Perceptual Losses for Real-Time Style Transfer and Super-Resolution and Super-Resolution 论文笔记
ECCV 2016
摘要: 许多经典问题可以看做是 图像转换问题(image transformation tasks)。本文所提出的方法来解决的图像转换问题,是以监督训练的方式,训练一个前向传播的网络,利用的就是图像像素级之间的误差。这种方法在测试的时候非常有效,因为仅仅需要一次前向传播即可。但是,像素级的误差 没有捕获 输出和 gt 图像之间的 感知区别(perceptual differences)。
与此同时,最近的工作表明,高质量的图像可以通过 perceptual loss function 来生成,不依赖于像素之间的差别,而是 高层图像特征之间的差别。图像正是基于这种特征之间的 loss 进行训练的。这种方法可以产生高质量的图像,但是速度却很慢,因为需要解决一个优化问题。
本文中,我们将两者的优势进行结合,训练一个前向传播的网络进行图像转换的任务,但是不用 pixel-level loss function,而采用 perceptual loss function。在训练的过程中,感知误差 衡量了图像之间的相似性,在测试的时候可以实时的进行转换。
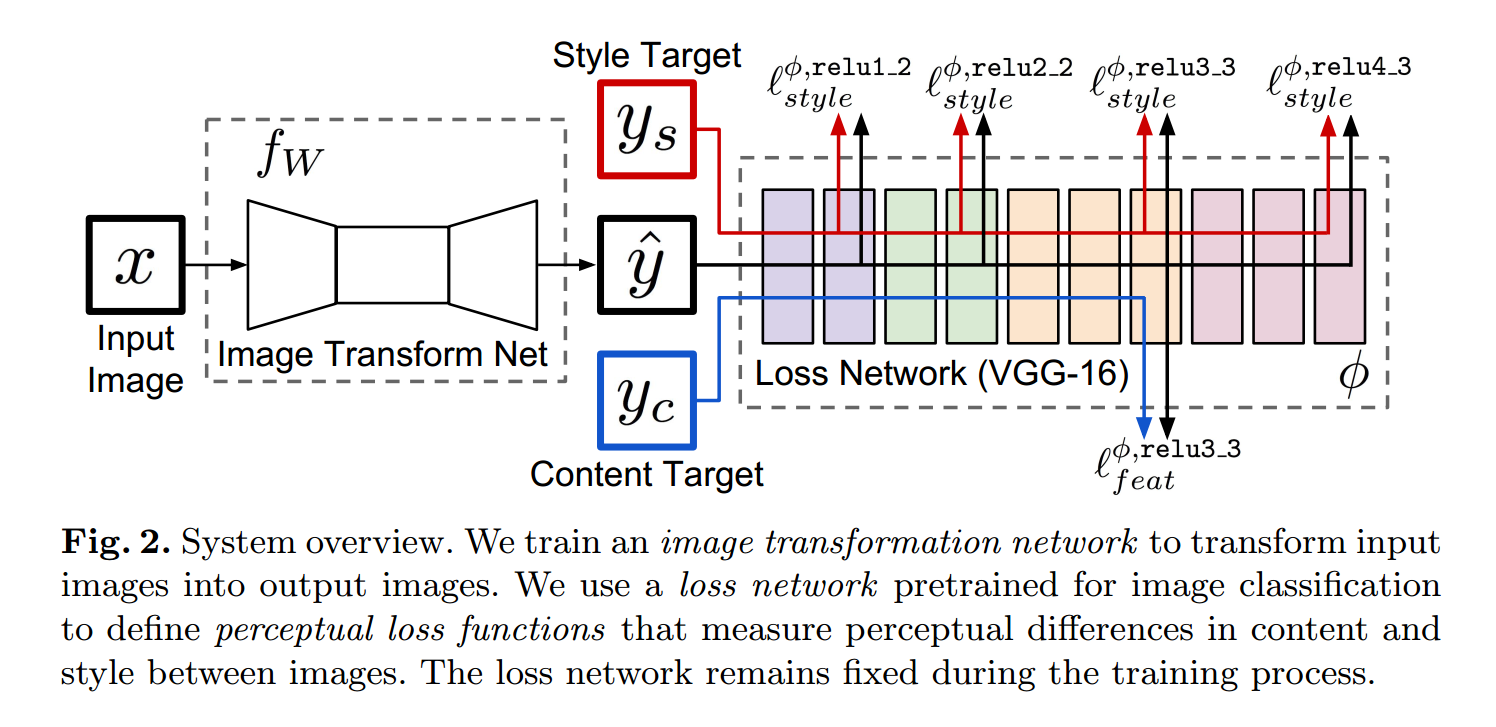
网络的训练:
网络主要由两个部分构成:一个是 image transformation network 一个是 loss network 用来定义 loss function。图像转换网络 是一个残差网络,它将输入图像转换为输出图像 y^。每个损失函数计算一个 scalar value 衡量输出图像和目标图像之间的不同。图像转换网络 是通过 SGD 进行训练的,利用加权的损失函数,如下所示:
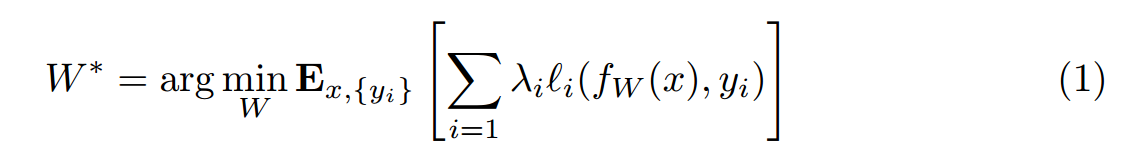
为了解决 per-pixel losses 的缺陷,并且允许我们的 loss function 可以更好的衡量 感知和语义的区别,我们从最近的通过优化来产生图像得到了启发。关键点在于:这些方法用到的网络已经是学习到编码感知和语义信息,这些网络都是在分类的数据集上进行训练后的。我们所以就用这些网络来固定的作为 loss network 来定义我们的损失函数。
刚开始看那个流程图的时候,比较糊涂的是两个 target,$y_c$ 和 $y_s$ 。其实是这样子的:
对于每一个图像 x ,我们有一个 content target $y_c$ 和 一个 style target $y_s$。
对于 style transfer 来说,the content target $y_c$ 是输入图像 x,the output image y^ 应该 结合 the content x = $y_c$ 和 $y_s$ 的 style 。
对于 超分辨来说,输入图像 x 是一个低分辨率的图像,the content target $y_c$ 是一个 gt 高分辨率的图像,style reconstruction loss 没有用到。对于一种超分辨的因子,我们就训练一种网络。
实验结果:
