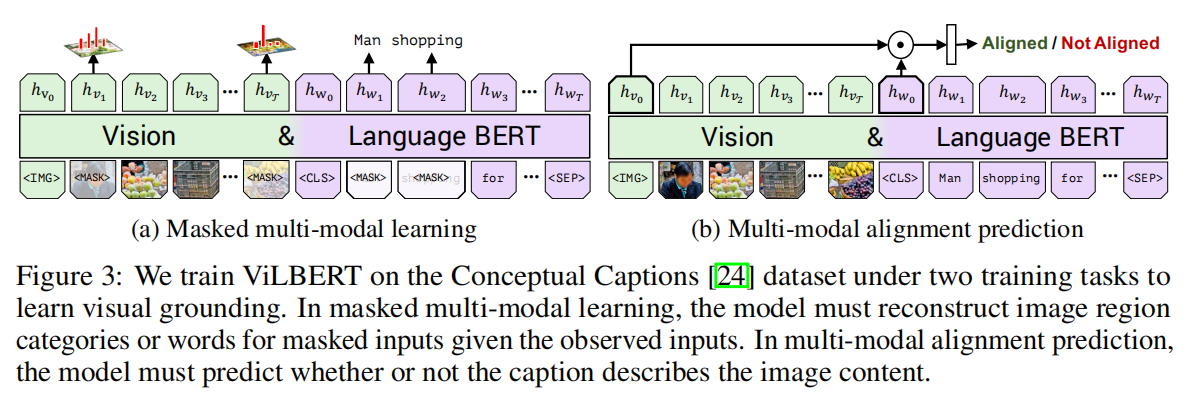
The masked multi-modal modelling task 跟标准的 BERT 训练方式一样 --- 大约遮挡 15% 的 word 和 image region inputs,然后用这个模型来重构这部分的内容。但是作者这里不是直接回归出 masked feature values,该模型是预测对应图像区域的语义类别的分布。为了在这部分利用监督信息,作者从同一个预训练的物体检测模型中获得该 region 的输出分布。利用这两个分布之间的 KL散度来训练该模型。这个选择反正了这么一个事实:自然语言经常被当做是视觉内容的高层语义表达,而不是用于重构确切的图像特征(the language often only identifies high-level semantics of visual content and is unlikely to be able to reconstruct exact image features)。此外,利用回归损失函数也会使得 masked image 和 text inputs 之间不平衡的损失。
在多模态对其任务中,模态被表示为一个 image-text pair {IMG, v1, ... , vT, CLS, w1, ... , wT, SEP} 然后去预测给定的图像和文本对是否匹配,即:给定的文本是否和图像的内容相符合。作者利用一个 linear layer 来进行二分类。然而,本文所用的数据集 Conceptual Captions dataset 仅仅包含对其的 image-caption pairs。为了产生负样本对,作者随机的替换对应的图像或者文本描述。
3. Experimental Results: